PyTorch 神经网络学习(官方教程中文版)(一、利用Pytorch搭建神经网络)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了PyTorch 神经网络学习(官方教程中文版)(一、利用Pytorch搭建神经网络),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3081字,纯文字阅读大概需要5分钟。
内容图文
(一、利用Pytorch搭建神经网络)")
利用Pytorch搭建神经网络
在完成李宏毅2020机器学习图像分类(hw3)时,需要具备会使用pytorch的能力,通过pytorch的官方教程进行学习https://pytorch123.com/
训练神经网络的步骤如下:

1.定义神经网络(普通CNN为例)
这里的size = x.size()[1:]有点理解不太清楚。理解如下:以32*32的数据输入,经conv1后得到6*32*32→maxpool1(6*16*16)→conv2(16*16*16)→maxpool2(16*8*8),size = x.size()[1:]取得是8*8,那么num_flat_features返回的便是64,经过
x = x.view(-1, self.num_flat_features(x))后得到的x应为16*64,并没有展开成一维数据。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 一个图片输入通道,6个输出通道,即共6个卷积核,卷积核为5*5,若是正方形,只写5即可
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接神经网络需要训练的权重,共三层,400(卷积得到得到的)→120→84→10
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling 为2*2,同样若是正方形,只写2即可
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# -1是指根据self.num_flat_features(x)的值自动算出的
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
输出如下:
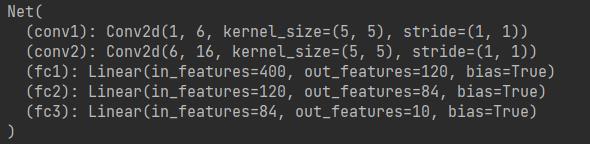
一个模型可训练的参数可以通过调用 net.parameters() 返回,
params = list(net.parameters()) # 一个模型可训练的参数可以通过调用 net.parameters() 返回: print(len(params)) print(params[0].size())
共10个参数,依次输出每个参数的尺寸,第一个和第三个为所用卷积核的参数,第五、七、九为神经网络间的参数,其他一维的参数应该是bias,如下所示:

2.通过神经网络输入
让我们尝试随机生成一个 32x32 的输入。
input = torch.randn(1, 1, 32, 32) output = net(input) print(output)
得到的结果为:

3.计算损失
一个损失函数需要一对输入:模型输出和目标,然后计算一个值来评估输出距离目标有多远。有一些不同的损失函数在 nn 包中。一个简单的损失函数就是 nn.MSELoss ,这计算了均方误差。分类问题多用交叉熵nn.CrossEntropyLoss()
target = torch.randn(10) # 给予标签随机值 target = target.view(1, -1) # 保证标签与预测值同尺寸 criterion = nn.MSELoss() loss = criterion(output, target) print(loss)
结果:
Autograd与计算图的原理见:https://blog.csdn.net/joseph__lagrange/article/details/109339878
4.反向传播
为了实现反向传播损失,我们所有需要做的事情仅仅是使用 loss.backward()。你需要清空现存的梯度,要不然将会和现存的梯度累计到一起。这也是loss的作用,现在我们调用 loss.backward() ,然后看一下 con1 的偏置项在反向传播之前和之后的变化。
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
结果如下:

5.参数更新
普通梯度更新:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate
SGD:
import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=0.01) optimizer.zero_grad() # 置零 output = net(input) loss = criterion(output, target) loss.backward() optimizer.step()
内容总结
以上是互联网集市为您收集整理的PyTorch 神经网络学习(官方教程中文版)(一、利用Pytorch搭建神经网络)全部内容,希望文章能够帮你解决PyTorch 神经网络学习(官方教程中文版)(一、利用Pytorch搭建神经网络)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。