docker中spark+scala安装配置
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了docker中spark+scala安装配置,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1582字,纯文字阅读大概需要3分钟。
内容图文
 一、scala安装
一、scala安装首先下载scala压缩包
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz
解压
tar -zxvf scala-2.11.7.tgz
移动目录
mv scala-2.11.7 /usr/local/
改名
cd /usr/local/
mv scala-2.11.7 scala
配置环境变量
vim /etc/profile
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin

环境变量生效
source /etc/profile
查看scala版本
scala -version
分发scala到其他主机
scp -r /usr/local/scala/ root@Master:/usr/local/
scp -r /usr/local/scala/ root@Slave2:/usr/local/
二、spark安装
复制spark压缩包 到容器中
docker cp /root/spark-2.1.2-bin-hadoop2.4.tgz b0c77:/

查看并解压

在profile中添加spark环境变量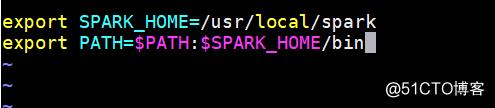
生效环境变量
source /etc/profile
编辑spark-env.sh
vim /usr/local/spark/conf/spark-env.sh
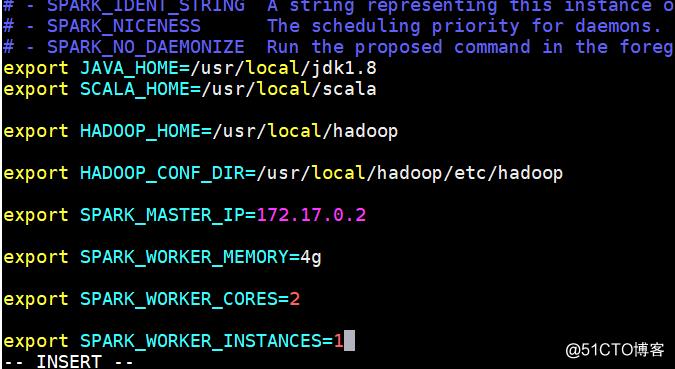
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
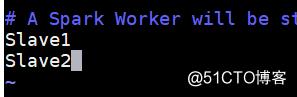
修改slaves文件
cp slaves.template slaves

vi conf/slaves
scp -r /usr/local/spark/ Master:/usr/local

scp -r /usr/local/spark/ Slave2:/usr/local

同时其他两个节点也要修改 /etc/profile
启动spark
./sbin/start-all.sh

成功打开之后使用jps在Master、Slave1和Slave2节点上分别可以看到新开启的Master和Worker进程。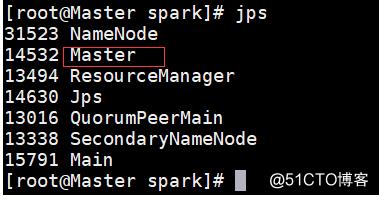
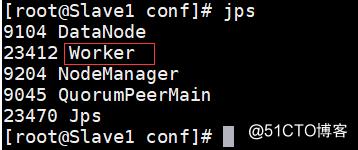
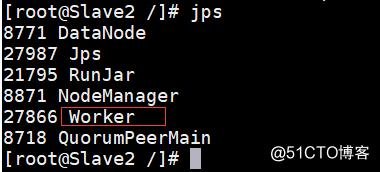
成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过
SparkMaster_IP:8080
端口映射:
iptables -t nat -A DOCKER -p tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:8080

此时我们可以通过映射到宿主机的端口访问,可见有两个正在运行的Worker节点。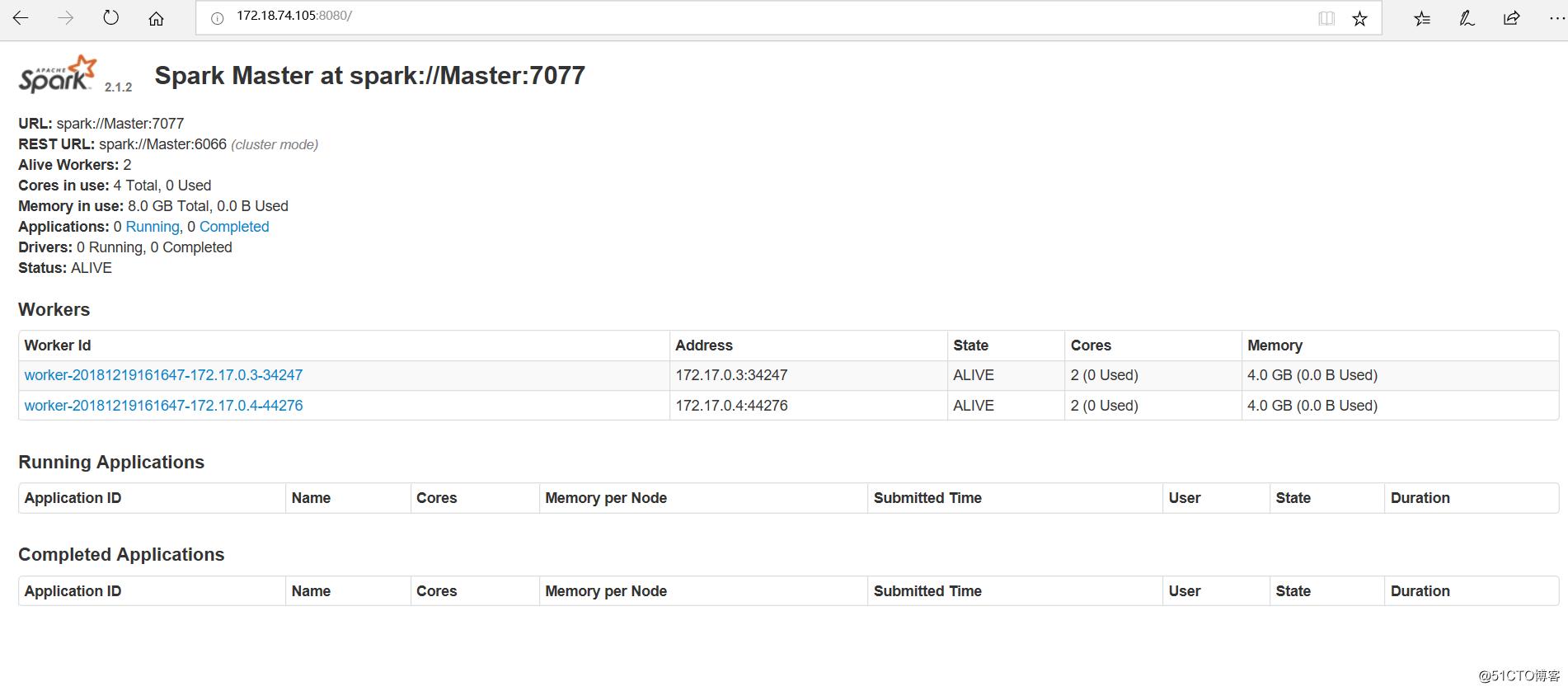
打开Spark-shell
使用
spark-shell
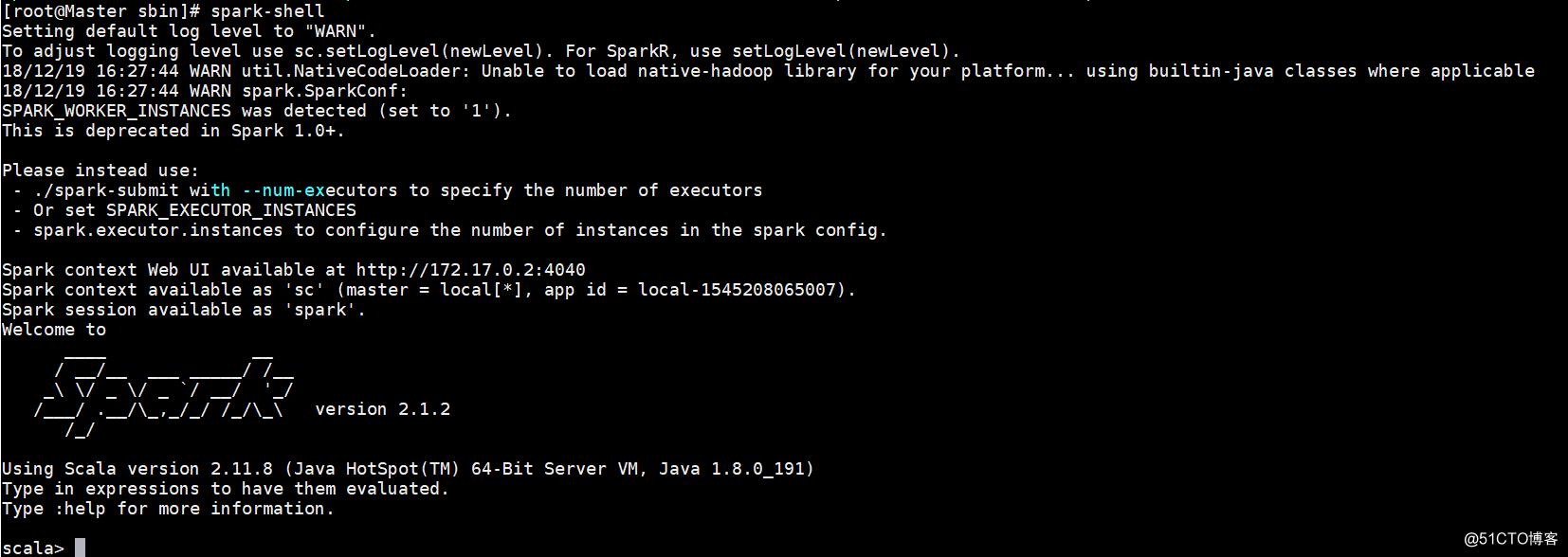
推出spark-shell的命令是“:quit”
因为shell在运行,我们也可以通过
SparkMaster_IP:4040(172.17.0.2:4040)
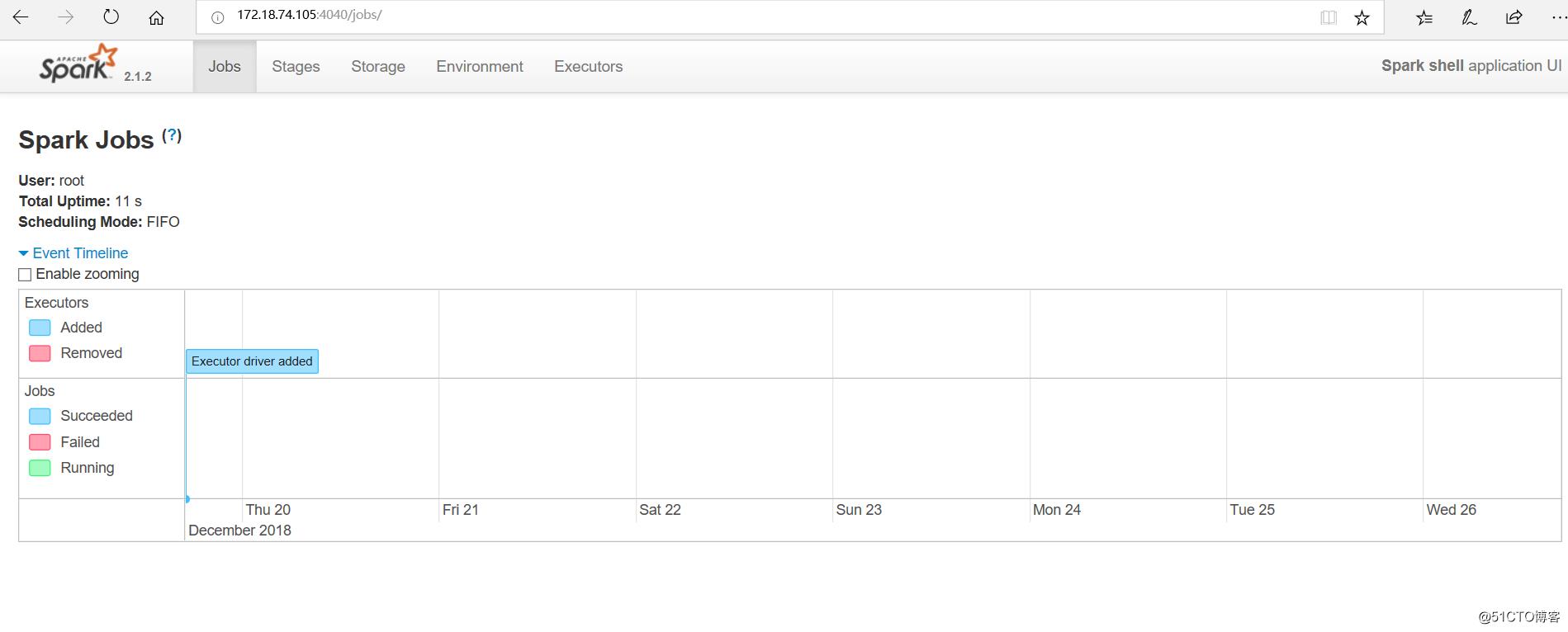
访问WebUI查看当前执行的任务。
先进行端口映射:
iptables -t nat -A DOCKER -p tcp --dport 4040 -j DNAT --to-destination 172.17.0.2:4040

原文:http://blog.51cto.com/13670314/2341236
内容总结
以上是互联网集市为您收集整理的docker中spark+scala安装配置全部内容,希望文章能够帮你解决docker中spark+scala安装配置所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。