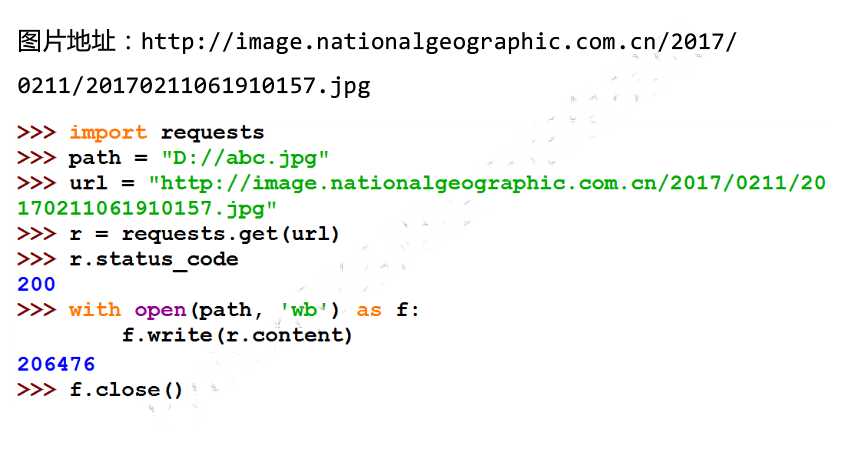
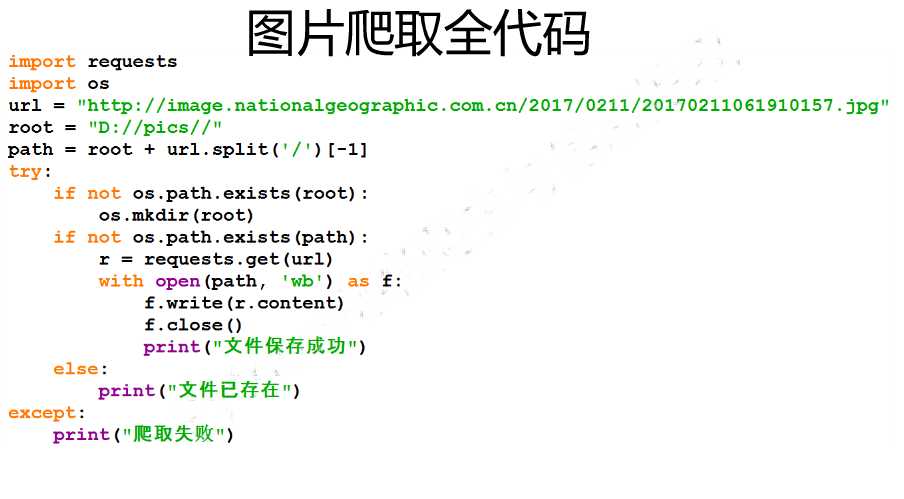
书上介绍了两种存储图的方式---------->>1、邻接矩阵 2、邻接表邻接矩阵的优势在于 可以快速读取两个节点的连通情况 和权值O(1) 但是内存消耗太大 特别是图比较稀疏的时候浪费非常多 那么久有了邻接表的方式struct Edge{ int to , cost} vector<Edge> G[MAXV]这样节省了内存 O(E) 但是因为vector是封装了很多功能的容器 在普通题目当中时间消耗不容忽视因此有了向前星 的写法 代替vector的方式 1 #include <iostream>2 #...
1delimiter $$2CREATEPROCEDURE `proc_Ranking`(IN sku VARCHAR(20),IN skuname VARCHAR(20),IN status VARCHAR(20),IN sales VARCHAR(20),IN today VARCHAR(20),IN old_time VARCHAR(20))3BEGIN 4SET@sku= sku;5SET@skuname= skuname;6SET@status= status;7SET@sales= sales;8SET@today= today;9SET@old_time= old_time;
10SET@sql_header= "SELECT11 c.`sku`,c.`amt`,c.`avgs` avg,s.`skuname`,s.`skupic`,s.`editt...
高端存储代替PBBA(备份专业设备),没错,这种事情只有Moshe Yanai才能如此不拘一格。其他人想都不敢想。
今天,我在Infinidat的数据保护白皮书看到这样一个案例,一个客户(没有点名)采用了两台InfiniBox高端存储,替换了22台EMC Data Domian。关键是替换后,用户说TCO下降了。这是我看到的唯一一个高端存储替换专业备份设备的例子,而且还是市场占有率最高的Data Domain。
Data Domain在重删方面久负盛名,按理说$/GB有效容量方...
InnoDB 存储引擎支持以下几种觉的索引:
1.1 B+ 树索引 (平衡树索引)
1.2 全文索引
1.3 哈希索引
InnoDB 存储引擎支持的哈希索引是自适应的, InnoDB 存储引擎会根据表的使用情况自动为表生成哈希索引,也就是说无法人为在表中生成哈希索引。
B+ 树索引就是传统意义上的索引,目前关系型数据库中查找最为常用和最为有效的索引用。B+ 树索引引的构造类似于二...
对象存储服务(Object Storage Service,OBS)对象存储服务(Object Storage Service,OBS)提供海量、安全、高可靠、低成本的数据存储能力,可供用户存储任意类型和大小的数据。适合企业备份/归档、视频点播、视频监控等多种数据存储场景。对象存储服务 (Object Storage Service,OBS)是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,包括:创建、修改、删除桶,上传、下载、删除对象等。...
有向图变无向图并存储
Transform directed graph into undirected graph.''''''import networkx as nxedgelist_path = 'fq_following.number'
edgelist=[]
with open(edgelist_path, 'r') as edgelistX_reader: # input anchor for bindfor line in edgelistX_reader.readlines():temp_array = line.strip().split(' ') #edgelist.append(list(map(int, temp_array))) # for netX, directly append
edgelistX_reader.close()node...
Alter Proc P_Page( @TblName varchar(200), --表名 @PageSize int, --每页显示条数 @PageIndex int = 1, --页面索引(页码) @strGetFields varchar(1000)=‘*‘, --无传入值,则搜索所有列 @OrderType int = 0, --是否倒序(0=否,1=是) @FldName varchar(100), --以什么条件进行倒叙 @StrWhere varchar(2000), --查询条件 @Total int = 0 out )AsBegin Set Nocount on Declare @strSq...
ArrayList 和 Vector 都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector 由于使用了 synchronized 方法(线程安全),通常性能上较 ArrayList 差,而LinkedList 使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较...
第一章 计算机的IO世界1.1 总线1.1.1 总线的概念计算机中所有的IO都通过共享总线的方式来实现。 总线实际上就是一条或多条的物理导线。密密麻麻的印到电路板上,而且为了避免高频振荡的干扰,一般都会分组印刷到不同的电路板上,然后压合起来。 1.1.2 总线的分类PCI总线是目前PC机与x86服务器普遍使用的南桥与外设连接的总线技术。 PCI总线的地址总线和数据总线是分时复用的,这样可以节省管脚数量。 在数据传输时,PCI协议上有三种...
xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.1.RELEASE<...
AIX存储管理基本概念和操作 AIX存储管理的基本概念包括(不限于) 1.磁盘或者硬盘 如何查看系统已有的磁盘及相关属性 2.物理卷(Physical Volume,PV) 物理卷和磁盘/硬盘有何关联,列出系统已有PV及相关属性,添加/删除/维护PV属性 3.卷组(Volume Group,VG) VG的创建,删除,扩容,维护和导入导出迁移,查看相关属性 4.物理分区(Physical Parttion,PP) 什么是PP 5.逻辑分区(Logical Partition,LP) 什么是LP 6.逻辑卷(Logical Volume,...
索引是查询优化最有效和最常用的技术
索引是一个单独的、物理的数据库结构,它是指向表中某一列或若干列上的指针列表。
mysql中,一个表的物理存储由两部分组成,一部分用于存放表的数据,另一部分存放索引,当进行数据搜索时,mysql会首先搜索索引,从中找到所需数据的起始位置的指针,再直接通过指针查找目标数据。
1.创建索引:
CREATE INDEX 索引名 on 表名(要添加索引的列名)
可以给一个表中的多个列添加索引
通过在查询sql语句...
在数据库编程里使用数据类型,能够提高代码的重用性。它们常常被使用在方法和存储过程中。使用数据类型,我们能够避免在存储过程里定义一串的參数,让人眼花缭乱,它就相当于面向对象语言里。向一个方法里传入一个对象,而该对象有各种属性,存储过程仅仅须要获取这个对象就能获取到各个參数,然后做出对应的处理。有所不同的是SQL的表类型是能够包括多条数据的。到底是怎么一回事,且看以下的样例。1. 首先我创建了一个学生表,包...
传统的企业级应用,其实很少会有海量应用,因为企业的规模本身就摆在那里,能有多少数据?高并发?海量数据?不存在的! 不过在互联网公司中,因为应用大多是面向广大人民群众,数据量动辄上千万上亿,那么这些海量数据要怎么存储?光靠数据库吗?肯定不是。 今天和大家简单的聊一聊这个话题。 海量数据,光用数据库肯定是没法搞定的,即使不读这篇文章,相信大家也能凝聚这样的共识,海量数据,不是说一种方案、两种方案就能搞定,...
create procedure P_mng_prize @ResultCode char(1) out, @ResultMsg char(50) out, @...