Hinton胶囊神经网络新作How to represent part-whole hierarchies in a neural network(一)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hinton胶囊神经网络新作How to represent part-whole hierarchies in a neural network(一),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3475字,纯文字阅读大概需要5分钟。
内容图文
")
How to represent part-whole hierarchies in a neural network
21年2月底,深度学习教父Hinton发表了一篇新的论文《How to represent part-whole hierarchies in a neural network》。 这是自2017年开展胶囊网络研究以来的第四篇文章,是神经网络领域研究的最前沿,也可以认为是胶囊神经网络的第四版,是一个尚未被实现的系统,称为GLOM。本文探讨此研究所涉及的理论基础,内容结构如下:
- 介绍胶囊网络
- 文章对Transformer的改进
- 对比学习的概念
- 知识蒸馏的使用
- 神经场的使用
胶囊神经网络
自2017年以来,Hinton提出了三个版本的胶囊神经网络。首先是基于动态路由的胶囊网络。
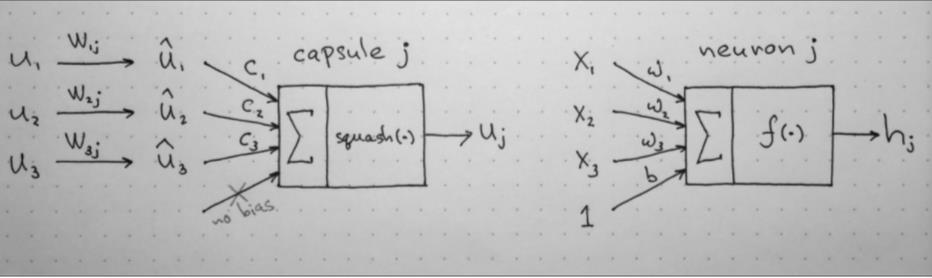
其计算步骤为:
- 输入向量的矩阵乘法 :胶囊接收的输入向量(上图中的u1、u2和u3)来自下层的3个胶囊。这些向量的长度表示对象存在的概率,向量的方向表示对象的一些内部状态。接着将这些向量乘以相应的权重矩阵W。W编码了低层特征(眼睛、嘴巴和鼻子)和高层特征(面部)之间的空间关系和其他重要关系。乘以这些矩阵W后,我们得到的是高层特征的预测位置。例如,û1表示根据检测出的眼睛的位置,面部应该在什么位置,û2表示根据检测出的嘴巴的位置,面部应该在什么位置,û3表示根据检测出的鼻子的位置,面部应该在什么位置。如果这三个低层特征的预测指向的位置和状态与面部的位置和状态相同,那么面部必然存在;
- 输入向量的标量加权 :这个步骤和普通神经元的对应步骤很接近,但是普通神经元的权重是通过反向传播学习的,而胶囊则使用“动态路由”,这是一种确定每个胶囊的输出的新方法。一个低层胶囊需要“决定”将它的输出发送给哪个高层胶囊。它将通过调整权重C做出决定,胶囊在传递输出前,先将输出乘以这个权重,高层胶囊接收到来自其他低层胶囊的向量。动态路由算法可以让低层胶囊测量哪个高层胶囊更能接受其输出,并据此自动调整权重,使对应胶囊的权重变高。
- 加权输入向量之和:这一步骤表示输入的组合,和通常的人工神经网络差不多。
- 挤压函数——向量到向量的非线性变换:CapsNet的另一大创新是新颖的非线性激活函数,这个函数接受一个向量,然后在不改变方向的前提下,压缩它的长度到1以下,可以解释为胶囊检测的给定特征的概率并且压缩输入向量的标量而不改变其方向。输出向量的长度代表胶囊检测的给定特征的概率。
在2018和2019年,Hinton又推出EM胶囊网络和基于Set Transformer的胶囊网络。虽然在特定任务上胶囊网络的表现不错,但是其本身的缺陷限制了它在其他特定任务上的表现,即需要给part-whole层次结构中的节点预先分配固定数量的神经元。文章提出的GLOM使用了完全不同的架构。
改进的Transformer
Transformer中的Attention机制使用了Q、K、V三个矩阵,即query向量与key向量的转置做内积,再使用Softmax进行输出,结果乘以values向量。而在GLOM中,Hinton使Q = K = V = Embedding 向量,其背后的动机在于,让Embedding向量本身就是query向量与key向量,使得Attention机制倾向于重点关注和自己相似的向量,让相似的向量互相吸收、互相接近,从而达到聚集的效果。
对比学习
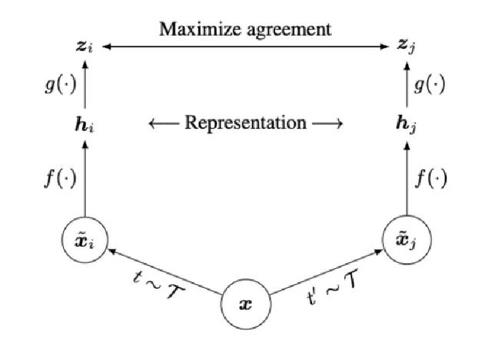
以Hinton组在2020年发表的SimCLR对比学习模型为例,其主要部分如下:
- 对给定的输入图片,使用数据增强技术,得到两个相关的图片;
- f(·)是一个编码器,获得图片的特征表示;
- g(·)是一个映射函数,讲特征表示映射到对比损失空间;
- 定义损失函数,最小化同类型输入的损失函数,最大化不同类型输入的损失函数;
此处引用 Mohammad Norouzi 对此的精炼描述:
- 随机抽取一个小批量
- 给每个例子绘制两个独立的增强函数
- 使用两种增强机制,为每个示例生成两个互相关联的视图
- 让相关视图互相吸引,同时排斥其他示例
知识蒸馏
所谓知识蒸馏,即定义一个教师模型、一个学生模型,使用教师模型来诱导学生模型进行训练,实现知识迁移。教师网络的推理性能通常要优于学生网络,且教师网络推理精度越高,越有利于学生网络的学习。在GLOM中,把Top-down神经网络和Bottom-up神经网络作为学生模型,把二者达成一致(Agreement)作为教师模型。
神经场
对于一张图片信息,想要定位代表某个图片块的Embedding的位置,就需要有一个额外的位置输入,例如Transfomer中的position embedding,我们引入神经场(Neural Fields),获取整张图片各个小块的位置信息,即给每个图像块标记坐标信息,从而实现了定位的效果。
内容总结
以上是互联网集市为您收集整理的Hinton胶囊神经网络新作How to represent part-whole hierarchies in a neural network(一)全部内容,希望文章能够帮你解决Hinton胶囊神经网络新作How to represent part-whole hierarchies in a neural network(一)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。