前言:以前只是调用过谱聚类算法,我也不懂为什么各家公司都问我一做文字检测的这个算法具体咋整的,没整明白还给我挂了哇擦嘞?讯飞和百度都以这个理由刷本宝,今天一怒把它给整吧清楚了,下次谁再问来!说不晕你算我输!一、解释: 二、推导: 三、步骤: 四、优缺点: 五、链接: https://www.cnblogs.com/pinard/p/6221564.html原文:https://www.cnblogs.com/EstherLjy/p/9432651.html
(一)K-means提到k-means不得不说的许高建老师,他似乎比较偏爱使用这种聚类方法,在N个不同场合听到他提起过,k-means通过设置重心和移动中心两个简答的步骤,就实现了数据的聚类。下面就来介绍下k-means算法。一、 数值属性距离度量度量数值属性相似度最简单的方法就是计算不同数值间的“距离”,如果两个数值之间“距离”比较大,就可以认为他们的差异比较大,而相似度较低;换而言之,如果两数值之间“距离”较小,可认为他...
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。它有点像全自动分类(类别体系是自动构建的)。聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好。本文要介绍一种称为K-均值(K-means)聚类的算法。之所以称之为K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。在介绍K-均值之前,先讨论一席簇识别(cluster identification)。簇识别给出聚类结果的含义。假定有一些...
引言:聚类是将数据分成类或者簇的过程,从而使同簇的对象之间具有很高的相似度,而不同的簇的对象相似度则存在差异。聚类技术是一种迭代重定位技术,在我们的生活中也得到了广泛的运用,比如:零件分组、数据评价、数据分析等很多方面;具体的比如对市场分析人员而言,聚类可以帮助市场分析人员从消费者数据库中分出不同的消费群体来,并且可以分析出每一类消费者的消费习惯等,从而帮助市场人员对销售做出更好的决策。所以,本篇...
使用不同的聚类准则,产生的聚类结果不同。** 聚类算法在现实中的应用**用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别基于位置信息的商业推送,新闻聚类,筛选排序图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段聚类算法的概念
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同...
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用课程大纲:基于密度的聚类算法简介DBSCAN算法的核心思想基本概念定义算法的流程实现细节问题实验OPTICS算法的核心思想基本概念定义算法的流程根据排序结果生成聚类结果实验Mean Shift算法的核心思想核函数概率密度估计算法的流程谱聚类算法的核心思想基本概念定义算法的流程算法评价指标应用聚类算...
版权声明:本文为博主原创文章,未经博主允许不得转载,或者转载的时候标出源文章网址。 一、原型聚类1.k均值聚类(k-means聚类) 其算法流程如下; 下面我们对西瓜数据进行分析,和举例,让我们比较容易的理解K-means聚类算法;2.学习向量化 算法思想如下:3.高斯混合聚类 下面还是一个列子:说实话前面一连串的理论知识也没很看懂。迷迷糊糊,列子还是很清楚的。 二、密度聚类-这里主要介绍DBSCAN算法 ...
前面和大家分享的分类算法属于有监督学习的分类算法,今天继续和小伙伴们分享无监督学习分类算法---聚类算法。聚类算法也因此更具有大数据挖掘的味道聚类算法本质上是基于几何距离远近为标准的算法,最适合数据是球形的问题,首先罗列下常用的距离:绝对值距离(又称棋盘距离或城市街区距离)Euclide距离(欧几里德距离,通用距离)Minkowski 距离(闵可夫斯基距离),欧几里德距离 (q=2)、绝对值距离(q=1)和切比雪夫距离(q=无穷大...
0 简介0.1 主题0.2 目标0.2.1 能掌握聚类的距离计算方式0.2.2 能够掌握聚类的各种方式1 聚类定义2 距离计算与相似度方法总结2.1 距离算法2.2 余弦相似度与Pearson相似度3 K-Means算法过程3.1 算法过程 3.2 代码实现# 导入包import numpy as np
import sklearn
from sklearn.datasets import make_blobs # 导入产生模拟数据的方法from sklearn.cluster import KMeans # 导入kmeans 类# 1. 产生模拟数据;random_state此参数让结果...
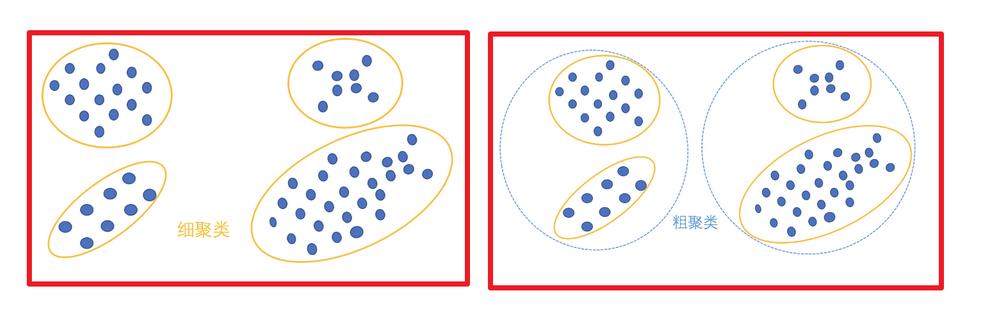
一、概念 与传统的聚类算法(比如K-means)不同,Canopy聚类最大的特点是不需要事先指定k值(即clustering的个数),因此具有很大的实际应用价值。与其他聚类算法相比,Canopy聚类虽然精度较低,但其在速度上有很大优势,因此可以使用Canopy聚类先对数据进行“粗”聚类,得到k值后再使用K-means进行进一步“细”聚类。这种Canopy+K-means的混合聚类方式分为以下两步: Step1、聚类最耗费计算的地方是计算对象相似性的时候,Canopy聚...
K-Means 概念定义:K-Means 是一种基于距离的排他的聚类划分方法。上面的 K-Means 描述中包含了几个概念:聚类(Clustering):K-Means 是一种聚类分析(Cluster Analysis)方法。聚类就是将数据对象分组成为多个类或者簇 (Cluster),使得在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。划分(Partitioning):聚类可以基于划分,也可以基于分层。划分即将对象划分成不同的簇,而分层是将对象分等级。排他(E...
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值,在 K-medoids算法中,我们将从当前cluster 中选取这样一个点——它到其他所有(当前cluster中的)点的距离之和最小——作为中心点。K-medodis算法不容易受到那些由于误差之类的原因产生的脏数据的影响,但计算量显然要比K-means要大,一般只适合小数据量。 K-medoid...
1、任意选取K个对象作为初始聚类中心(O1,O2,…Oi…Ok)。 2)将余下的对象分到各个类中去(该对象与哪一个聚类中心最近就被分配到哪一个聚类簇中); 3)对于每个类(Oi)中,顺序选取一个Or,重复步骤2,计算用Or代替Oi后的误差E=各个点到其对应的中心点欧式距离之和。选择E最小的那个Or来代替Oi。4)重复步骤3,直到K个medoids固定下来。using System;
using System.Collections.Generic;
using System.Linq;
using Syste...
//写个简单的先练习一下,测试通过
//k-均值聚类算法C语言版 #include <stdlib.h>
#include <stdio.h>
#include <time.h>
#include <math.h> #define TRUE 1
#define FALSE 0
int N;//数据个数
int K;//集合个数
int * CenterIndex;//初始化质心数组的索引
double * Center;//质心集合
double * CenterCopy;//质心集合副本
double * AllData;//数据集合
doub...
1.算法描述
最近在做AutoEncoder的一些探索,看到2016年的一篇论文,虽然不是最新的,但是思路和方法值得学习。论文原文链接 http://proceedings.mlr.press/v48/xieb16.pdf,论文有感于t-SNE算法的t-分布,先假设初始化K个聚类中心,然后数据距离中心的距离满足t-分布,可以用下面的公式表示:
其中 i表示第i样本,j表示第j个聚类中心, z表示原始特征分布经过Encoder之后的表征空间。
$q_{ij}$可以解释为样本i属于聚类j的概率,...