首页 / 更多教程 / RDD练习:词频统计
RDD练习:词频统计
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了RDD练习:词频统计,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2122字,纯文字阅读大概需要4分钟。
内容图文

一、词频统计:
1.读文本文件生成RDD lines
2.将一行一行的文本分割成单词 words flatmap()
3.全部转换为小写 lower()
4.去掉长度小于3的单词 filter()
5.去掉停用词
6.转换成键值对 map()
7.统计词频 reduceByKey()
二、学生课程分数 groupByKey()
-- 按课程汇总全总学生和分数
1. 分解出字段 map()
2. 生成键值对 map()
3. 按键分组
4. 输出汇总结果
三、学生课程分数 reduceByKey()
-- 每门课程的选修人数
-- 每个学生的选修课程数
1.读文本文件生成RDD lines
lines = sc.textFile('file:///home/hadoop/word.txt')
lines.collect()

2.将一行一行的文本分割成单词 words
words=lines.flatMap(lambda line:line.split())
words.collect()

3.全部转换为小写
words=lines.flatMap(lambda line:line.lower().split())
words.collect()

4.去掉长度小于3的单词
words=lines.flatMap(lambda line:line.split()).filter(lambda line:len(line)>3)
words.collect()

5.去掉停用词
1.准备停用词文本:
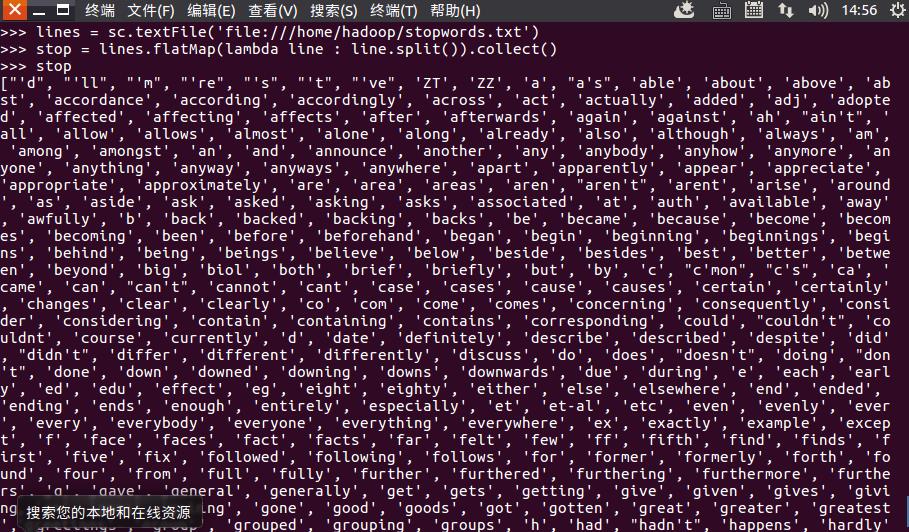
lines = sc.textFile('file:///home/hadoop/stopwords.txt')
stop = lines.flatMap(lambda line : line.split()).collect()
stop
2.去除停用词:
lines=sc.textFile("file:///home/hadoop/word.txt")
words=lines.flatMap(lambda line:line.lower().split()).filter(lambda word:word not in stop)
words
words.collect()

6.转换成键值对 map()
wordskv=words.map(lambda word:(word.lower(),1))
wordskv.collect()

7.统计词频 reduceByKey()
wordskv.reduceByKey(lambda a,b:a+b).collect()

二、学生课程分数 groupByKey()
-- 按课程汇总全总学生和分数
1. 分解出字段 map()
2. 生成键值对 map()
3. 按键分组
4. 输出汇总结果
1.读大学计算机系的成绩数据集生成RDD
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
lines.take(6)

2.按科目汇总学生和分数
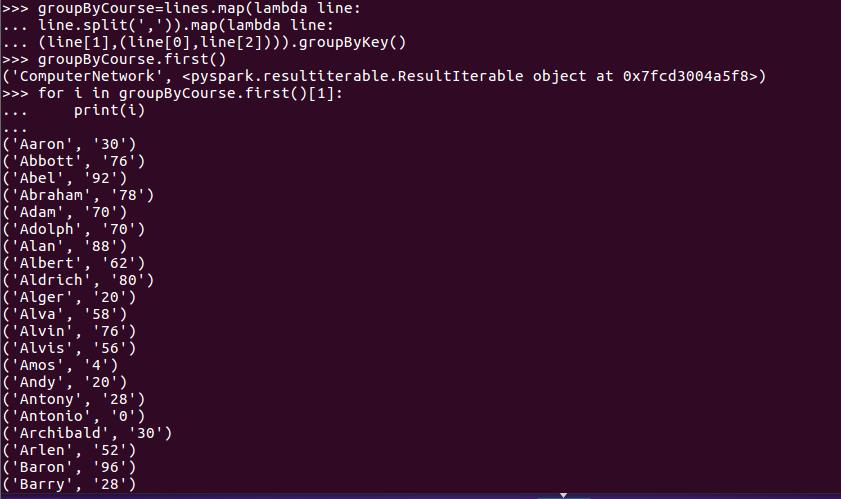
groupByCourse=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],(line[0],line[2]))).groupByKey()
groupByCourse.first()
for i in groupByCourse.first()[1]:
... print(i)
三、学生课程分数 reduceByKey()
-- 每门课程的选修人数
lines=sc.textFile('file:///home/hadoop/chapter4-data01.txt')
reduceByClass=lines.map(lambda line:line.split(',')). map(lambda line:(line[1],1))
reduceByClass.reduceByKey(lambda a,b:a+b).collect()

-- 每个学生的选修课程数
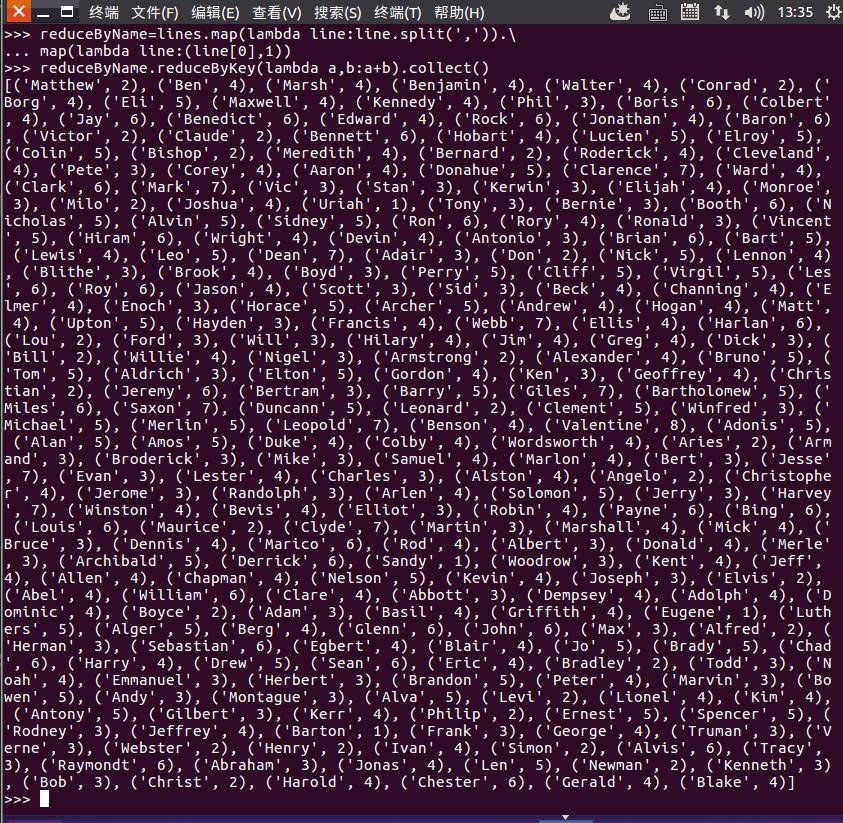
reduceByName=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],1))
reduceByName.reduceByKey(lambda a,b:a+b).collect()
内容总结
以上是互联网集市为您收集整理的RDD练习:词频统计全部内容,希望文章能够帮你解决RDD练习:词频统计所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。