TensorFlow的图切割模块——Graph Partitioner
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了TensorFlow的图切割模块——Graph Partitioner,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含10577字,纯文字阅读大概需要16分钟。
内容图文

背景
功能描述
Graph Partition切割流程
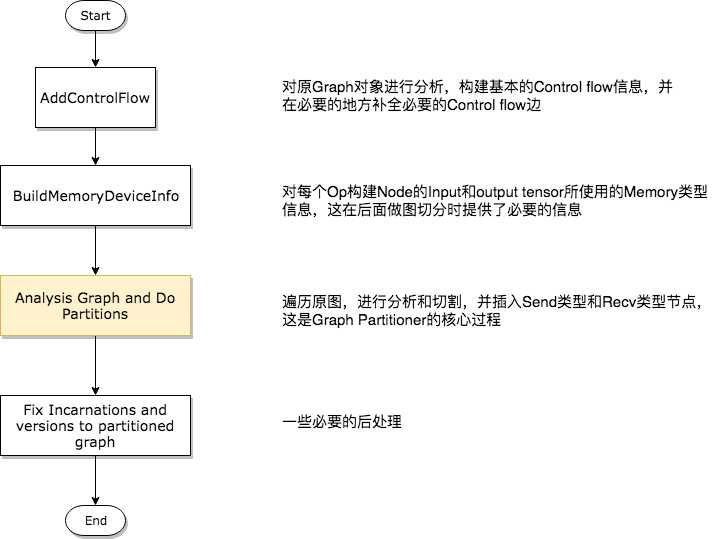
第一步——分析构建Control Flow相关信息
1
GraphInfo g_info;
2
if (!opts.control_flow_added) {
3// Add the "code" for distributed execution of control flow. Code is
4// added only for the frames that are placed on multiple devices. The
5// new graph is an equivalent transformation of the original graph and
6// has the property that it can be subsequently partitioned arbitrarily
7// (down to the level of individual device) for distributed execution. 8 status = AddControlFlow(opts, g, &g_info);
9if (!status.ok()) return status;
10 }
第二步——构建Op的Input和Output Memory类型信息
1
//
MemoryType is used to describe whether input or output Tensors of
2
//
an OpKernel should reside in "Host memory" (e.g., CPU memory) or
3
//
"Device" Memory (CPU memory for CPU devices, GPU memory for GPU
4
//
devices).
5
enum
MemoryType {
6 DEVICE_MEMORY = 0,
7 HOST_MEMORY = 1,
8 };
1
#define REGISTER_GPU_KERNEL(type) 2 REGISTER_KERNEL_BUILDER(Name("Reshape") 3 .Device(DEVICE_GPU) 4 .HostMemory("shape") 5 .TypeConstraint<type>("T") 6 .TypeConstraint<int32>("Tshape"), 7 ReshapeOp); 8 REGISTER_KERNEL_BUILDER(Name("Reshape") 9 .Device(DEVICE_GPU) 10 .HostMemory("shape") 11 .TypeConstraint<type>("T") 12 .TypeConstraint<int64>("Tshape"), 13 ReshapeOp);
上面的宏显示,虽然Reshape Op确实在GPU上有注册的实现版本,但是它依然要使用HostMemory。另外,某些Tensor的类型也决定了其是否可以被放置到Device Memory上,一般情况下float类型的数据对于计算设备是非常友好的,而String类型就不是这样,所以在types.cc文件中规定了一些强制被放在HostMemory的数据类型,如下代码所示。
1
bool
DataTypeAlwaysOnHost(DataType dt) {
2
//
Includes DT_STRING and DT_RESOURCE.
3
switch
(dt) {
4
case
DT_STRING:
5
case
DT_STRING_REF:
6
case
DT_RESOURCE:
7
return
true
;
8
default
:
9
return
false
;
10
}
11 }
第三步——对原图进行分析,并产出切割后的多个子图
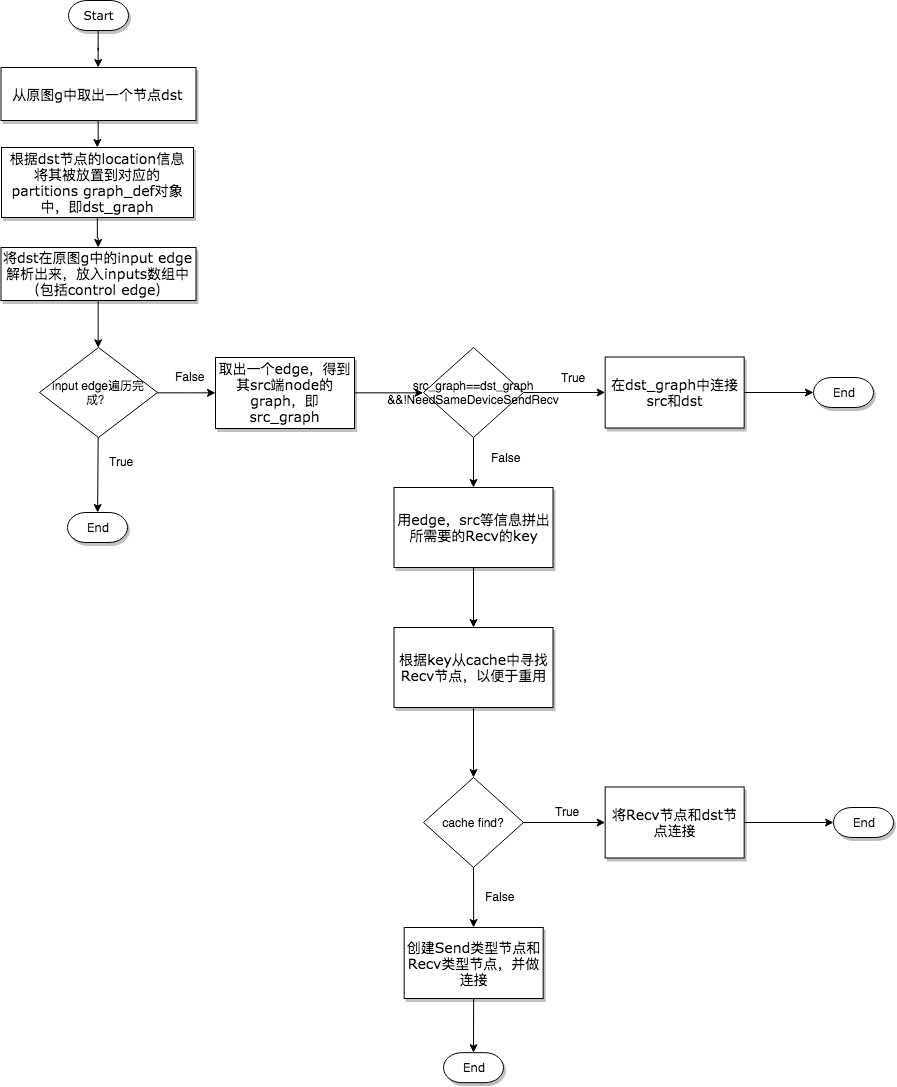
1
//
Check whether there is already a send/recv pair transferring
2
//
the same tensor/control from the src to dst partition.
3
const
bool on_host = IsDstInputOnHost(edge, g_info);
4 DupRecvKey key{src->id(), edge->src_output(), dst_graph, on_host};
5 auto iter = dup_recv.find(key);
6if (iter != dup_recv.end()) {
7// We found one. Reuse the data/control transferred already. 8conststring& recv_node_name = iter->second.recv->name();
9if (edge->IsControlEdge()) {
10 AddInput(dst_def, recv_node_name, Graph::kControlSlot);
11 } else {
12 AddInput(dst_def, recv_node_name, 0);
13 }
14 ref_control_inputs.push_back(recv_node_name);
1516// We want the start_time for the recv to be the smallest of the start
17// times of it‘s consumers. So we update this whenever we use a recv,
18// and write it out to the attribute at the end of the subroutine19if (iter->second.start_time > recv_start_time) {
20 iter->second.start_time = recv_start_time;
21 }
22continue;
23 }
1
const FunctionLibraryDefinition* flib_def = opts.flib_def;
2if (flib_def == nullptr) {
3 flib_def = &g->flib_def();
4 }
5 6// Set versions, function library and send/recv incarnation. 7for (auto& it : *partitions) {
8 GraphDef* gdef = &it.second;
9 *gdef->mutable_versions() = g->versions();
10// Prune unreachable functions from `flib_def` before adding them to `gdef`.11 *gdef->mutable_library() = flib_def->ReachableDefinitions(*gdef).ToProto();
1213// Traverse the graph to fill every send/recv op‘s incarnation
14// information.15 SetIncarnation(opts, gdef);
16 }
Send和Recv节点对插入的三种情况
在代码中,声明插入Send和Recv节点的代码段非常简单,如下所示。
1
//
Need to split edge by placing matching send/recv nodes on
2
//
the src/dst sides of the edge.
3 NodeDef* send = AddSend(opts, g_info, src_graph, edge, send_from,
4 send_start_time, &status);
5if (!status.ok()) return status;
6 7 NodeDef* real_recv = nullptr;
8 NodeDef* recv =
9 AddRecv(opts, g_info, dst_graph, edge, &real_recv, &status);
10if (!status.ok()) return status;
但是对于不同的情况却有着丰富的处理逻辑,所以下面在展示示意图的同时,会将相关的代码段摘出来做展示。
在同一个Device上插入Send和Recv节点对
因为同一个Device上的Send和Recv节点在执行过程中实际上Memory Copy,而Recv的kernel又是异步的,所以需要有一种机制保证保证Recv一定要在Send之后执行,因此需要在Send和Recv之间插入一个Control Edge,从图的依赖上保证它们的执行顺序。
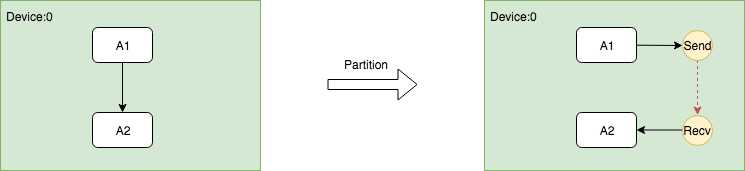
这个过程的关键是在插入Send和Recv节点之后,需要插入额外的Control Edge,代码如下。
//
Fix up the control flow edge.
//
NOTE(yuanbyu): ‘real_recv‘ must be the real recv node.
if (src_graph == dst_graph) {
// For same device send/recv, add a control edge from send to recv.
// This prevents the asynchronous recv kernel from being scheduled
// before the data is available.
AddInput(real_recv, send->name(), Graph::kControlSlot);
}
跨Device根据DataFlow插入Send和Recv节点对
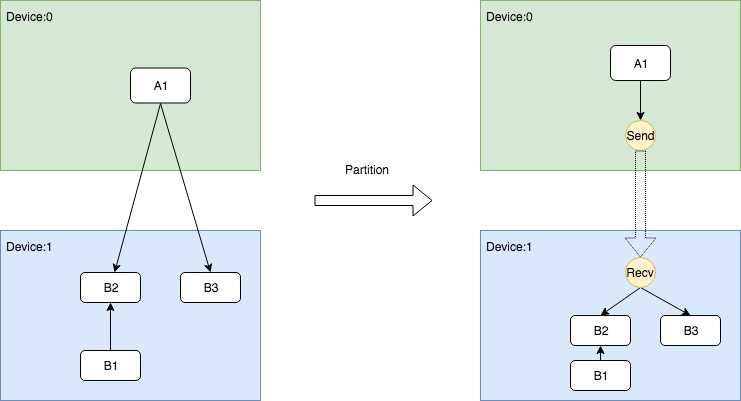
跨Device根据ControlFlow插入Send和Recv节点对
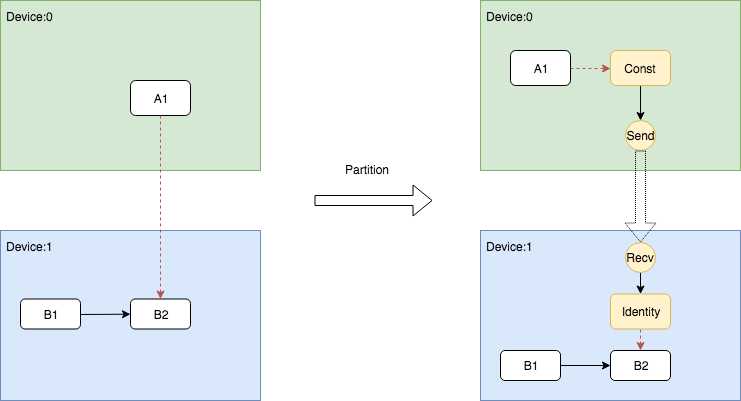
1
NodeDefBuilder::NodeOut send_from;
2
if (edge->IsControlEdge()) {
3// Insert a dummy const node that will generate a tiny
4// data element to be sent from send to recv. 5 VLOG(1) << "Send/Recv control: " << src->assigned_device_name() << "[" 6 << src->name() << "] -> " << dst->assigned_device_name() << "[" 7 << dst->name() << "]";
8 NodeDef* dummy = AddDummyConst(opts, src_graph, edge, &status);
9if (!status.ok()) return status;
10// Set the start time for this dummy node.11if (opts.scheduling_for_recvs) {
12 AddNodeAttr("_start_time", send_start_time, dummy);
13 }
14 AddInput(dummy, src->name(), Graph::kControlSlot);
15 send_from.Reset(dummy->name(), 0, DT_FLOAT);
16 } else {
17 send_from.Reset(src->name(), edge->src_output(), EdgeType(edge));
18 }
Indentity即相关依赖的插入逻辑被写在了AddRecv中,下面展示了这个片段。
1
//
Add the cast node (from cast_dtype to dtype) or an Identity node.
2
if (dtype != cast_dtype) {
3conststring cast_op = (host_memory) ? "_HostCast" : "Cast";
4 NodeDefBuilder cast_builder(opts.new_name(src->name()), cast_op);
5 cast_builder.Attr("DstT", dtype);
6 cast_builder.Device(dst->assigned_device_name())
7 .Input(recv->name(), 0, cast_dtype);
8 NodeDef* cast = gdef->add_node();
9 *status = cast_builder.Finalize(cast);
10if (!status->ok()) return nullptr;
11return cast;
12 } elseif (edge->IsControlEdge()) {
13// An Identity is only needed for control edges.14 NodeDefBuilder id_builder(opts.new_name(src->name()), "Identity");
15 id_builder.Device(dst->assigned_device_name())
16 .Input(recv->name(), 0, cast_dtype);
17 NodeDef* id = gdef->add_node();
18 *status = id_builder.Finalize(id);
19if (!status->ok()) return nullptr;
20return id;
21 } else {
22return recv;
23 }
关于使用bfloat16压缩通信
TensorFlow支持通过使用bfloat16减少通信量,虽然bfloat16理论上是有损精度的,但是大量的实践证明这个精度损失是基本感知不到的。bfloat16的通信功能可以通过以下配置项打开,只要在创建Session时传入打开该功能的config即可。
graph_options = tf.GraphOptions(enable_bfloat16_sendrecv=True) session_config = tf.ConfigProto(gpu_options=gpu_options)
总结
原文:https://www.cnblogs.com/deep-learning-stacks/p/10054529.html
内容总结
以上是互联网集市为您收集整理的TensorFlow的图切割模块——Graph Partitioner全部内容,希望文章能够帮你解决TensorFlow的图切割模块——Graph Partitioner所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。