首页 / JAVA / Java实现的词频统计——功能改进
Java实现的词频统计——功能改进
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Java实现的词频统计——功能改进,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4447字,纯文字阅读大概需要7分钟。
内容图文

本次改进是在原有功能需求及代码基础上额外做的修改,保证了原有的基础需求之外添加了新需求的功能。
功能:
1. 小文件输入——从控制台由用户输入到文件中,再对文件进行统计;
2.支持命令行输入英文作品的文件名;
3.支持命令行输入存储有英文作品文件的目录名,批量统计;
4.从控制台读入英文单篇作品,重定向输入流。
实现:
1.判断输入方式,如果从命令行传递参数则直接对文件进行统计;如果未传递参数,其方式同控制台相同,由用户从标准输入流输入到文件,再对文件进行词频统计。这里如果传入文件路径时会对其是否是文件夹进行判断,如果是文件夹,则对其目录中的文件进行统计。
1
if (args.length == 0) {
2 Scanner in = new Scanner(System.in);
3 FileWriter out = new FileWriter("Content.txt");
4 5 System.out.println("请输入内容,最后以Q结束:");
6 7while (in.hasNext()) {
8 out.write(in.nextLine()+"\r\n");
9 }
10 out.close();
11 in.close();
1213new FileProccessing("Content.txt");
14 }
15for (int i = 0; i < args.length; i++) {
16 String FileName = args[i];
17 File fs = new File(FileName);
18if (fs.isDirectory()) {
19 File[] filelist = fs.listFiles();
20for (int n = 0; n < filelist.length; n++) {
21new FileProccessing(filelist[n].getAbsolutePath());
22 }
2324 } else {
25new FileProccessing(FileName);
26 }
27 }
2.对ByValueComparator类做了修改,使其能够按词频降序排列的同时,对同频率的单词进行升序排列。
1
public
class ByValueComparator implements Comparator<Entry<String,Integer>> {
2 Map<String, Integer> hashmap;
3public ByValueComparator(Map<String, Integer> hm) {
4this.hashmap = hm;
5 }
6 7 @Override
8publicint compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
9// TODO Auto-generated method stub1011if (o1.getValue().compareTo(o2.getValue()) == -1) {
12return 1;
13 } elseif (o1.getValue().compareTo(o2.getValue()) == 0) {
14return o1.getKey().compareTo(o2.getKey()); //单次出现频率相同时,对单词进行升序排列
15 } else {
16return -1;
17 }
18 }
19 }
3.与上一次相比,为了方便调用,将对文件进行统计操作的代码归入新的类FileProccessing。同时将readline()改为read(char[] c),解决了当一行字符过多时报错的问题。当进行统计的文件过大时,原本输出到屏幕会自动改为输出到文件中,避免了因输出而占用了大部分时间,同时方便用户查阅(默认输出到工程目录下)。
其中有个小细节:程序中char数组默认大小为64,当读到最后一块时,字符不足64个时,多余未读入字符的数组元素默认为‘\0‘,拆分之后输出结果中会多出一项“ ——1”。因此,在StringTokenizer方法中要录入"\0"作为分隔字符。
读入文件并进行统计,结果存入到hashmap中:
1
int i = 0;
2char[] c = newchar[64];
3 String thelast = "";
4 String wordpart = "";
5while ((i = br.read(c)) > 0) {
6 wordpart = "";
7 8int m = i - 1;
9while (Character.isLetter(c[m])) {
10 wordpart = String.valueOf(c[m]) + wordpart;
11 c[m] = ‘ ‘;
12 m--;
13 }
14 String s = thelast + String.valueOf(c);
15 StringTokenizer st = new StringTokenizer(s, " ,.!?\"\‘;:0123456789\n\r\t“”‘’·——-=*/()[]{}…()【】{}\0"); // 用于切分字符串1617while (st.hasMoreTokens()) {
18 String word = st.nextToken();
19if (hm.get(word) != null) {
20int value = ((Integer) hm.get(word)).intValue();
21 value++;
22 hm.put(word, new Integer(value));
23 } else {
24 hm.put(word, new Integer(1));
25 }
26 }
27 thelast = wordpart;
28 }
29if (!wordpart.isEmpty()) {
30if (hm.get(wordpart) != null) {
31int value = ((Integer) hm.get(wordpart)).intValue();
32 value++;
33 hm.put(wordpart, new Integer(value));
34 } else {
35 hm.put(wordpart, new Integer(1));
36 }
37 }
判断输出内容多少,自动匹配标准输出还是文件输出。其中运用了正则替换,用来打印当前文件名。同时还对总单词量及词汇量进行了统计:
1
int NumofWord = 0;
2 Iterator iter = hm.entrySet().iterator();
3while (iter.hasNext()) {
4 Map.Entry entry = (Map.Entry) iter.next();
5 NumofWord += (Integer) entry.getValue();
6 }
7 String reg = ".*\\\\(.*)";
8 String name = filename.replaceAll(reg, "$1");
9if (hm.size() > 100) {
1011 FileWriter result = new FileWriter("Result.txt", true);
1213 result.write("~~~~~~~~~~~~~~~~~~~~\r\n");
14 result.write(name.substring(0, name.lastIndexOf(".")) + "\r\n");
15 result.write("number of the words:" + NumofWord + "\r\n");
16 result.write("totals:" + hm.size() + "\r\n");
17for (Map.Entry<String, Integer> str : ll) {
18 result.write(str.getKey() + "——" + str.getValue() + "\r\n");
19 }
2021 result.write("~~~~~~~~~~~~~~~~~~~~\r\n");
2223 System.out.println("由于" + name.substring(0, name.lastIndexOf(".")) + "文件过大,输出到文件Result中。");
24 result.close();
25 } else {
26 System.out.println("~~~~~~~~~~~~~~~~~~~~");
27 System.out.println(name.substring(0, name.lastIndexOf(".")));
28 System.out.println("number of the words:" + NumofWord);
29 System.out.println("totals:" + hm.size());
30for (Map.Entry<String, Integer> str : ll) {
31 System.out.println(str.getKey() + "——" + str.getValue());
32 }
3334 System.out.println("~~~~~~~~~~~~~~~~~~~~");
35 }
运行结果:
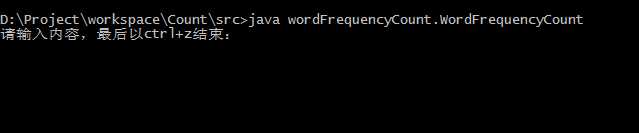
1.命令行标准输入界面:
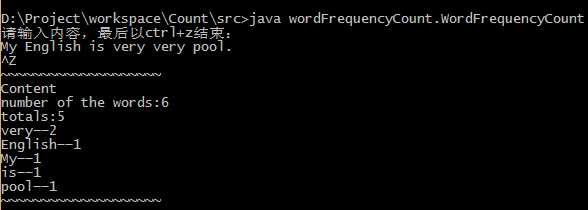
2.执行结果:
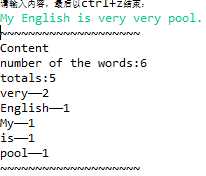
3.控制台界面:
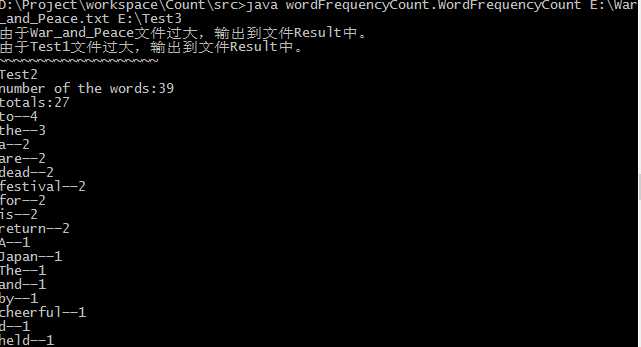
4.命令行传入文件:

5.同时传入大文件及文件夹:

6.重定向输入:
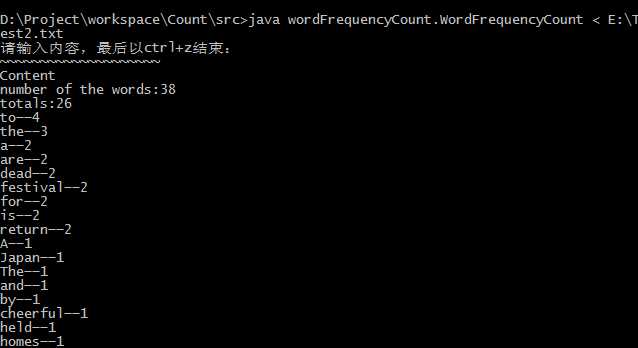
代码地址:
HTTPS https://coding.net/u/regretless/p/WordFrequencyCount/git
SSH git@git.coding.net:regretless/WordFrequencyCount.git
GIT git://git.coding.net/regretless/WordFrequencyCount.git
原文:http://www.cnblogs.com/regretless/p/5864907.html
内容总结
以上是互联网集市为您收集整理的Java实现的词频统计——功能改进全部内容,希望文章能够帮你解决Java实现的词频统计——功能改进所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。