强化学习快速入门
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了强化学习快速入门,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含912字,纯文字阅读大概需要2分钟。
内容图文

强化学习快速入门
- Q-learning:查表学习,每个行为在表中有对应的Q值,每一轮通过现实和估计的差距来更新表,具体的更新规则如下。值的注意的是,Q现实项中有一项为下一行为中最大奖励的估计。

- Sarsa:和Q-learning类似,不同点在于更新规则。

- Sarsa和Q-learning对比:为啥Q-learning会更勇敢一点?

- Sarsa(λ):Sarsa原算法缺陷是只有最后的一步被增强,加上拉姆达后,通向成功的每一步都有其对应的增强值,由lamada控制。

- DQN:传统算法的缺陷是表规模受限,神经网络的引入使得大规模行为和Q的映射的存储成为可能,其更新机制如下。其中,记忆重放和固态Q-目标是两个打乱相关性的技巧,这暂时不知道怎么理解,猜测是跟泛化能力有关。
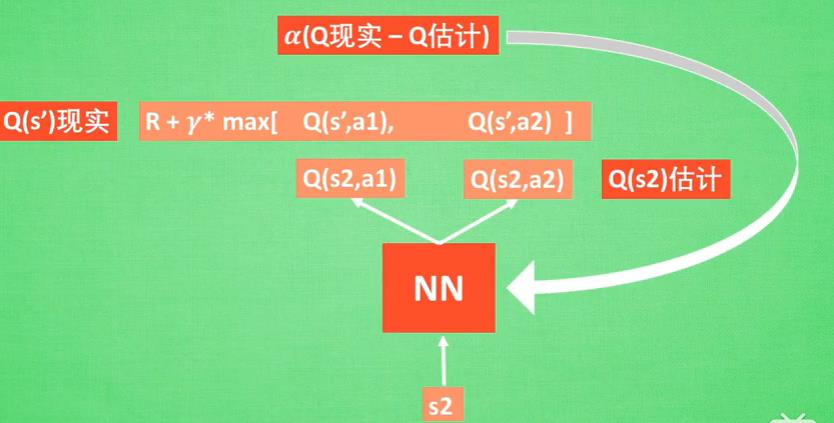
- Policy-Gradients:之前的方法都是只针对离散行为,当输出动作是连续时,Policy-Gradients就要上场了。利用神经网络来存储各种动作的概率,通过reward来更新各种动作的概率。
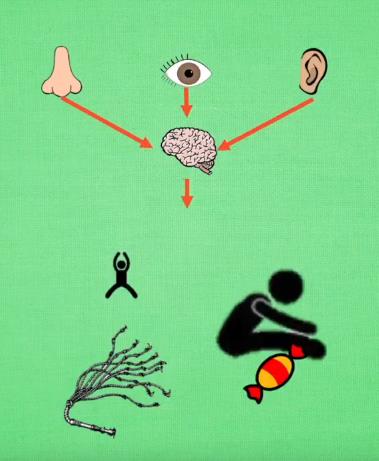

存在问题:回合制更新,只有到Reward那步才更新。
- Actor-Critic:类似GAN的思想,Actor是利用Policy-gradient的生成网络,Critic是负责对生成行为和环境评估Q值的网络。这样的操作使得其能够实现单步更新(critic评价状态和actor行为)
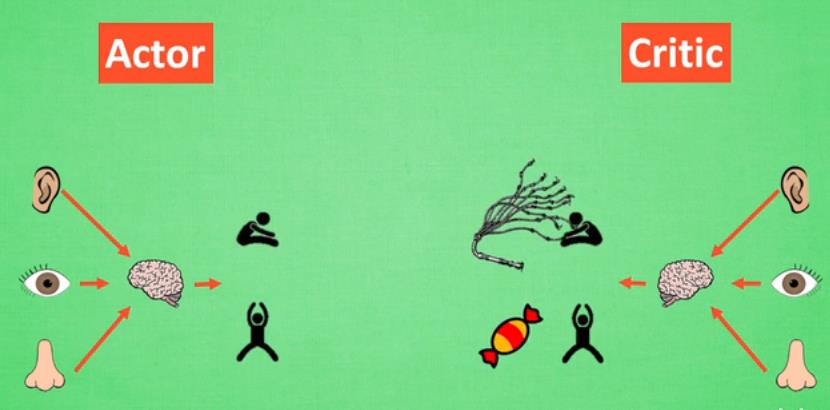
存在问题:Actor-Critic更新存在相关性?神经网络学不到东西?只能片面地看问题?连续状态下更新,相关性比较大,比较难收敛?
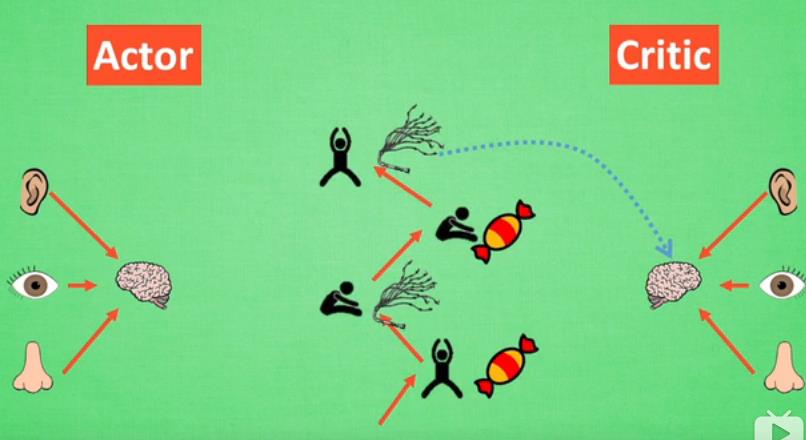
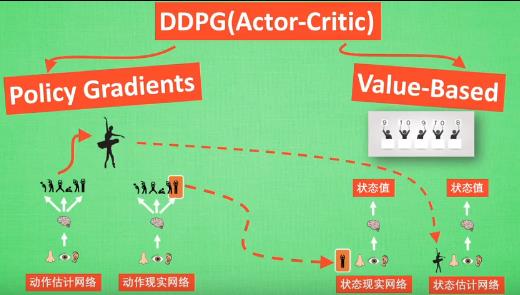
- DDPG:deep deterministic policy gradient,结合了DQN和policy gradient的优点,Actor和Critic各自有两个神经网络,一共四个网络,更新策略如下所示。
-
A3C:人多力量大,多个Actor一起学习。
-
PPO:解决学习率调节的问题,让新旧策略变化幅度控制住。
原文:https://www.cnblogs.com/YiXinLiu617/p/13155204.html
内容总结
以上是互联网集市为您收集整理的强化学习快速入门全部内容,希望文章能够帮你解决强化学习快速入门所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。