今晚九点|如何使用 Python 分析 web 访问日志?
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了今晚九点|如何使用 Python 分析 web 访问日志?,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2671字,纯文字阅读大概需要4分钟。
内容图文
 主题:如何使用 Python 分析 Web 访问日志
主题:如何使用 Python 分析 Web 访问日志
内容
Python 基础
字符串、字典、文件、时间
- Web 访问日志
实战
- 提问
主讲师:KK
多语言混搭工程师,热爱开源技术,喜欢GET新技能,5年 PHP、Python 项目开发经验,带领团队完成多个中、小型项目开发,对安全、云等多个领域富有浓厚兴趣,擅长于 WEB 安全开发、性能优化、分布式应用开发&设计等多方面,做事认真负责,乐于分享技能,现任 51Reboot.com Python 实战班讲师

任何语言都有使用场景,只有合适和不合适,没有好坏。语言是工具,用来描述让计算机如何工作,想法(思路&算法)是基础,也是重点。
字符串
像姓名、一句话描述这样的文
使用单引号、双引号、三个单引号或三个双引号引起来的一些字符
字符串有哪些函数
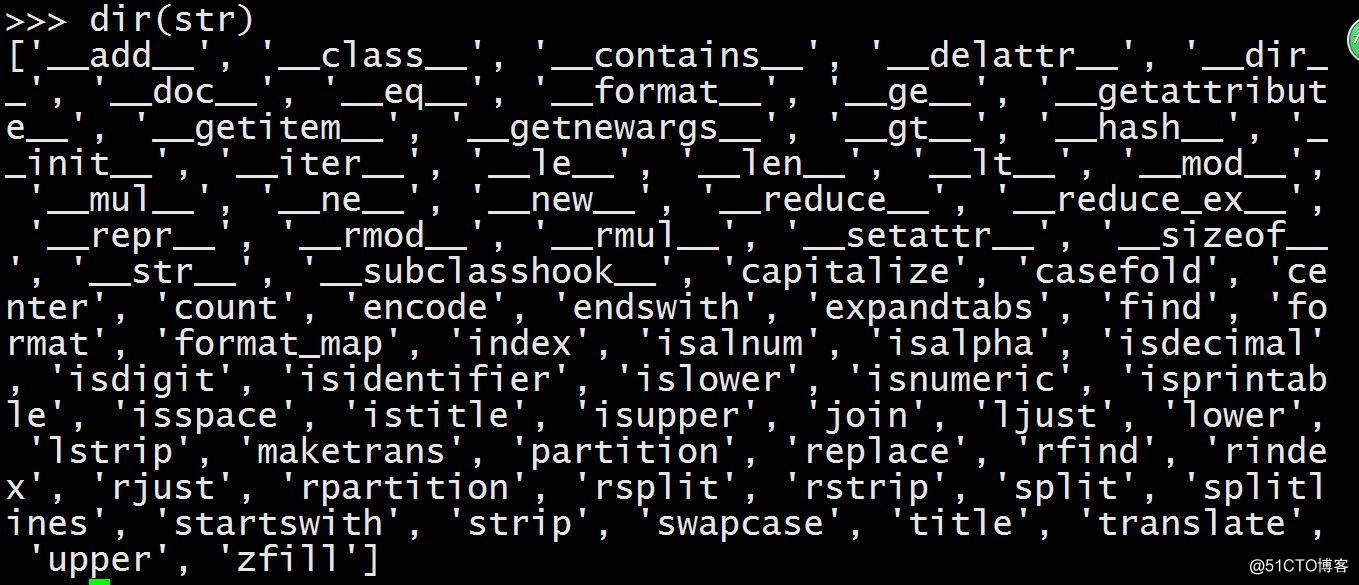
- split分隔字符串为list

- format 格式化字符串

字典定义
定义

使用大括号包含
每个元素为key:value的格式
- 元素之间使用逗号分隔
练习
一、统计 list 中每个元素出现的次数
languages = [‘python‘, ‘java‘, ‘python‘, ‘c‘, ‘c++‘, ‘go‘, ‘c#‘, ‘c++‘, ‘lisp‘, ‘c‘, ‘javascript‘, ‘java‘, ‘python‘, ‘matlab‘, ‘python‘, ‘go‘, ‘java‘]
提示:
统计结果为 element:count 的形式,统计结果采用 dict 从左到右依次遍历 list 中元素,判断是否在 dict 中,如果不在则将 element 存入 dict 并设置 count 为 1,否则将 dict中element 对应的 count 加 1 后再存储到dict中。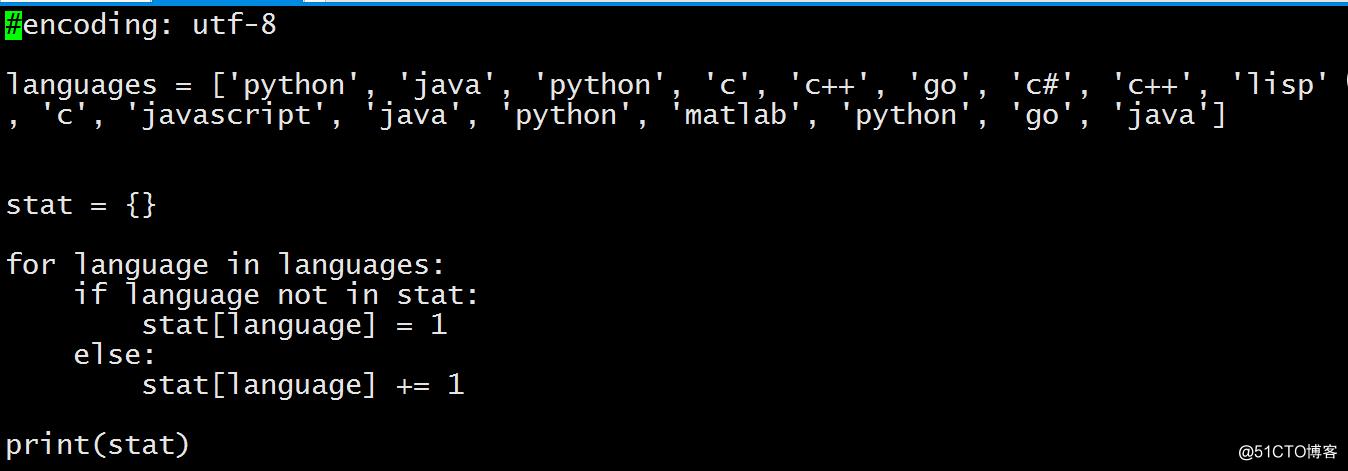
二、统计文章中每个英文字母出现的次数
article = ‘I was not delivered unto this world in defeat, nor does failure course in my veins. I am not a sheep waiting to be prodded by my shepherd. I am a lion and I refuse to talk, to walk, to sleep with the sheep. I will hear not those who weep and complain, for their disease is contagious. Let them join the sheep. The slaughterhouse of failure is not my destiny.‘
提示:判断是否为英文单词
- if (element > ‘a’ and element < ‘z’) or (element > ‘A’ and element < ‘Z’)

字典的 Key
Key 必须为不可变数据类型
数字
整数
浮点数
字符串
布尔类型
列表 X
元组
子元素必须也不可变(“a”, “b”)
("a", ["b“]) X
- 字典 X
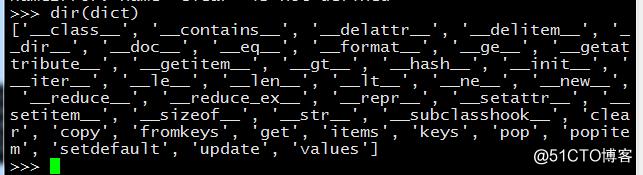
字典有哪些函数
文件
自己在电脑上打开 word 文件的操作顺序
在计算机盘符中找到对应的文件
鼠标双击打开文件(选择查阅的工具)
查阅文件内容/编辑文件内容
如果有编辑文件内容保存文件
- 关闭文件
文件操作
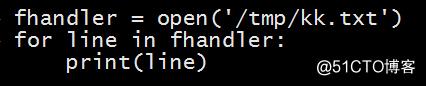
- 打开文件
- fhandler = open(path, mode, …)
- path 为文件路径
- mode 为打开文件方式及文件类型
| mode | 打开文件方式 |
|---|---|
| r | 读(默认) |
| w | 写 |
| x | 创建并写 |
| a | 追加 |
| r+ | 读写 |
| w+ | 写读 |
| x+ | 创建并写读 |
| a+ | 追加读 |
- 关闭文件
fhandler.close()
| mode | 文件类型 |
|---|---|
| t | 文本(默认) |
| b | 二进制 |
- 遍历文件内容
时间
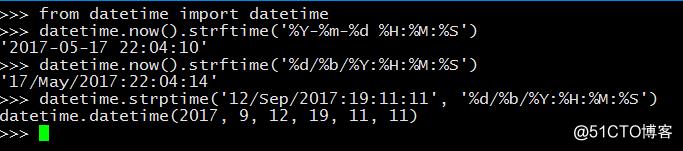
Web 访问日志
Web 访问日志是 Web 服务器记录的网站被访问的过程日志
日志属性
什么时候
什么人
通过什么工具
以什么方式
- 访问了什么资源
- 结果是什么(状态/返回数据大小)
Web 访问日志日志格式
- 通用日志格式
127.0.0.1 - - [14/May/2017:12:45:29 +0800] "GET /index.html HTTP/1.1" 200 4286
远程 - - 主机 IP 请求时间 时区 方法 资源 协议 状态码 发送字节
- 组合日志格式
127.0.0.1 - - [14/May/2017:12:51:13 +0800] "GET /index.html HTTP/1.1" 200 4286 "http://127.0.0.1/" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36“
远程主机 IP - - 请求时间 时区 方法 资源 协议 状态码 发送字节 referer 字符 浏览器信息
Web访问日志日志示例

实战
统计以下数据
需要根据IP获取地理位置
每天的日志中每行流量之和、总的流量之和(每天流量之和)
每种状态码出现的次数
每天的不重复的IP的数量、总的不重复的IP数量(每天不重复的IP数量 之和???)
每天的日志行数、日志的总行数(每天的日志行数之和)
统计每天的点击量、总点击数量
统计每天的浏览者数量、总浏览者数量
统计总状态码分布
统计每天流量大小、总的流量大小
- 统计访问地域分布及访问次数 TOP20
运行
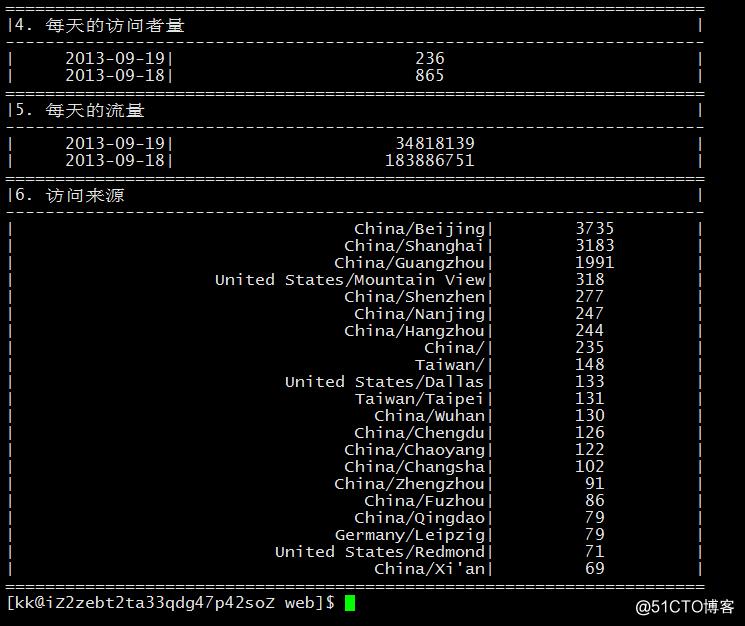
分析
按天统计
每天日志行数
每天浏览每个 IP 的访问次数
每天访问者数量 = 每天出现 IP 组成集合的数量
每天状态码出现次数
- 每天流量总数
总统计
总日志行数 = 每天日志行数之和
- 总访问者数量 = 所有出现 IP 组成的集合数量
地域分布
所有出现 IP 的访问次数 排序取 TOP20
- 根据 IP 查找地理位置
代码
统计每天信息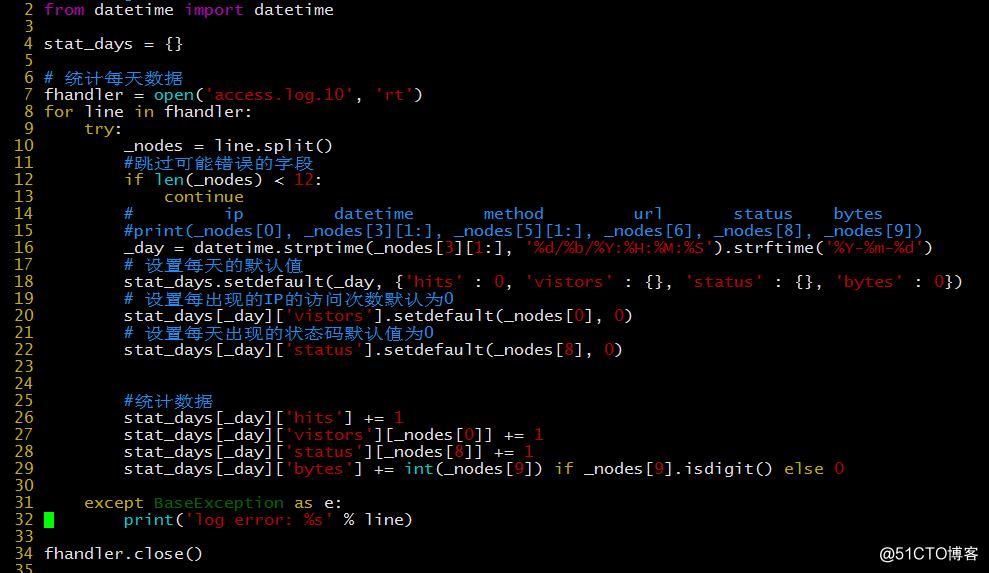
统计总数据
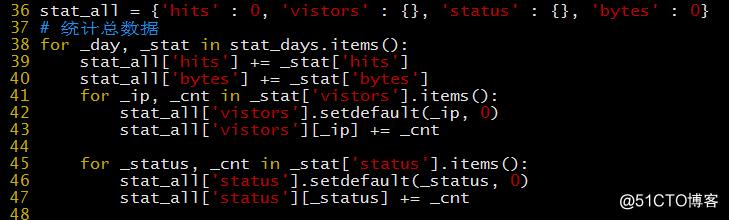
统计区域数据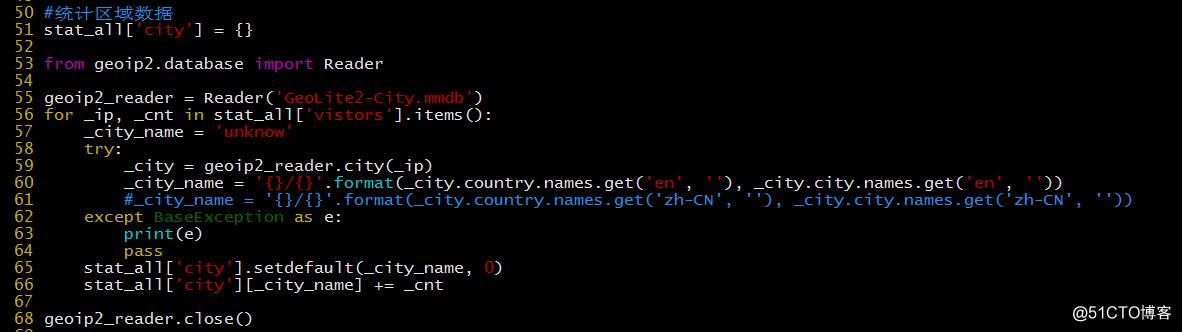
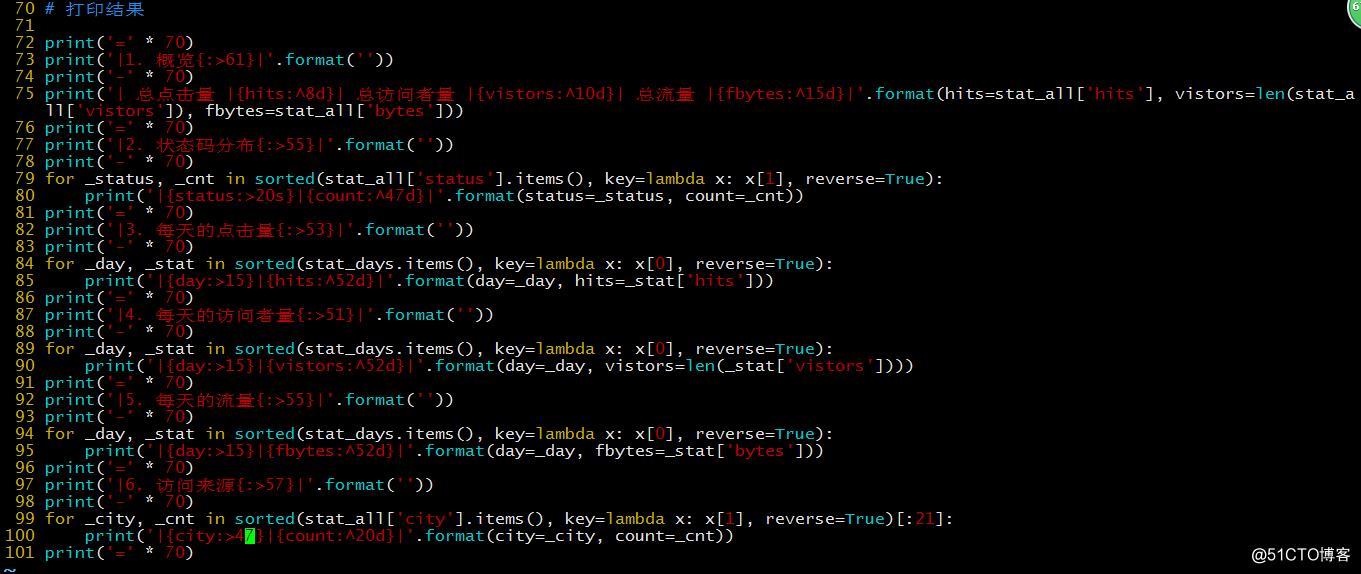
打印结果
还可以做哪些?
统计每天每个 url 访问的次数?
最近 24 小时访问/流量趋势图(每 5-10 分钟粒度)
每天浏览器分布图
每天访问文档分布图
每天 js、css、图片等静态文档流量统计
……
web 饼状图、曲线图、柱状图、地图
……
- 通过机器学习监督学习方法对访问进行攻击检测
网络直播分享
报名方式:加小助手(小月)微信:1902433859 备注公开课进入直播分享群
原文:http://blog.51cto.com/51reboot/2087109
内容总结
以上是互联网集市为您收集整理的今晚九点|如何使用 Python 分析 web 访问日志?全部内容,希望文章能够帮你解决今晚九点|如何使用 Python 分析 web 访问日志?所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。