Python 实现关联规则分析Apriori算法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python 实现关联规则分析Apriori算法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2765字,纯文字阅读大概需要4分钟。
内容图文

#
-*- coding:utf-8 -*-
import
sys
reload(sys)
sys.setdefaultencoding(
"
utf8
"
)
def
load_data_set():
data_set = [
[‘beer‘, ‘baby diapers‘, ‘shorts‘]
, [‘baby diapers‘, ‘shorts‘]
, [‘baby diapers‘, ‘milk‘]
, [‘beer‘, ‘baby diapers‘, ‘shorts‘]
, [‘beer‘, ‘milk‘]
, [‘baby diapers‘, ‘milk‘]
, [‘beer‘, ‘milk‘]
, [‘beer‘, ‘baby diapers‘, ‘milk‘, ‘shorts‘]
, [‘beer‘, ‘baby diapers‘, ‘milk‘]
]
return data_set
def create_C1(data_set):
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1
def is_apriori(Ck_item, Lksub1):
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck notin Lksub1:
return False
return True
def create_Ck(Lksub1, k):
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck
def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
Lk = set()
item_count = {}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item notin item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk
def generate_L(data_set, k, min_support):
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data
def generate_big_rules(L, support_data, min_conf):
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule notin big_rule_list:
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list
if__name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)
for Lk in L:
print"="*50
print"frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport"print"="*50
for freq_set in Lk:
print freq_set, support_data[freq_set]
printprint"Big Rules"for item in big_rules_list:
print item[0], "=>", item[1], "conf: ", item[2]
输出结果:
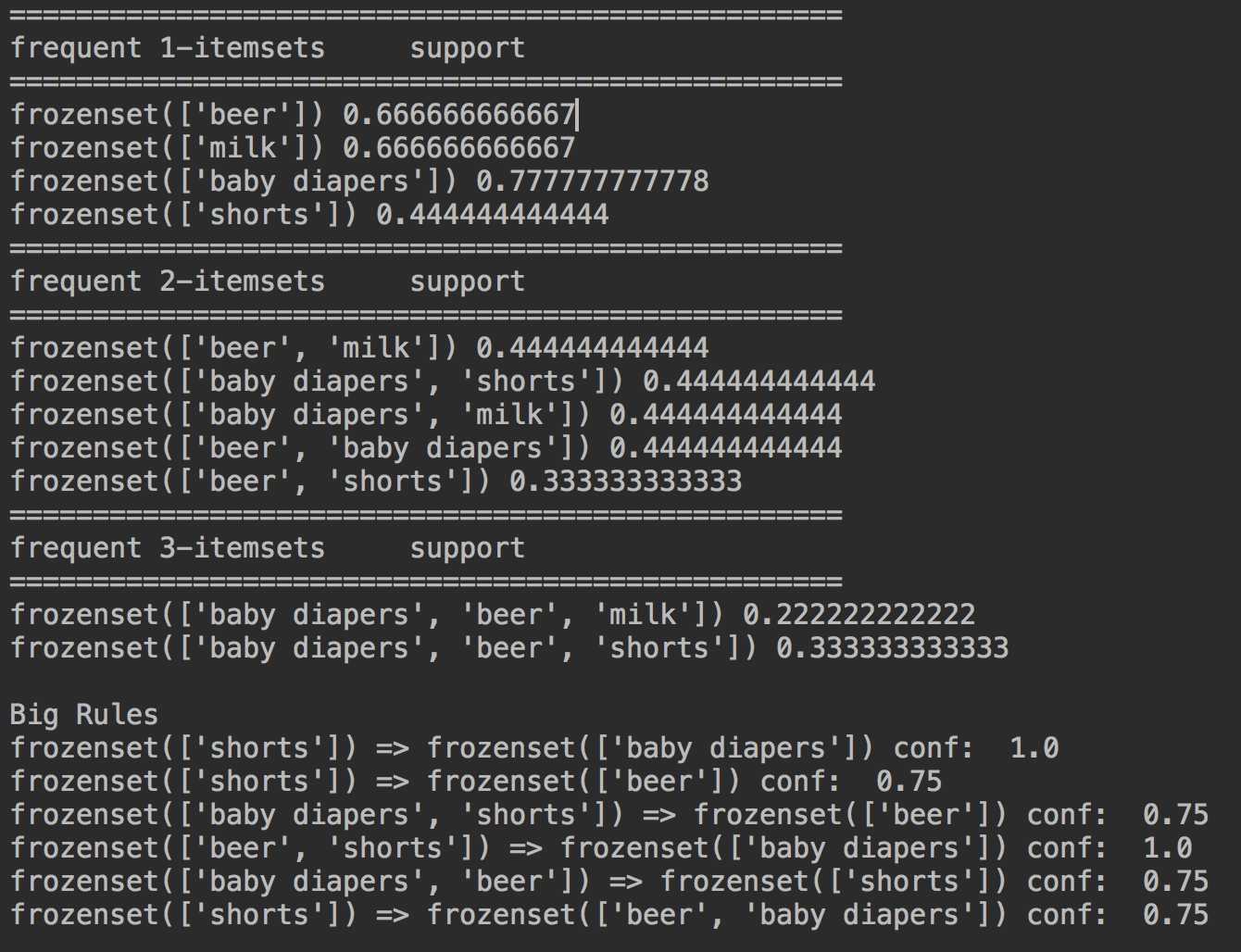
原文:https://www.cnblogs.com/RHadoop-Hive/p/9438914.html
内容总结
以上是互联网集市为您收集整理的Python 实现关联规则分析Apriori算法全部内容,希望文章能够帮你解决Python 实现关联规则分析Apriori算法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】