DOM解析XML
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了DOM解析XML,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4022字,纯文字阅读大概需要6分钟。
内容图文

DOM的文档驱动
处理DOM的时候,我们需要读入整个的XML文档,然后在内存中创建DOM树,生成 DOM树上的每个Node对象
优点是:可以对XML文档进行增删改查的复杂操作,可以随时按照节点间的关系访问数据
缺点:
受内存容量限制,不能处理大的文档,由于没有索引机制,处理效率较低
DOM(文档对象模型),为XML文档的解析定义了一组接口,解析器读入整个文档,然后构造一个驻留内存的树结构,然后代码就可以使用DOM接口来 操组整个树结构,其他点如下:
优点:整个文档树都在内存当中,便于操作;支持删除、修改、重新排列等多功能。
缺点:将整个文档调入内存(经常包含大量无用的节点),浪费时间和空间。
使用场合:一旦解析了文档还需要多次访问这些数据,而且资源比较充足(如内存、CPU等)。
为了解决DOM解析XML引起的这些问题,出现了SAX。SAX解析XML文档为事件驱动
package com.huang;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
//测试DOM在XML文件上的CURD操作
//在XML中换行和标签中的内容在遍历过程中若不加判断则会输出#text
public class DOM {
public static void main(String[] args) {
//获取抽象类的实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try{
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse("./src/data.xml");
//遍历XML表中的内容
list(document);
//查询XML表中第一个Student的姓名
//find(document);
//在XML表中插入一个学生的信息
//add(document);
//在XML表中修改属性和元素值
//update(document);
//在XML表中删除一个学生或者属性
//del(document);
}catch(Exception e){
e.printStackTrace();
}
}
// 遍历xml中所有元素
// 在XML中换行和标签中的内容在遍历过程中若不加判断则会输出#text
public static void list(Node node) {
if (node.getNodeType() == node.ELEMENT_NODE) {
System.out.println(node.getNodeName());
}
NodeList nodelist = node.getChildNodes();
for (int t = 0; t < nodelist.getLength(); ++t) {
Node n = nodelist.item(t);
list(n);
}
return;
}
//在XML表中删除一个学生或者属性
public static void del(Document document) throws TransformerException{
Element node = (Element)document.getElementsByTagName("student").item(0);
//移除属性
node.removeAttribute("id");
//移除元素
Element name = (Element) node.getElementsByTagName("name").item(0);
node.removeChild(name);
//获得父亲结点
//Node parentnode = node.getParentNode();
//parentnode.removeChild(node);
//写入文件XML中
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult("src/data.xml"));
}
//在XML表中修改一个学生的信息
public static void update(Document document){
try{
Element stuName = (Element) document.getElementsByTagName("name").item(0);
stuName.setTextContent("zhang");
stuName.setAttribute("小名", "zhangsan");
//写入文件XML中
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult("src/data.xml"));
}catch(Exception e){
e.printStackTrace();
}
}
//在XML表中插入一个学生的信息
public static void add(Document document){
try{
Element stu = document.createElement("student");
//添加属性
stu.setAttribute("学生称号", "tiger");
Element name = document.createElement("name");
name.setTextContent("Ben");
Element studentid = document.createElement("studentid");
studentid.setTextContent("123321");
Element sex = document.createElement("sex");
sex.setTextContent("男");
stu.appendChild(name);
stu.appendChild(studentid);
stu.appendChild(sex);
//在根节点后面添加元素
document.getDocumentElement().appendChild(stu);
//写入文件XML中
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult("src/data.xml"));
}catch(Exception e){
e.printStackTrace();
}
}
//查询XML表中第一个student的姓名
public static void find(Document document){
NodeList nodelist = document.getElementsByTagName("student");
//类型强制转换转换成子类Element类型
Element stu = (Element)nodelist.item(0);
//获得属性值
System.out.println("id : "+ stu.getAttribute("id"));
NodeList name = stu.getElementsByTagName("name");
Element firstname = (Element)name.item(0);
//获得元素值
System.out.println("name : " + firstname.getTextContent());
}
}
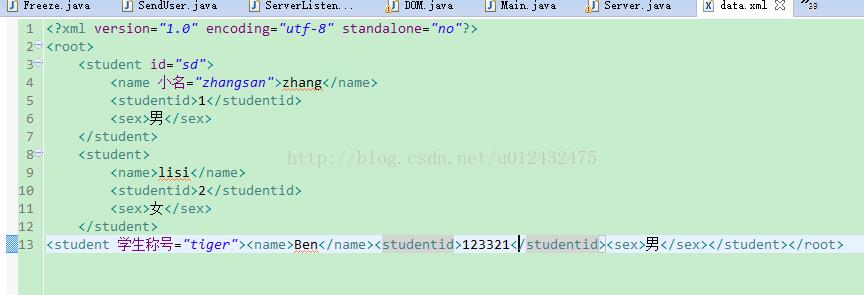
运行结果:
版权声明:本文为博主原创文章,未经博主允许不得转载。
原文:http://blog.csdn.net/u012432475/article/details/46701037
内容总结
以上是互联网集市为您收集整理的DOM解析XML全部内容,希望文章能够帮你解决DOM解析XML所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。