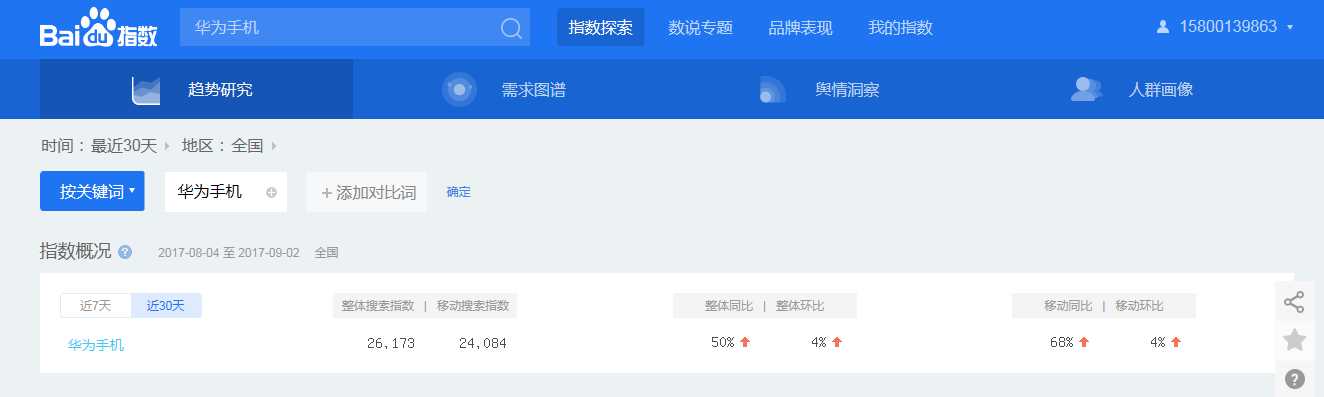
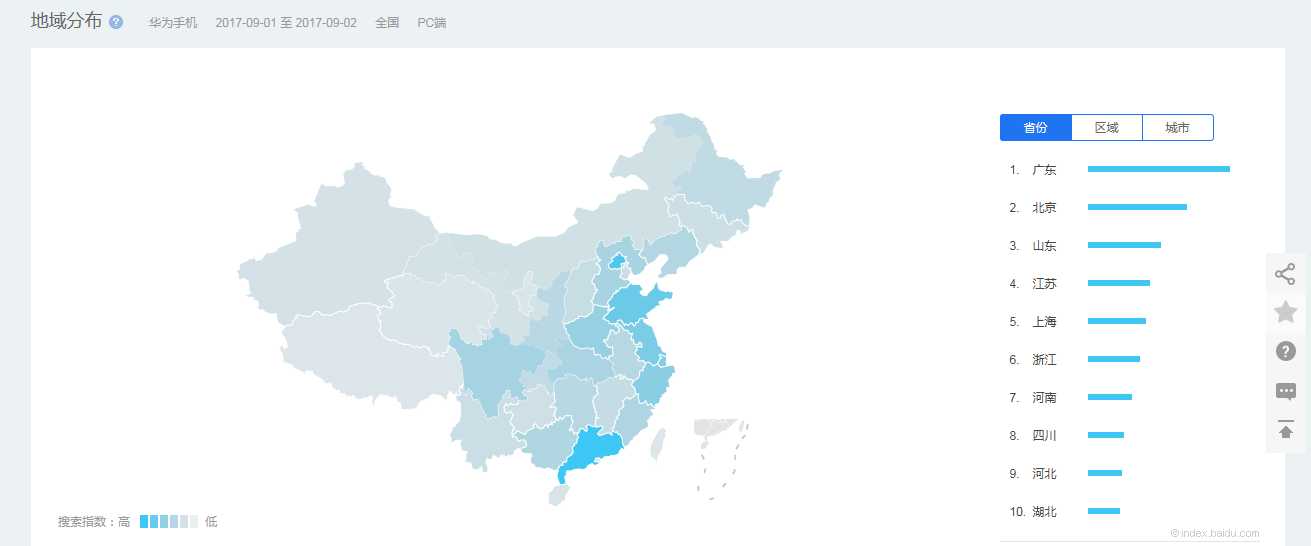
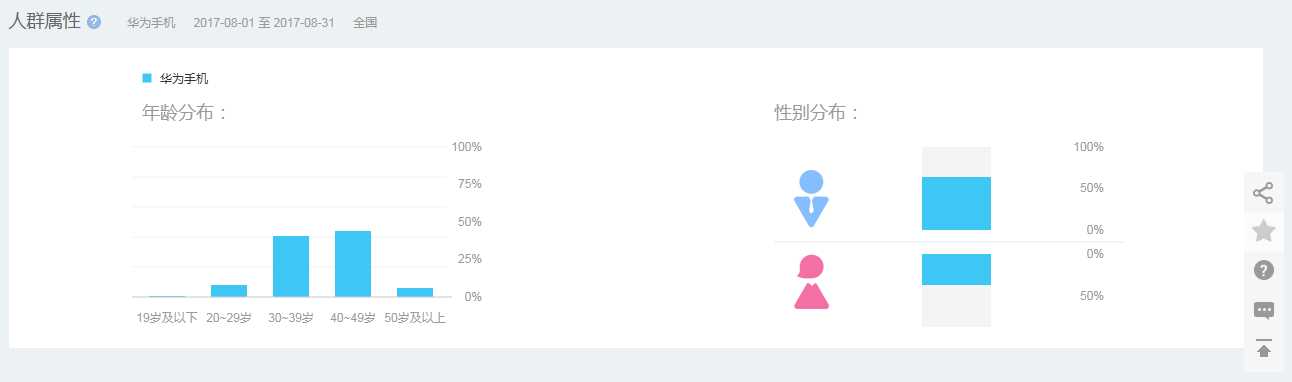
========== Spark 的监控方式 ==========1、Spark Web UI Spark 内置应用运行监控工具(提供了应用运行层面的主要信息--重要)2、Ganglia 分析集群的使用状况和资源瓶颈(提供了集群的使用状况--资源瓶颈--重要)3、Nmon 主机 CPU、网络、磁盘、内存(提供了单机信息)4、Jmeter 系统实时性能监控工具(提供了单机的实时信息)5、Jprofile Java ...
1.什么是大数据大数据是一个大的数据集合,通过传统的计算技术无法进行处理。这些数据集的测试需要使用各种工具、技术和框架进行处理。大数据涉及数据创建、存储、检索、分析,而且它在数量、多样性、速度方法都很出色,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。2.大数据测试类型测试大数据应用程序更多的是验证其数据处理,而不是测试软件产品的个别功能。当涉及到大...
HDFS中数据管理与容错1.数据块的放置 每个数据块3个副本,就像上面的数据库A一样,这是因为数据在传输过程中任何一个节点都有可能出现故障(没有办法,廉价机器就是这样的),为了保证数据不能丢失,所以存在3个副本,这样保证了硬件上的容错,保证数据传递过程中准确性。 3个副本数据,放在两个机架上。比如上面机架1存在2个副本,机架2存在1个副本。 (1)如果就像下面的DataNode1数据块无法使用了,可以在机架1上的Da...
在触发器里,有时候我们要判断更新的是不是某列,这个时候就可以使用 UPDATE()。测试:USE SKY
SELECT * FROM dbo.EmployeeIF EXISTS(SELECT name FROM sys.objects WHERE name=‘UpdateTrigger‘AND type=‘TR‘)
DROP TRIGGER UpdateTrigger-- UPDATE(COLUMNNAME) 函数的使用,如果 更新的 是 指定的COLUMN,就会返回 TRUE
GO
CREATE TRIGGER UpdateTrigger ON Employee
AFTER UPDATE
AS
IF(UPDATE(ENumber))RAISERROR(1...
erlang发送端:jiffy( https://github.com/davisp/jiffy) json转换brod( https://github.com/klarna/brod) 发送消息到kafka 消息中间件:kafkazookeeper 分布式组件kafka_tool kafka可视化工具 消息处理:flink(语言选用scala)原文:https://www.cnblogs.com/feapoi/p/13181760.html
第一节:Dubbo框架-基础概念淘宝网后台是Java写的 ==》dubbo高性能的服务框架ORM:单一应用、所有代码都在ORM里面、支持的并发1-10、并发太差MVC:分层 支持10-1000RPC:单个应用可以调用不同的服务、服务之间没有影响1000-10000+SOA:面向服务的、所有的服务找同一个注册中心、这样就可以对服务进行管理还可以做权重的调整、对服务做了一个管理的升级。 10000+的并发什么是dubbo?1、dubbo是一款分布式的服务框架2、高性能和透明...
本文以填报报表为例,通过分页的方式,来解决大数据集展示的问题。实现的思想就是通过在SQL里筛选部分数据库数据,以达到浏览器可以合理的展示报表页面。(数据分段,语句我这采用的是MYSQL,如果要用其他数据库,请查看FineReport帮助文档)步骤一:打开fenye.cpt文件。模板界面如下 650) this.width=650;" src="/upload/getfiles/default/2022/11/12/20221112120524003.jpg" />两个ds,和一部分数据,及隐藏的一行。 隐藏一行内...
5个用于移动开发的最流行数据库对比 五个数据库分别从数据库存储类型、优点、缺点、特点、API接口、操作示例六个方面进行阐述。BerkeleyDB数据库存储类型 relational,objects, key-value pairs, documents2. 优点a) 处理速度快。b) BDB并发高于RDBMS。c) 基于HASH支持select数据比RDBMS快。d) 高度可移植。不论是32bit,64bit,它可以运行在高端服务器、桌面系统、掌上电脑等。e) 函数库...
自然灾害似乎是不可避免的,让我们在大自然的手中感到脆弱。考虑到今天围绕着我们的所有数据和技术,这怎么可能呢?专家能否在预测方面做得更好,甚至试图避免更多自然灾害或更有效地减少资源损失?答案是肯定和否定。有时我们知道龙卷风会袭来,我们无法防止这种情况造成的损失。我们知道洪水会因飓风而发生,当地人可以努力有效地减少损失。但它们通常不能防止发生损害。我们知道可能会发生冰暴和冰雹风暴,但我们不能总是防止对...
1 Lambda架构介绍 Lambda架构划分为三层,分别是批处理层,服务层,和加速层。最终实现的效果,可以使用下面的表达式来说明。query = function(alldata)1.1 批处理层(Batch Layer, Apache Hadoop) 批处理层主用由Hadoop来实现,负责数据的存储和产生任意的视图数据。计算视图数据是一个连续的操作,因此,当新数据到达时,使用MapReduce迭代地将数据聚集到视图中。 将数据集中计算得到的视图,这使得它不会被频繁地...
大数据和Hadoop平台介绍定义大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获、管理和处理的数据集。这些困难包括数据的收入、存储、搜索、共享、分析和可视化。大数据要满足三个基本特征(3V),数据量(volume)、数据多样性(variety)和高速(velocity)。数据量指大数据要处理的数据量一般达到TB甚至PB级别。数据多样性指处理的数据包括结构化数据、非结构化数据(视频、音频...
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;namespace BigNumberMultiplication
{class Program{static void Main(string[] args){try{int first = 4916;int second = 12345;long result = first * second;Console.WriteLine(string.Format("{0} * {1} = {2}\n\n", first.ToString(), second.ToString(), result.ToString()));string firstStr = "100000000000000000000";string seco...
例1: 海量日志数据,提取出某日访问百度次数最多的那个IP(文件总量多大 -> 能一次载入内存吗 -> 怎么将文件化大为小,一般可以采取hash -> 然后怎么归并)1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
3.对于每一个小文件,可以构建一个IP为key,出现次数...
企业想要获得精准客户线索的问题主要表现为两个方面,一是目标人群不够精准;二是轻视用户画像。因此,精准获客成败的前提是,是否有足够精确的“用户画像”来做支撑。因此企业解决精准获客这两个痛点,便能快速获取精准用户。运营商大数据精准营销获客抓取客源具备以下优势第一,“竞争对手网页、竞争对手网站、手机app用户”运营商大数据都能进行抓取、获客盟运营商大数据精准营销获客(软件)具有很强的时效性。用户的消费行为极...
Apache Storm在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发...