OO第一单元总结
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了OO第一单元总结,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含10552字,纯文字阅读大概需要16分钟。
内容图文

OO第一单元总结
第一次作业
1.程序设计
第一次作业只涉及幂函数的加、减、乘运算,没有表达式的嵌套,输入的字符串也保证格式正确,因此输入解析规则比较简单。对表达式的解析我采用了如下思路:
-
预处理:先读入字符串,对字符串进行预处理,预处理内容包括
-
删除空白字符,包括空格和制表符
\t -
合并重复的
+-符号,再将单个-的符号替换成+-符号,此时的+用于split使用 -
将
**替换为^,再删除*和^后接的+
-
-
解析表达式
Expression:预处理后的字符串每一项之间都有+符号,而项内则不存在+,因此以+符号为regex对预处理后的字符串进行split,得到一个数组,数组装有表达式的所有项 -
解析项
Term: 由于预处理部分将**替换成了^,因此可以采用解析表达式的方法,以*为regex对每一项Term进行split, 得到一个数组,数组装有项的所有因子 -
解析因子
Element: 第一次作业中,因子可能的情况较少,因此我将因子分为三种情况进行解析:-
整数:直接转化为
BigInteger,如:0029,-12383 -
幂函数:将
^后的指数转化为BigInteger,如:x^-001,-x^931 -
省略形式的幂函数:没有
^,指数为1
-
-
合并:合并工作分为因子合并与项合并两方面:
-
因子合并:项的所有因子指数相加,系数相乘
-
项合并:表达式的所有项,指数相同者系数相加
-
-
求导:运用高数知识对表达式的所有项分别求导后相加即可
-
排序:为了使输出的字符串长度尽可能短,我采用了
Comparator接口,所有项按系数大小降序排列,最大程度上减少了一个符号+的长度 -
输出:所有类创建一个
toString方法,解析成字符串后直接输出
2.程序分析
-
复杂度分析
-
方法复杂度如下图
-

-
- 类复杂度如下图:
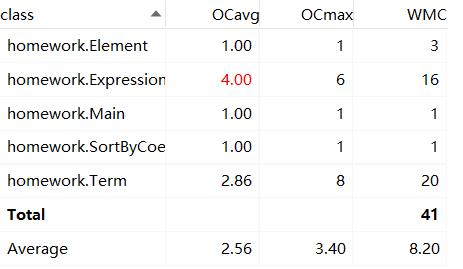
-
- 复杂度分析:本次作业的复杂度主要在于Term类的
printOut方法,为了使输出尽可能简短,分7种情况使用if-else语句判断幂函数的系数和指数是否等于±1。
- 复杂度分析:本次作业的复杂度主要在于Term类的
-
UML图:
各类和重要方法的实现在程序设计部分已给出,这里直接给出UML图。
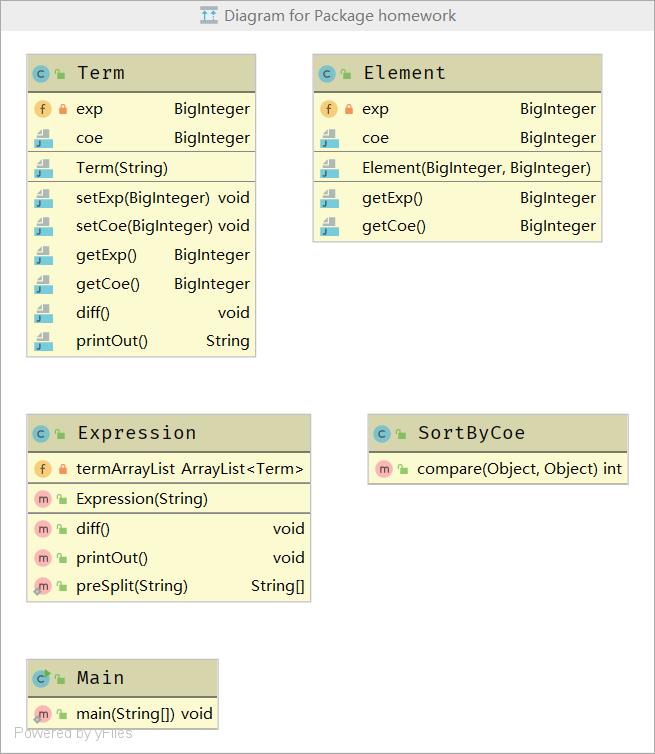
由于第一次作业情况比较简单,
程序架构从外观看上去还像点面向对象,但具体实现十分的面向过程。设计和风格上的缺陷主要有:-
对象层次不清晰:直接在表达式类的创建中实现了项类的创建和因子类的创建,而没有分别在项类和因子类中去实现创建方法,导致代码的可移植性低
-
方法没分块:为了偷懒,直接在表达式类的创建中实现了项与因子合并,而没有单独写一个方法用于合并,类似于c语言里一个int main()干到底
-
代码臃肿:因对循环语句还不够熟练,在实现合并符号的方法里我采用了穷举法,使得代码臃肿,不雅观
public static String[] preSplit(String preExpression) { String splited = preExpression.replace("\t", ""); splited = splited.replace(" ", ""); splited = splited.replace("**", "^"); splited = splited.replace("+++", "+"); splited = splited.replace("++-", "-"); splited = splited.replace("+-+", "-"); splited = splited.replace("+--", "+"); splited = splited.replace("-++", "-"); splited = splited.replace("-+-", "+"); splited = splited.replace("--+", "+"); splited = splited.replace("---", "-"); splited = splited.replace("++", "+"); splited = splited.replace("+-", "-"); splited = splited.replace("-+", "-"); splited = splited.replace("--", "+"); splited = splited.replace("-", "+-"); splited = splited.replace("*+", "*"); splited = splited.replace("^+", "^"); if (splited.substring(0, 1).equals("+")) { splited = splited.substring(1, splited.length()); } return splited.split("(\\+)+"); }
-
3.Bug分析
第一次作业中,强侧和互测均没有出现bug。互测中成功hack了2人,且这2人的bug都是同一个原因:没有考虑到三个 +- 符号连在一起的情况。
第二次作业
1.程序设计
从第一次作业到第二次作业,堪比从单周期到流水线,由于第一次作业设计上的缺陷,导致第二次作业不得不重构。加上三角函数和嵌套法则之后,表达式的建立就是一个多叉树建立的过程,整个程序的处理流程大致如下:
-
预处理(同第一次作业)
-
解析表达式
Expression:-
表达式类中有五个容器:
private ArrayList<Power> powerArrayList; private ArrayList<Cos> cosArrayList; private ArrayList<Sin> sinArrayList; private ArrayList<Term> termArrayList; private ArrayList<Expression> expressionArrayList;
-
去括号:若整个表达式是嵌套在括号里,则循环删除两侧括号
-
寻找分离标记
+:利用类似于数据结构的后缀表达式方法,将不嵌套在括号内的+用于标记 -
根据标记下标进行分离,分离得到的字符串在进行去括号和去负号的处理,如下情况则需要去除括号外的负号
-(x**2+3-x+(sin(x)-2))
将处理后得到的字符串解析,判断所属类型,根据所属类型新建一个对象:
-
若为
Expression,则新建Expression类的对象 -
若为
Term,则新建Term类的对象 -
若为
Power,则新建Power类的对象 -
若为
Sin,则新建Sin类的对象 -
若为
Cos,则新建Cos类的对象
-
-
-
解析项
Term: 此类中也有五个容器,且处理方法与解析表达式基本一致,不同之处在于寻找的分离标记是不嵌套在括号内的*。private ArrayList<Cos> cosArrayList; private ArrayList<Sin> sinArrayList; private ArrayList<Power> powerArrayList; private ArrayList<Expression> expressionArrayList; private ArrayList<Term> termArrayList;
-
解析幂函数
Power:与第一次作业处理方式一致。 -
解析正弦函数
Sin和余弦函数Cos:与解析幂函数方法一致,不同之处在于幂函数底数为x而正弦函数底数为sin(x),余弦函数底数为cos(x)。 -
简化
simplify:从上述代码中可见,在表达式Expression类和项Term类中,都分别含有一个容器装入“自己”。由于设计问题,可能会出现输入((((x)))))而解析出四个Expression类嵌套的情况,而此简化方法就是去除Expression类的嵌套关系,将最后一个Expression对象中的Power对象装入最外层Expression类的容器中。Term类的嵌套处理方法也如此。 -
合并
merge:-
表达式合并:表达式类的
cosArrayList、sinArrayList、powerArrayList容器分别进行加法合并,由于termArrayList本身是一个含有五个容器的对象,因此无法进行合并。由于简化处理,使得最外层的表达式对象expressionArrayList容器为空,因此无需合并。 -
项合并:项类的
cosArrayList、sinArrayList、powerArrayList容器分别进行乘法合并,由于expressionArrayList本身是一个含有五个容器的对象,因此无法进行合并。由于简化处理,使得最外层的项对象termArrayList容器为空,因此无需合并。
-
-
去分层
cutPile:在解析输入字符串时可能会出现这样的情况:一个Expression对象中装有一个Term对象,而这个Term对象中只装有一个表达式或其他因子类,这时可以去除Term这层,将其含有的对象加入外层Expression中,从而去除分支,简化多叉树分层关系。Term类的处理机制也同理。 -
求导:通过高数知识进行求导即可,最大的难点在于对Term的求导,针对此问题,我没有采用递归式的求导方式,而是利用了乘法求导的推论进行求导。
-
输出:所有类创建一个
toString方法,解析成字符串后直接输出
2.程序分析
-
复杂度分析:
-
复杂度较大的方法情况如下:
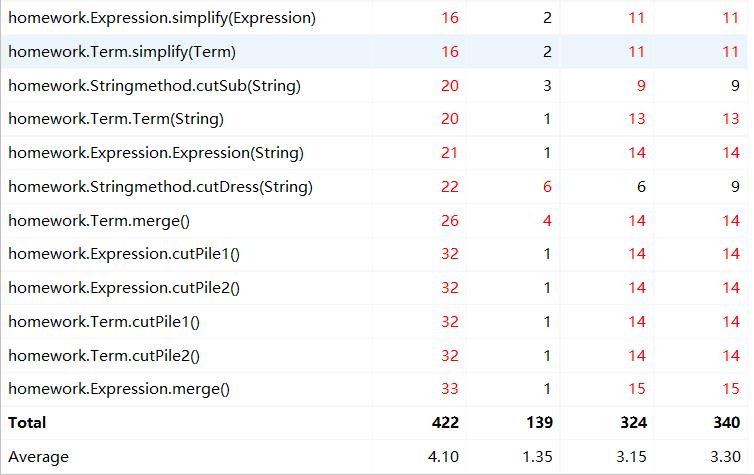
-
类复杂度:
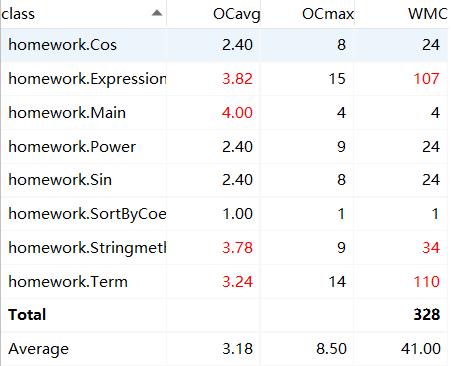
-
复杂度分析:本次作业复杂度主要在于优化部分,因为建立的是多叉树,要减小树的深度和简化树的层次结构,需递归遍历至树的最底部,且由于设计不佳,类之间存在嵌套关系,导致复杂度较大。
-
-
UML图:
各类和重要方法的实现在程序设计部分已给出,这里直接给出UML图。
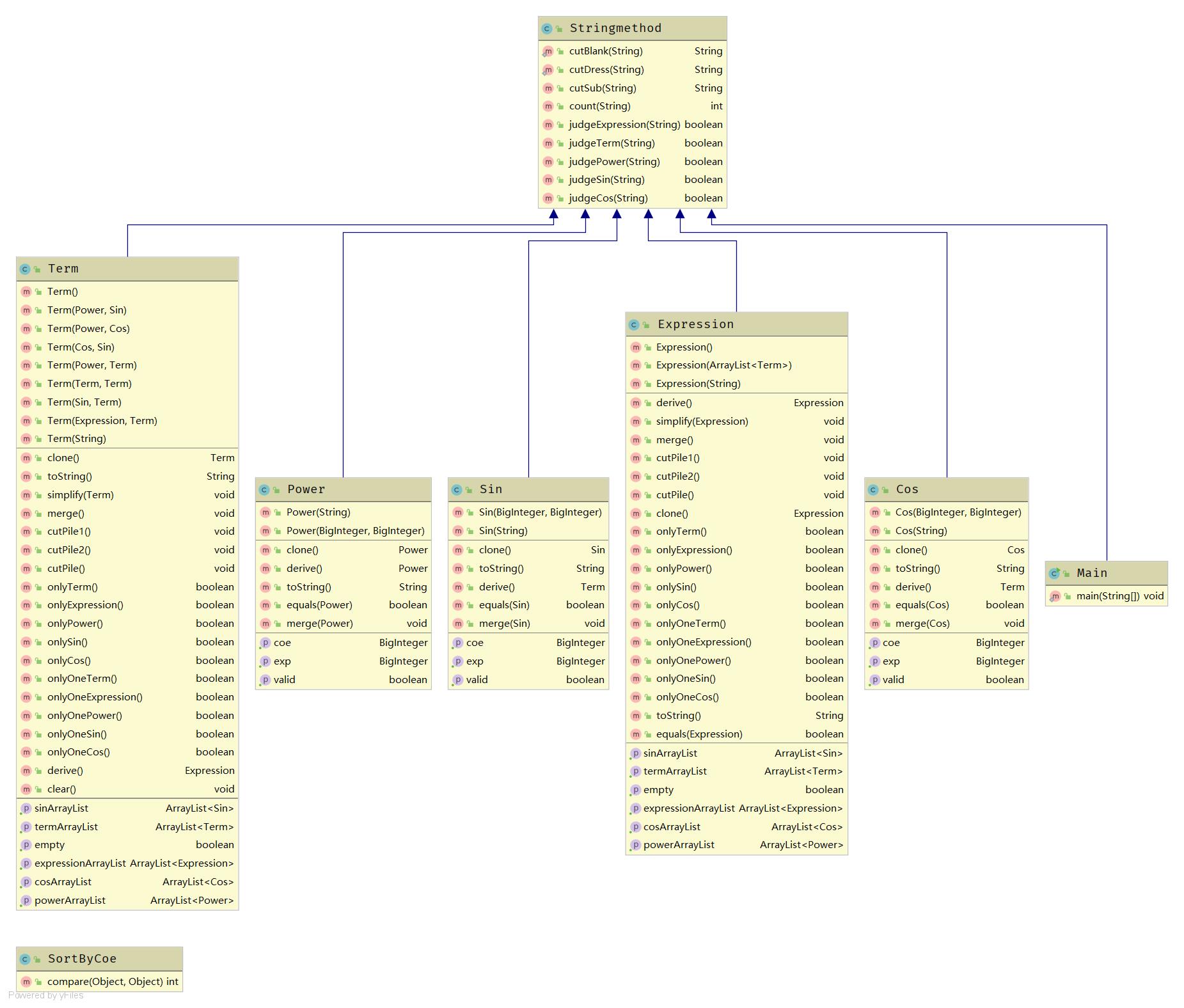
相比于第一次的设计,此次设计优点主要体现在移植性增强,即使再增加一个解析
sin(x**2)**2与(x-cos(x))**2的需求,也可以在源代码较少的改动下实现。而设计和风格上的主要缺陷有:-
封装性不强:虽然每个类的成员都是private,但都因程序设计所需不得不添加get方法(并非无脑生成),导致类之间成员属性可见,与public并无本质区别,封装性差。
-
高耦合,低内聚:由于设计上的缺陷,所有类都需要共用自行设计的字符串处理方法,因此单独开了一个字符串处理类
Stringmethod使所有其它类去继承,导致不同类之间耦合度高,封装性差、结构混乱。 -
类关系混乱:
-
继承关系:
-
表达式类Expression和项类Term在数学上都属于四则运算类,且两者的成员也完全相同,方法处理思想也基本一致,因此完全可以建立一个父类以提取出两者相同之处。
-
三角函数和幂函数类在题目规则下都是因子,因此可以建立一个父类Factor,使程序的类图关系更清晰。
-
-
嵌套关系:因输入存在表达式的嵌套,解析的表达式也无可避免的存在表达式和项之间的嵌套关系。但由于此程序设计本身的缺陷,表达式和表达式之间、项与项之间也存在嵌套关系,导致生成的多叉树层次关系复杂,也直接导致
simplify优化方法的出现。
-
-
命名不规范:
-
变量命名不规范:如tem、cutExp等,难以做到”望文生义“,可读性差。
-
方法命名不规范:如cutDress、cutBlank、cutPile等,也难以做到”望文生义“。
-
-
3.Bug分析
强测中被找出1个bug,互测中被别人hack了4次。但这5个bug都是同质bug:由于解析Term时没有对“+”和“*”递归去除,导致在 + 和 * 同时出现时会出现解析错误。这个bug出现的原因是程序设计耦合度高内聚度低导致的层次混乱不清晰。
互测中成功hack了别人1次,测试样例是互测前自行构造的自测样例,出错原因是出现了如 x*-x 的错误格式,从其代码可以看出,在设计时没有专门开一个常数 constant 类,因子类里面含有成员系数,致使toString过程中出现问题。
第三次作业
1.程序设计
本次作业要求主要分为两部分:一是实现三角函数括号内带因子的解析,二是判断输入字符串的合法性。
-
三角函数带因子:
由于第二次作业的设计架构可移植性还算健全,针对这个要求也并没有太多的重构,主要是在三角函数类的成员上加入了表达式这个成员变量:
添加前的成员为:
private BigInteger coe;
private BigInteger exp;添加后的成员为:
private BigInteger coe;
private BigInteger exp;
private Expression expression;针对这一改变,主要在求导方法里稍作改动即可,程序架构并没有太大的改动。
-
判断输入合法性:
这个要求是这次作业里最棘手的问题了,由于先前的设计没有使用正则表达式或递归下降,而是在确保输入合法的前提下先进行预处理,再对解析字符串。为此,我的设计思想是:先雇一个程序员判断合法性,再雇一个程序员解析字符串。实现思路大致为:在预处理前,先对字符串进行“预处理内容”的合法性检查(如:空白字符是否合法,符号是否规范等),若有错误则抛出异常;否则对字符串进行预处理,再进行解析,在解析过程中再度判断合法性。这种思路的好处在于分块明确、好调试,而缺陷在于增加了不必要的代码量,且面向过程。
预处理前判断合法性的主要方法有:
-
symbolCorrect:判断符号是否合法,是否出现四个及以上的符号叠加,是否出现字符^等。 -
multCorrect:判断项之间的整数是否与符号之间存在空白字符。 -
blankCorrect:判断**之间是否有空白字符,判断sin和cos内是否有空白字符等。 -
dressCorrect:判断括号匹配是否合法。
预处理后进行解析时,逐字符解析判断合法性即可,但要注意的是,还需判断指数绝对值是否大于50。
-
2.程序分析
-
复杂度分析:
-
方法复杂度:
复杂度较大的方法如下:
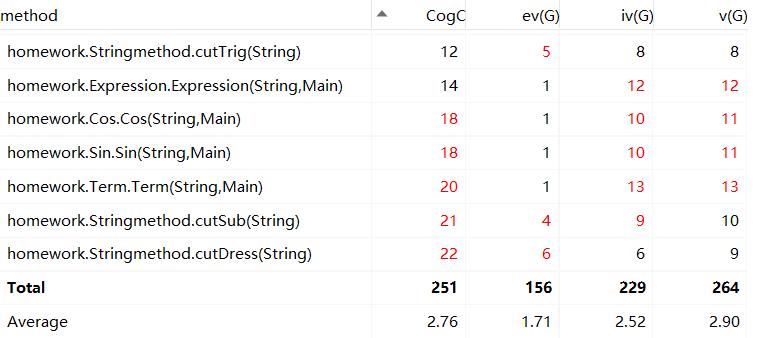
-
类复杂度:
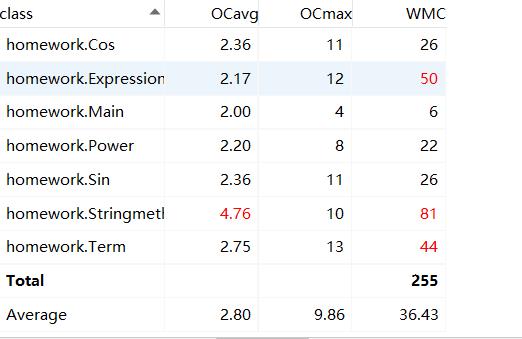
-
复杂度分析:由于此次作业删去了优化方法,因此复杂度方面与第二次作业基本一致。当然,如果能对类之间的耦合度进行优化,使类之间的关系更加清晰,还是能有效地降低此复杂度,下一阶段的练习中我会更加重视这点。
-
-
UML图:
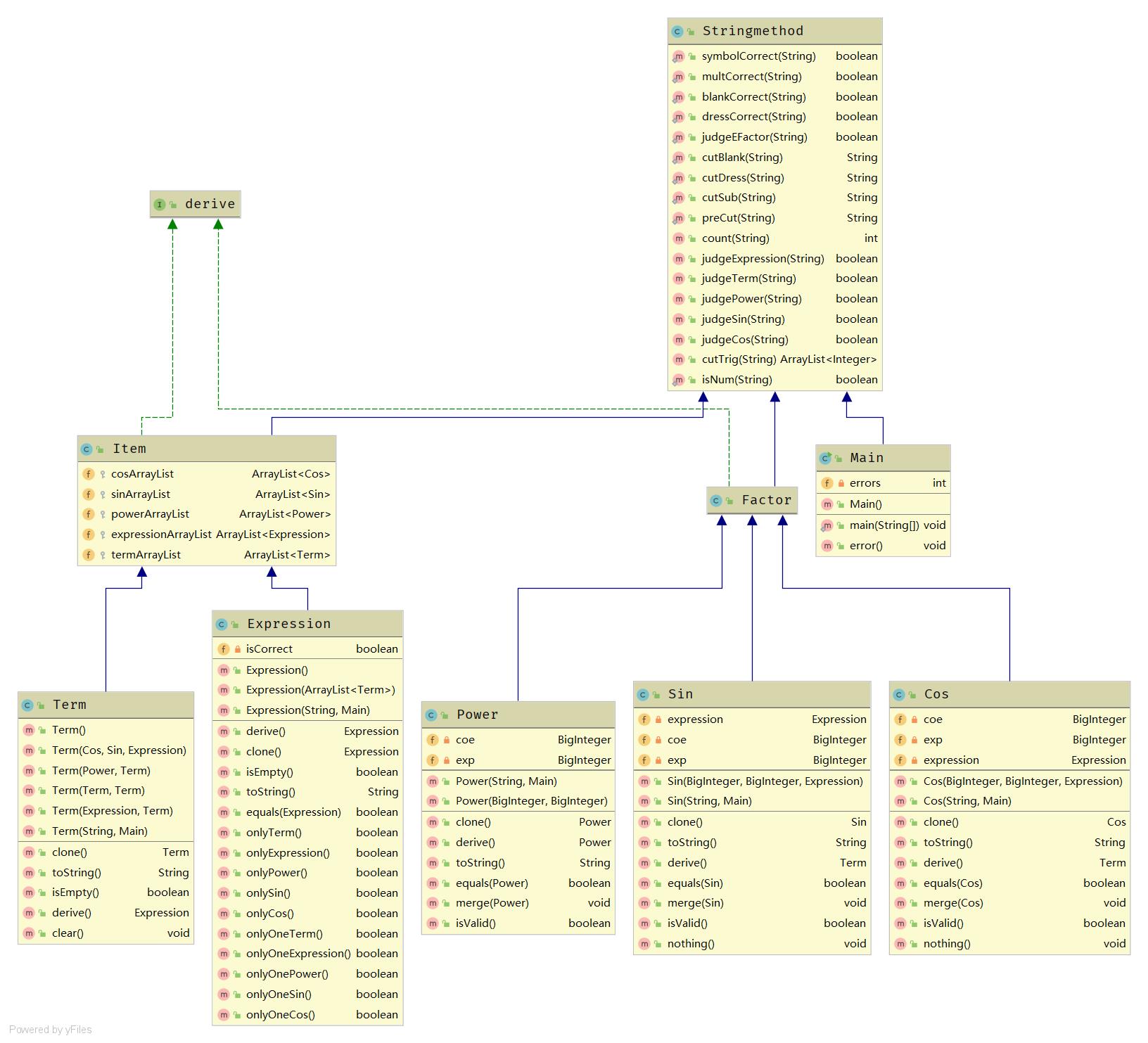
因为homework3与homework2在架构、类和方法的实现上基本无差,程序在设计和风格上的的主要缺陷在homework2里也已提到,在此不再赘述。
3.Bug分析
强测中被找出1个bug,而互测由于输入必须非法的原因,没有被找出bug,同时也没有hack别人。出现bug的原因在于没有考虑到如 sin(+ 2) 这种三角函数里因子的合法性。这也是我设计上的缺陷,没有创建一个 constant 常数类,而是将常数归并到幂函数(指数为0的情况),才会导致带符号整数的合法性判断错误。
重构经历
由于偷懒我只从homework1到homework2进行了一次重构,而这次重构我认为更像是计组里的从单周期到流水线的构造。homework1的架构只能实现幂函数的加减乘功能,而homework2的架构则需要实现能够支持幂函数、三角函数、表达式嵌套的加减乘运算,这个架构在将来也还要能支持指数、对数、除法、更深入判断输入合法性(如 sin(0)**-1 不合法)等功能。能搭建一个在较少的改动下实现更多功能的架构,才是这三次作业的最终目标。
心得体会
通过寒假的pre训练,我只是熟悉了一下java的基本语法和OO的核心思想。但通过这三次作业的迭代开发,我才在重构中真正感悟到OO的核心思想。尤其是从homework1到homework2,我深入感受到java中类的作用和方法分块的重要性。在编写类和方法时,要遵循各司其职的原则,降低耦合度、提高内聚性,以更好地实现类的封装性,我认为这是面向对象思想最为典型的体现。OO课程已过四分之一,在接下来的三个单元我会保持投入充足的时间去实践和感受,提高自己的面向对象思维。
内容总结
以上是互联网集市为您收集整理的OO第一单元总结全部内容,希望文章能够帮你解决OO第一单元总结所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。