首页 / HADOOP / hadoop伪分布式集群搭建
hadoop伪分布式集群搭建
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了hadoop伪分布式集群搭建,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含8352字,纯文字阅读大概需要12分钟。
内容图文

本文步骤较多,请细心查看。
基础设施
基础设施环境如下:
- jdk 1.7+(提前设置好环境变量)
- ssh自己和自己之间进行免密登陆,如在layne1上执行
ssh layne1 - 时间同步
- 设置本机ip
- 设置主机名
可参考Linux切换运行级别、关闭防火墙、禁用selinux、关闭sshd、时间同步、修改时区、拍摄快照、克隆操作、修改语言环境。
另外,不得不提Linux系统远程执行和远程登陆的区别:
- 远程执行:不需要用户交互,而是用户直接给出一个命令,直接在远程执行,不会加载
/etc/profile - 远程登陆:返回一个交互接口,返回接口
/bash会加载/etc/profile
操作步骤
我在主机名为layne1上搭建hadoop伪分布式集群,详细步骤如下
1、配置免密钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub > ~/.ssh/authorized_keys
id_dsa.pub存放每台服务器自己的公钥authorized_keys存放的也是服务器的公钥,不过除了自己的公钥外,也可以存放其它服务器的公钥。
再执行ssh layne1,让其自己和自己之间进行免密登陆。
2、上传hadoop的tar包hadoop-2.6.5.tar.gz到Linux系统的/opt/apps目录下
3、解压hadoop-2.6.5.tar.gz到/opt目录
[root@layne1 apps]# tar -zxvf hadoop-2.6.5.tar.gz -C /opt
4、删除hadoop-2.6.5/share/下的doc目录,doc里面是一些页面和文档,在Linux上没用,删除以后我们把这个hadoop复制到其他服务器上速度比较快
[root@layne1 hadoop-2.6.5]# pwd
/opt/hadoop-2.6.5
[root@layne1 hadoop-2.6.5]# cd share
[root@layne1 share]# ls
doc hadoop
[root@layne1 share]# rm -rf doc
[root@layne1 share]# ls
hadoop
5、添加hadoop环境变量
将HADOOP_HOME以及HADOOP_HOME/bin和HADOOP_HOME/sbin添加到环境变量,在/etc/profile里最后一行添加:
export HADOOP_HOME=/opt/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
再执行source /etc/profile使其立即生效。
6、hadoop-env.sh配置
由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,需要手动指定。
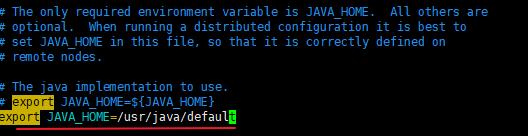
在/opt/hadoop-2.6.5下,输入vim ./etc/hadoop/hadoop-env.sh,找到JAVA_HOME所在的行,并改为export JAVA_HOME=/usr/java/default。
[root@layne1 hadoop-2.6.5]# pwd
/opt/hadoop-2.6.5
[root@layne1 hadoop-2.6.5]# cd ./etc/hadoop/
[root@layne1 hadoop]# vim hadoop-env.sh
7、配置core-site.xml
[root@layne1 hadoop]# pwd
/opt/hadoop-2.6.5/etc/hadoop
[root@layne1 hadoop]# vim core-site.xml
这个文件指定的是namenode的访问
<configuration>
<!-- 指定访问HDFS的时候路径的默认前缀 / hdfs://layne1:9000/ -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://layne1:9000</value>
</property>
<!-- 指定hadoop的临时目录位置,它会给namenode、secondarynamenode以及datanode的存储目录指定前缀 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/layne/hadoop/pseudo</value>
</property>
</configuration>
配置文件拷贝后格式不美观,可以通过以下方式格式化:
- 在vim命令按ESC回报命令模式,把光标定位在
<configuration>行首 - 输入
Ctrl+V - 按键盘上的下箭头按钮,直到
<configuration/> - 输入
:!xmllint -format -,然后回车 - 删除
<configuration>上一行多出的<?xml version="1.0"?>
值得一提的是,这些配置都可以在hadoop-2.6.5\share\doc\hadoop\index.html里面找到,最好用IE浏览器打开,否则可能不识别。
在windows上用IE浏览器打开hadoop-2.6.5\share\doc\hadoop\index.html,点击进入core-default.xml
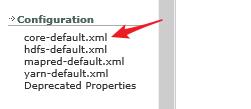
可以看到,hadoop.tmp.dir的默认配置为/tmp/hadoop-${user.name},即在Linux的临时文件下保存,所以我们要修改配置

要记住:
core-default.xml中的所有配置都可以在core-site.xml中进行配置。hdsf-default.xml中的所有配置都可以在hdfs-site.xml中进行配置。
8、配置hdfs-site.xml
[root@layne1 hadoop]# pwd
/opt/hadoop-2.6.5/etc/hadoop
[root@layne1 hadoop]# vim hdfs-site.xml
加入以下内容:
<configuration>
<!-- 指定block副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定secondarynamenode所在的位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>layne1:50090</value>
</property>
</configuration>
9、配置slaves
这里是配置datanode结点
[root@layne1 hadoop]# pwd
/opt/hadoop-2.6.5/etc/hadoop
[root@layne1 hadoop]# vim slaves
layne1
即在slaves输入layne1。
10、格式化hadoop
下面可以看到,第7步配置的临时目录位置不存在
[root@layne1 hadoop]# ls /var/layne/hadoop/pseudo
ls: cannot access /var/layne/hadoop/pseudo: No such file or directory
现在输入
hdfs namenode -format
再次查看日志
[root@layne1 hadoop]# ls /var/layne/hadoop/pseudo
dfs
[root@layne1 hadoop]# cd /var/layne/hadoop/pseudo/dfs
[root@layne1 dfs]# ls
name
[root@layne1 dfs]# cd name
[root@layne1 name]# ls
current
[root@layne1 name]# cd current
[root@layne1 current]# ls
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
[root@layne1 current]# pwd
/var/layne/hadoop/pseudo/dfs/name/current
11、启动hadoop
输入以下命令启动hadoop
start-dfs.sh
启动过程如下:
[root@layne1 current]# start-dfs.sh
21/03/16 21:19:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [layne1]
layne1: starting namenode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-namenode-layne1.out
layne1: starting datanode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-datanode-layne1.out
Starting secondary namenodes [layne1]
layne1: starting secondarynamenode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-layne1.out
21/03/16 21:20:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
12、查看hadoop进程
输入jps
[root@layne1 current]# jps
1623 SecondaryNameNode
1467 DataNode
1389 NameNode
1741 Jps
说明进程都正常启动了,然后网页访问:
http://layne1:50070
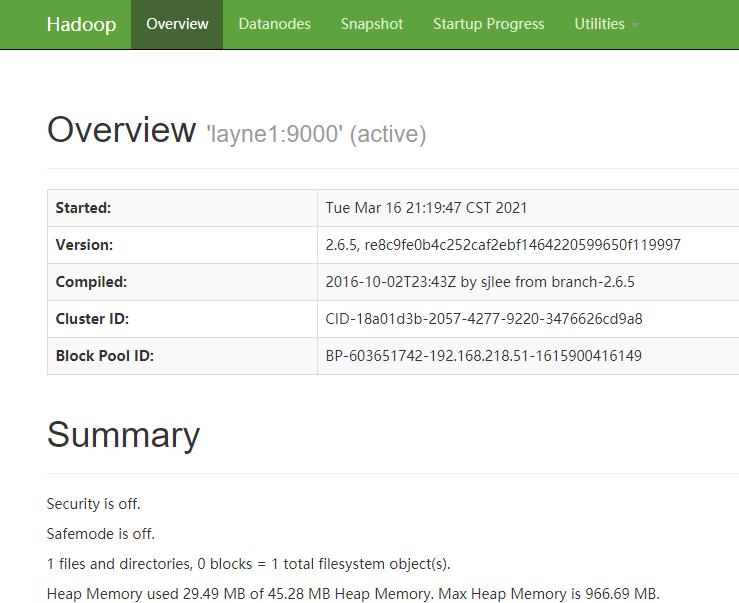
进入文件系统
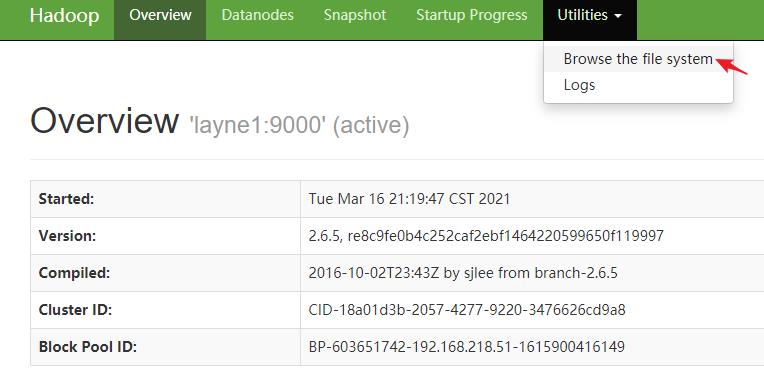
下图可以看出,文件系统为空
13、上传文件
我们试着上传一个文件
[root@layne1 apps]# ll
total 387548
-rw-r--r-- 1 root root 199635269 Mar 16 19:30 hadoop-2.6.5.tar.gz
-rw-r--r-- 1 root root 179505388 Feb 23 13:34 jdk-8u221-linux-x64.rpm
-rw-r--r-- 1 root root 17699306 Feb 23 13:34 zookeeper-3.4.6.tar.gz
[root@layne1 apps]# hdfs dfs -put hadoop-2.6.5.tar.gz /
21/03/16 21:29:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
现在可以看到上传的文件
点击文件名称,可以看到该文件被分为两个block块,第一个block为128M(没有指定block,默认大小为128M)
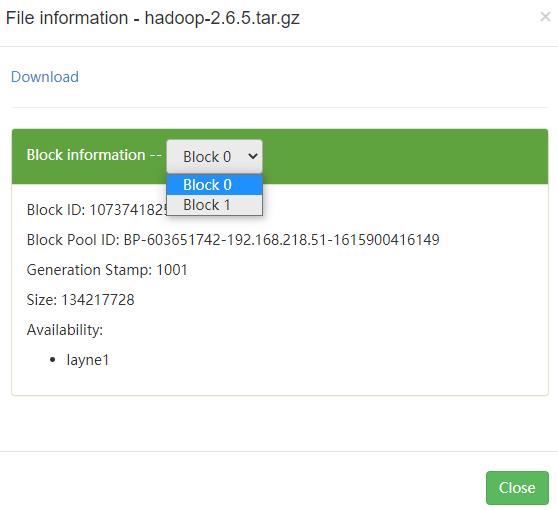
然后,我们自己生成一个文件
[root@layne1 apps]# pwd
/opt/apps
[root@layne1 apps]# for i in `seq 100000`; do echo "hello layne $i" >> hh.txt; done
上传生成的hh.txx文件,文件block块大小为1048576字节,重复数为1:
hdfs dfs -D dfs.blocksize=1048576 -D dfs.replication=1 -put hh.txt /
再次刷新,就能看到上传的文件了。
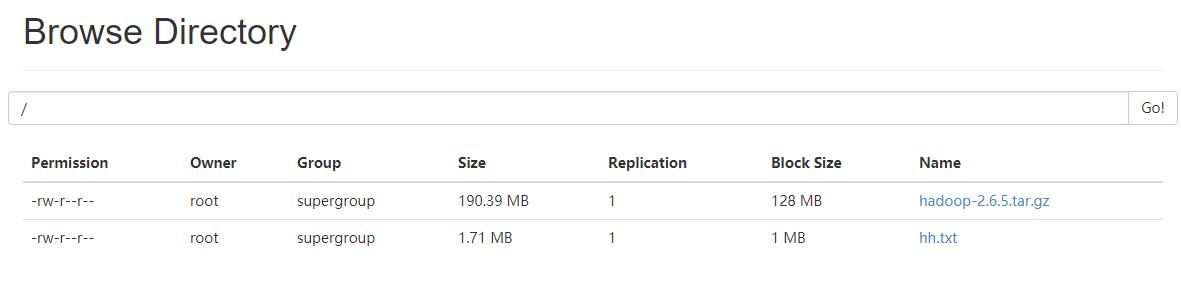
从上图可以看出,刚刚上传的hh.txx文件块大小为1M,这是因为1024x1024=1048576,dfs.blocksize单位是字节,即bytes,1KB=1024bytes,所以1024x1024bytes=1048576bytes=1024KB=1M
-D dfs.replication=1指定副本数为1,如果不指定,默认按照第8步dfs.replication配置的副本数。一般来说,可以将不重要的文件的副本数设置小一点。
在上传文件时,-D dfs.blocksize和-D dfs.replication可以不指定,所以上传文件的格式为:
hdfs dfs -put 被上传的文件全路径名或相对路径名 放置的hdfs目录
比如,hdfs dfs -put test.txt /a/b,就是将当前目录下的test.txt文件,上传到hdfs的a/b目录下,这个前提是a/b目录一定要存在。
14、查看hdfs中的文件
[root@layne1 apps]# hdfs dfs -ls /
21/03/16 21:55:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 root supergroup 199635269 2021-03-16 21:29 /hadoop-2.6.5.tar.gz
-rw-r--r-- 1 root supergroup 1788895 2021-03-16 21:53 /hh.txt
当然,也可以在浏览器中查看。
15、查看hadoop存储目录
[root@layne1 dfs]# pwd
/var/layne/hadoop/pseudo/dfs
[root@layne1 dfs]# ls
data name namesecondary
查看生成的块
[root@layne1 subdir0]# pwd
/var/layne/hadoop/pseudo/dfs/data/current/BP-603651742-192.168.218.51-1615900416149/current/finalized/subdir0/subdir0
[root@layne1 subdir0]# ll -h
total 194M
-rw-r--r-- 1 root root 128M Mar 16 21:29 blk_1073741825
-rw-r--r-- 1 root root 1.1M Mar 16 21:29 blk_1073741825_1001.meta
-rw-r--r-- 1 root root 63M Mar 16 21:29 blk_1073741826
-rw-r--r-- 1 root root 500K Mar 16 21:29 blk_1073741826_1002.meta
-rw-r--r-- 1 root root 1.0M Mar 16 21:53 blk_1073741827
-rw-r--r-- 1 root root 8.1K Mar 16 21:53 blk_1073741827_1003.meta
-rw-r--r-- 1 root root 723K Mar 16 21:53 blk_1073741828
-rw-r--r-- 1 root root 5.7K Mar 16 21:53 blk_1073741828_1004.meta
查看datanode相关信息
[root@layne1 current]# pwd
/var/layne/hadoop/pseudo/dfs/data/current
[root@layne1 current]# cat VERSION
#Tue Mar 16 21:20:02 CST 2021
storageID=DS-bd5deff9-13b7-4c66-bf6f-b044da77d527
clusterID=CID-18a01d3b-2057-4277-9220-3476626cd9a8
cTime=0
datanodeUuid=6e4f5a59-386e-48d2-a4dd-aa4c36b723e0
storageType=DATA_NODE
layoutVersion=-56
16、关闭hadoop
stop-dfs.sh
内容总结
以上是互联网集市为您收集整理的hadoop伪分布式集群搭建全部内容,希望文章能够帮你解决hadoop伪分布式集群搭建所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。