抓取天猫网商品信息
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了抓取天猫网商品信息,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4179字,纯文字阅读大概需要6分钟。
内容图文

项目场景:
本文以天猫网和淘宝网为例介绍抓取数据的一般做法,利用requests库和BeautifulSoup库抓取淘宝网和天猫网的商品信息,进行数据采集,与利用Selenium库进行抓取做对比。
请求分析:
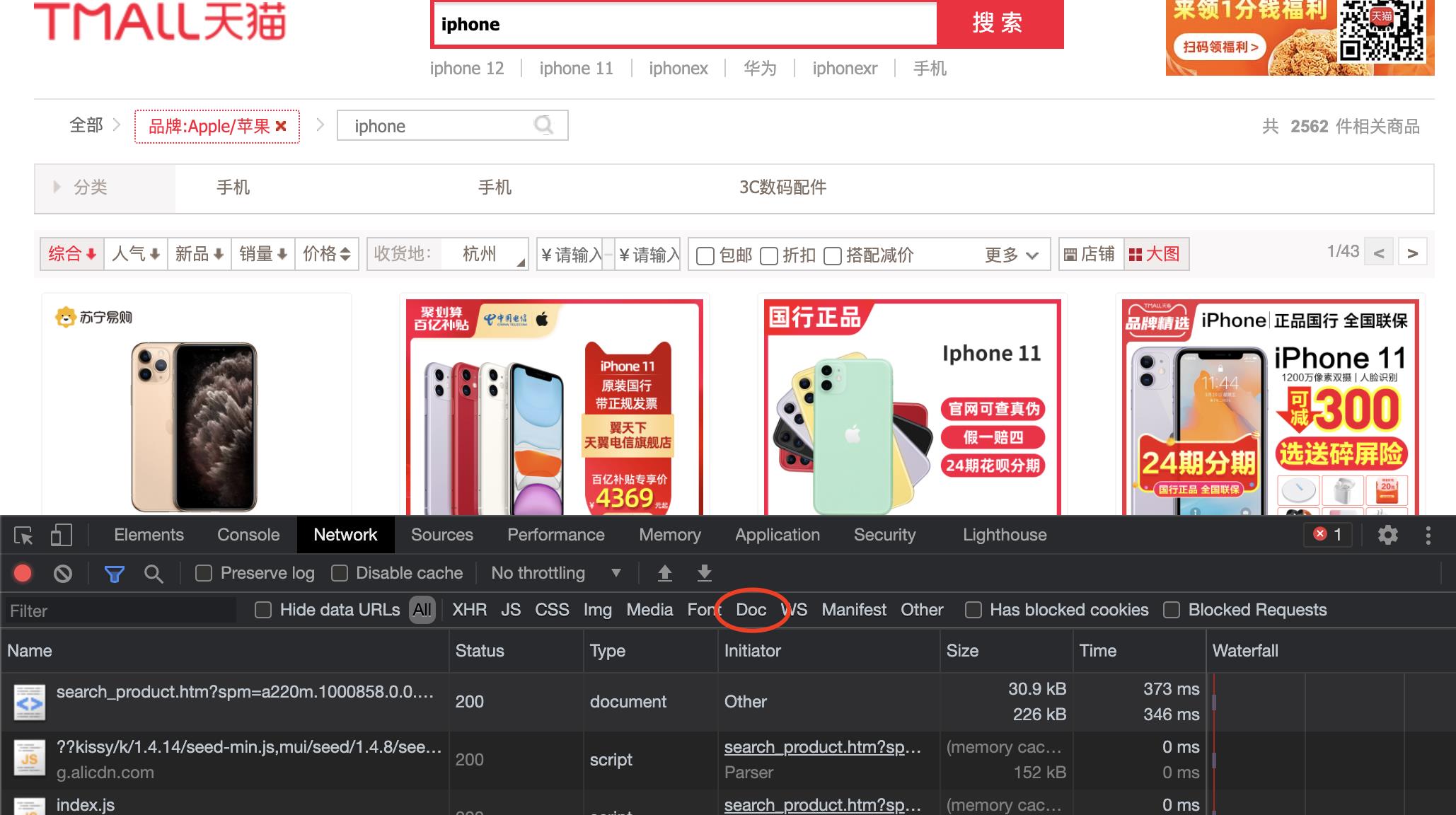
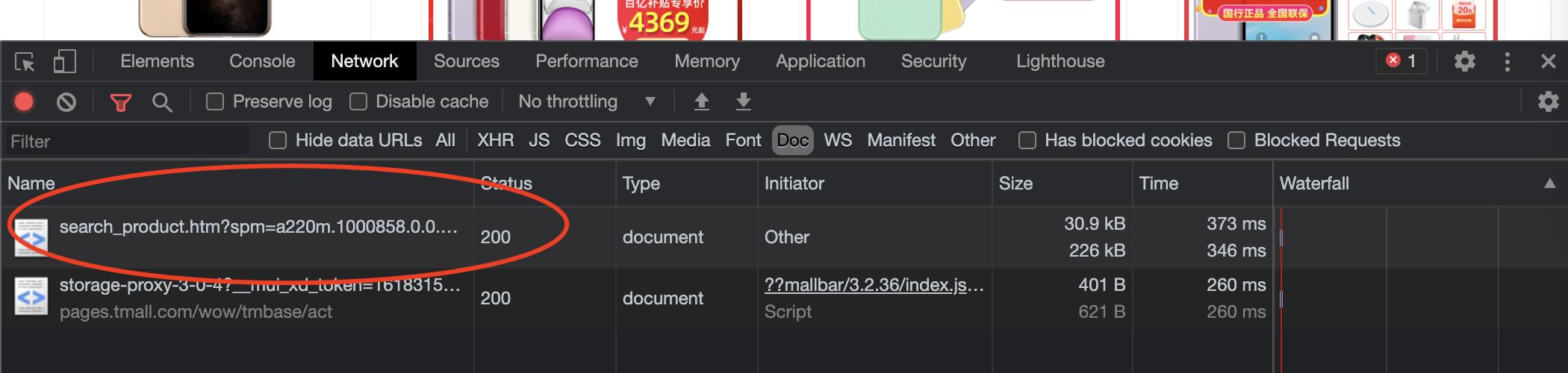
- 首先打开Google Chorme打开天猫网,搜索商品(以iphone为例),打开inspect页面,观察到NetWork选项卡下的Document类型文件,再点开Doc(图中红色圈),找我们需要的Doc;
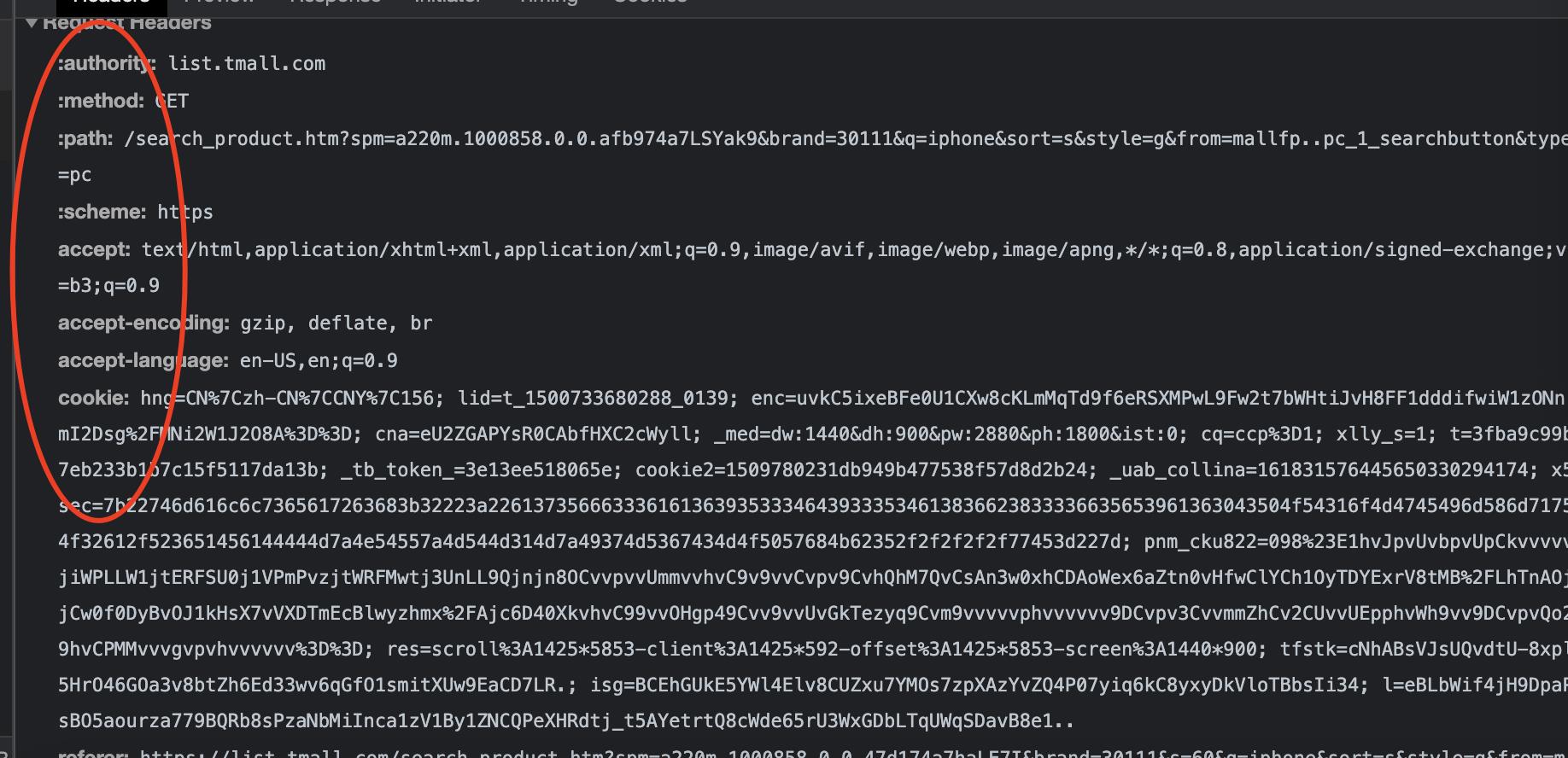
- 其次,在找到的Doc中找到浏览器请求的Headers,这里面有浏览器的请求属性,我们可以利用这些添加到requests请求的header变量中,起到反爬的作用;

代码如下(示例):
headers = {
'authority':'list.tmall.com',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie':'hng=CN%7Czh-CN%7CCNY%7C156; lid=t_1500733680288_0139; enc=uvkC5ixeBFe0U1CXw8cKLmMqTd9f6eRSXMPwL9Fw2t7bWHtiJvH8FF1dddifwiW1zONnmI2Dsg%2FMNi2W1J2O8A%3D%3D; cna=eU2ZGAPYsR0CAbfHXC2cWyll; _med=dw:1440&dh:900&pw:2880&ph:1800&ist:0; cq=ccp%3D1; xlly_s=1; t=3fba9c99b7eb233b1b7c15f5117da13b; _tb_token_=3e13ee518065e; cookie2=1509780231db949b477538f57d8d2b24; isg=BHl5Eq7nPR2rtOGXCN3xTpaQiONThm04JbNxW5uvz6CTIpm049emCUg7pC7UmgVw; l=eBLbWif4jH9DpQ_-BO5Churza77TeIOb4GVzaNbMiIncC64A6XJTyV-QDYtbqpKRJJXAtOLB4XAyoNp9-etf96HmndhHtBU2DYMDB; tfstk=cpePB0XcKv4bfhkC6YMeRPKOxsvRC82gpEoIZSjHvOsDyGAEPu50CenDgfcq1VBmZ; res=scroll%3A1425*5853-client%3A1425*474-offset%3A1425*5853-screen%3A1440*900; pnm_cku822=098%23E1hvp9vUvbpvUvCkvvvvvjiWPLLWQjnCRF5yzjrCPmPvgjEmRF5psjtUPszhQjE8RvhvCvvvvvvUvpCWmnTevvw%2FafFEDLKAWyVxI8oQ%2Bul08MoxfwpOdeghS47tIChB4Z7xfaCl5dUfbjc6YE7rV161iNLh1C%2BXwxzXS47BhC3qVUcnDOmOVb9Cvm9vvvvvphvvvvvv9DCvpvBdvvmmZhCv2CUvvUEpphvWlvvv9DCvpvQokvhvC99vvOHgp49Cvv9vvUvGkFdaAQvCvvOvUvvvphvRvpvhvv2MMTOCvvpvvUmm',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9',
'upgrade-insecure-requests': '1',
'referer':'https://www.tmall.com/',
}
url="https://list.tmall.com/search_product.htm?q=iphone&type=p&vmarket=&spm=875.7931836%2FB.a2227oh.d100&from=mallfp..pc_1_searchbutton"
import requests
from bs4 import BeautifulSoup
response = requests.get(url, headers=headers)
text=response.text#response.text的更多了解请看总结
soup=BeautifulSoup(text,'html.parser')
数据提取:
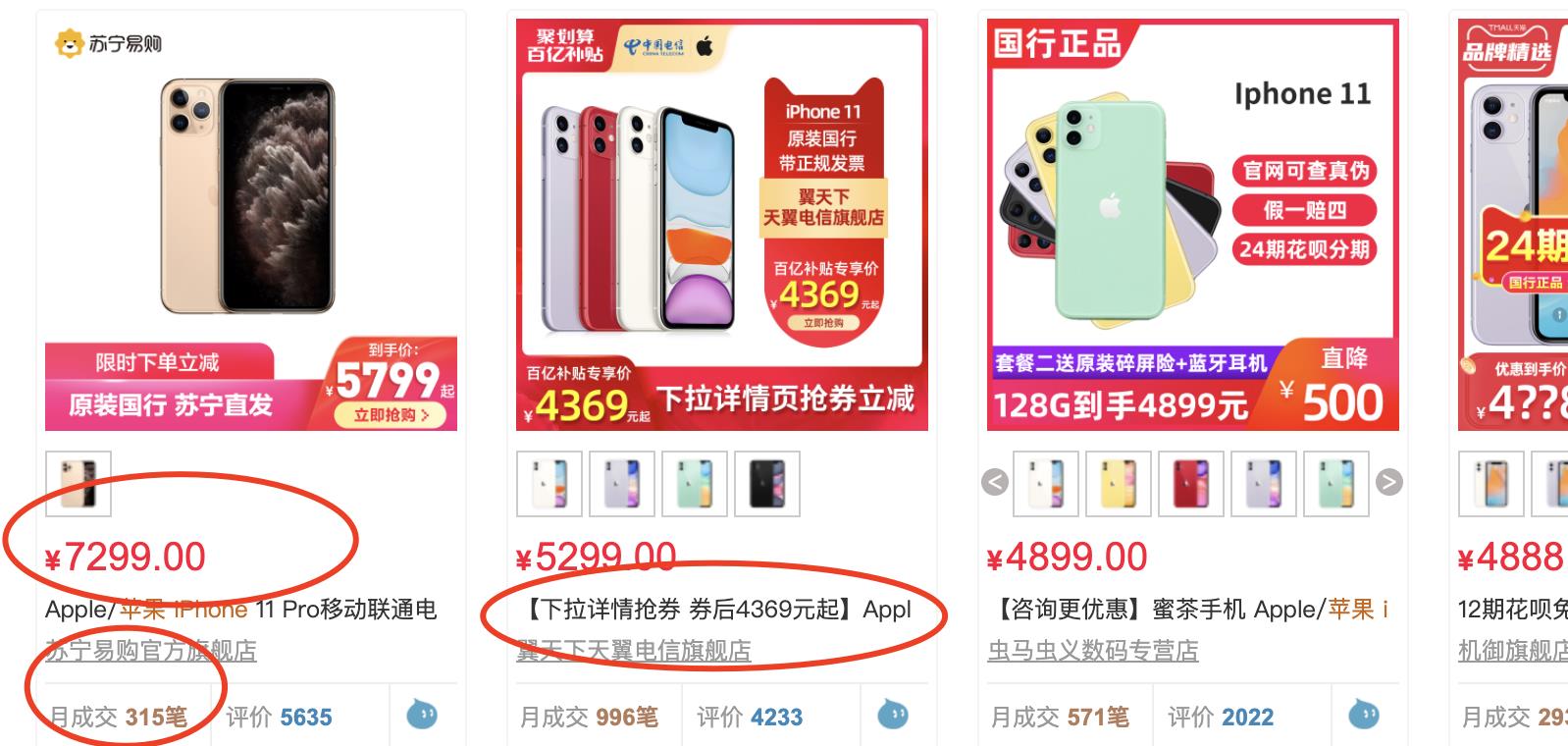
既然html已经获得了,并且已经成功解析,我们就可以进行数据提取了,我们以店铺的商品介绍为例进行提取;
#
for info in soup.find_all(
lambda tag: tag.has_attr('title') and tag.has_attr('data-p')):
if info.get('title') is not None:
print(info.get('title'))
#结果如下图所示

其他数据的提取大同小异(如价格,销量等等),这里给出代码,不再赘述,读者可以参考;
#提取价格
for price in soup.find_all("p", attrs={"class": "productPrice"}):
print(price.find('em').text)
#提取销量
for staus in soup.find_all("p", attrs={"class": "productStatus"}):
print(staus.find('span').text)
#提取店铺名称
for name in soup.find_all("a", attrs={"class": "productShop-name"}):
print(name.text,end='')
整体代码如下(headers和url自行选择):
import requests
from bs4 import BeautifulSoup
response = requests.get(url, headers=headers)
soup=BeautifulSoup(response.text,'html.parser')
for info in soup.find_all(lambda tag: tag.has_attr('title') and tag.has_attr('data-p')):
if info.get('title') is not None:
print(info.get('title'))
for price in soup.find_all("p", attrs={"class": "productPrice"}):
print(price.find('em').text)
for staus in soup.find_all("p", attrs={"class": "productStatus"}):
print(staus.find('span').text)
for name in soup.find_all("a", attrs={"class": "productShop-name"}):
print(name.text,end='')
总结:
- requests.Response是利用requests发送HTTP请求之后返回的对象,它具有多个属性,我们这里用到response.text用于获得它的文本,这个属性十分高级,虽然它的编码方式为unicode,但是我们不用更换编码也可以获得想要的文本,这是因为它依据html中的‘charset’自动进行选择,更多了解请看requests库官方文档;

- 文中用到BeautifulSoup对象的find_all方法,并传入lambda函数进行筛选,lambda函数只是一种选择器,除此之外还有标签(如’a’),一个标签列表(如[‘a’,‘b’])和正则表达式,更多了解请看BeautifulSoup官方文档;

- 此文是抓取天猫网数据,淘宝网也可以类比参考,大同小异,但在数据提取时候出现编码问题,大家可以自行尝试解决;
内容总结
以上是互联网集市为您收集整理的抓取天猫网商品信息全部内容,希望文章能够帮你解决抓取天猫网商品信息所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】