一个很小的爬虫,演示了爬一首词,后对数据进行清洗,后存进txt文件中去import requests,refrom bs4 import BeautifulSoupurl="https://trade.500.com/sfc/"url2="https://so.gushiwen.org/shiwenv_4d3b4d132c82.aspx"req=requests.get(url2)if req.status_code==200: if req.encoding=="gbk" or req.encoding=="ISO-8859-1": html = req.content.decode("GBK") else: html=req.text soup = BeautifulSoup(...
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看到,每一页有15篇文章随便打开一个div来看,可以看到,蓝色部分除了一个文章标题以外没有什么有用的信息,而注意红色部分我勾画出的地方,可以知道,它是指向文章的地址的超链接,那么爬虫只要捕捉到这个地址就可以了。接下来在一个...
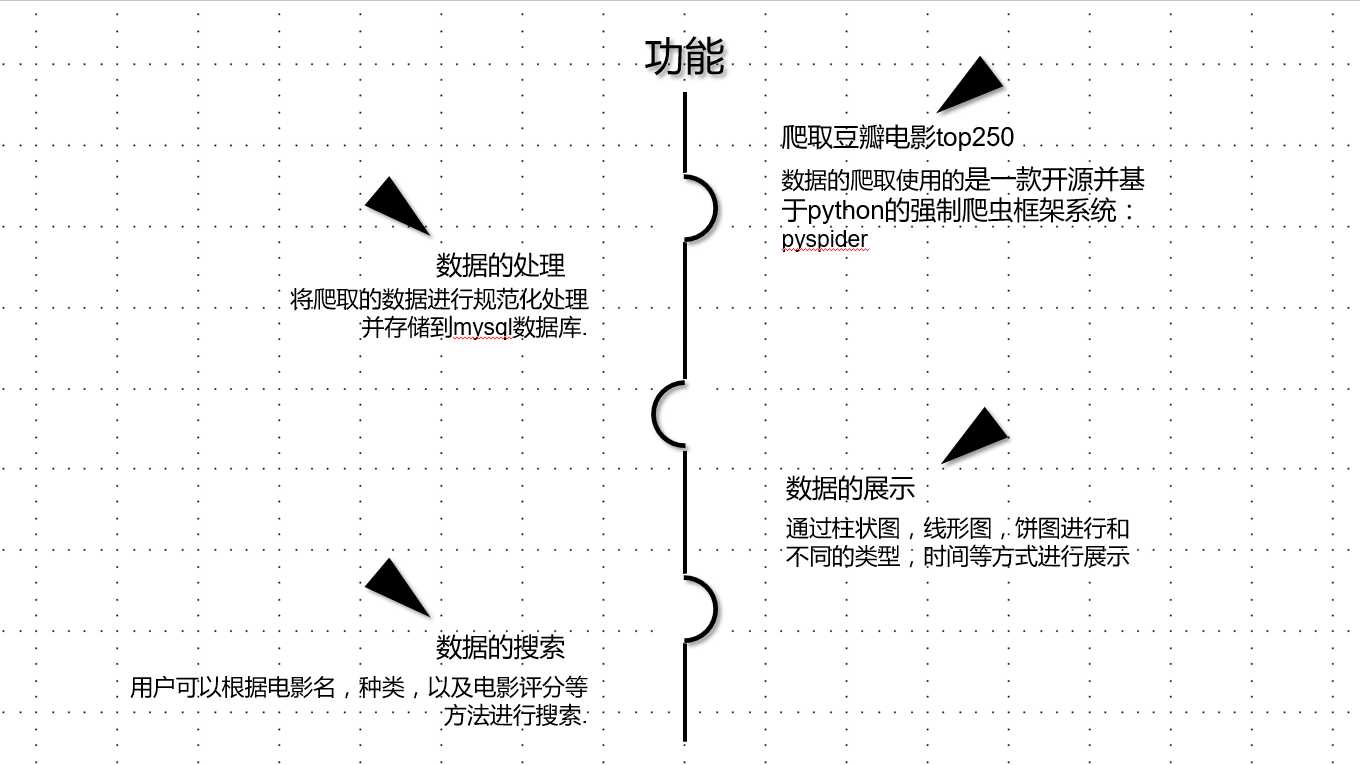
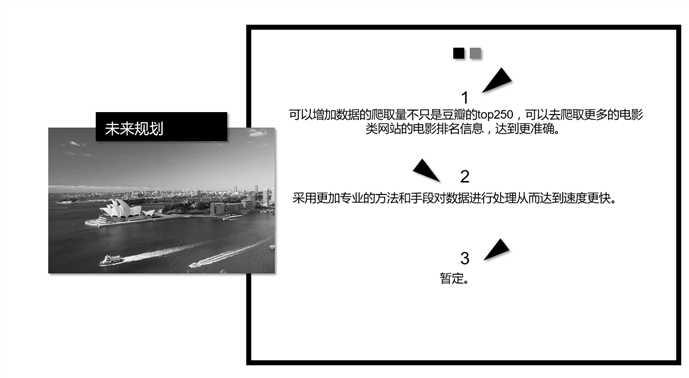
项目介绍:功能需求: 面向用户:未来规划: 以上内容源自于在课上做的ppt内容,绝对本组ppt,并且真实有效。原文:http://www.cnblogs.com/shy6002/p/8038808.html
Link ExtractorsLink Extractors 是那些目的仅仅是从网页(scrapy.http.Response
' ref='nofollow'>
scrapy.http.Response 对象)中抽取最终将会被follow链接的对象?
Scrapy默认提供2种可用的 Link Extractor, 但你通过实现一个简单的接口创建自己定制的Link Extractor来满足需求?
每个LinkExtractor有唯一的公共方法是 extract_links ,它接收一个 Response' ref='nofollow'>
Response 对象,并返回一个
scrapy.link.Link 对象?Link ...
??鉴于现阶段国内的搜索引擎还用不上Google, 笔者会寻求Bing搜索来代替。在使用Bing的过程中,笔者发现Bing的背景图片真乃良心之作,十分赏心悦目,因此,笔者的脑海中萌生了一个念头:能否自己做个爬虫,可以提取Bing搜索的背景图片并设置为Windows的电脑桌面呢?Bing搜索的页面如下:
??于是在一个风雨交加的下午,笔者开始了自己的探索之旅。当然,过程是曲折的,但笔者尝试着能把它讲得简单点。
??首先,我们需要借助一些Pytho...
前面我们简述了使用Python自带的urllib和urllib2库完成的一下爬取网页数据的操作,但其实能完成的功能都很简单,假如要进行复制的数据匹配和高效的操作,可以引入第三方的框架,例如Scrapy便是比较常用的爬虫框架。 一、Scrapy的安装:1.最简单的安装方式: 根据官方主页的指导:http://www.scrapy.org/ 使用pip来安装python相关插件其实都很简单,当然用这个办法安装Scrapy也是最为简单的安装方式,仅需在命令行窗口...
------------------3.10----------------------在爬取某个网站时,直接用lxml.etree对response.content进行分析拿到的数据,与保存到本地后再分析拿到数据不一致 1 url = ‘http://op.hanhande.com/mh/‘ 2 HEADERS = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; rv:51.0) Gecko/20100101 Firefox/51.0 ‘}3 4#直接分析 5 response = requests.get(url, headers=HEADERS)6 body = etree.HTML(response.content)7 us = body....
思路:查询数据库中信息,查询出id和name把那么进行分词存入文件 package com.open1111.index;import java.io.IOException;import java.nio.file.Paths;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import org.apache.log4j.Logger;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Doc...
有时候在我们设计利用requests抓取网页数据的时候,会发现所获得的结果可能与浏览器显示给我们的不一样:比如说有的信息我们通过浏览器可以显示,但一旦用requests却得不到想要的结果。这种现象是因为我们通过requests获得的都是HTML源文档,而浏览器中见到的页面数据都是经过JavaScript处理的,而这些处理的数据可能是通过Ajax加载、本身包含于HTML中或是经过JavaScript自动生成。由Web发展趋势来看,越来越多的网页都通过Ajax加载...
爬虫(二)urllib库数据挖掘1、第一个爬虫 1from urllib import request2 3 url = r‘http://www.baidu.com‘ 4 5# 发送请求,获取 6 response = request.urlopen(url).read()7 8# 1、打印获取信息 9print(response)
1011# 2、打印获取信息的长度12print(len(response)) 2、中文处理 1# 数据清洗,用【正则表达式】进行数据清洗 2from urllib import request3import re # 正则表达式模块 4 5 url = r‘http://www.baidu.com‘ 6 ...
哔哩哔哩热榜爬虫程序及数据处理 完整的代码与结果在最下面 一、设计方案 1.爬虫的目标是哔哩哔哩排行榜上视频的信息(https://www.bilibili.com/ranking/all/0/1/7) 2.爬取的内容包括网页上显示的所有内容,有排名标题,播放量,弹幕数,up,得分以及视频的url3.设计方案:根据作业的要求,制作爬虫程序爬取信息并进行数据处理,整个程序分成四个部分,包括数据爬取:(get_rank),数据清洗与处理:(rubbish),文本分析生成...
request得到和浏览器数据不同数据加载是异步加载方式,原始页面不包含数据,加载完后会会再向服务器请求某个接口获取数据,然后数据再被处理才呈现到网页上,这其实就是发送了一个 Ajax 请求。这样Web 开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的压力。因此遇到这种情况,用requests模拟ajax请求6.1 Ajax 1- 介绍Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。是利用 JavaScript 在...
#!/usr/bin/python
#encoding=utf-8
import urllib2
import urllib
import re
import thread
import time class Spider(object):
def __init__(self):
self.page = 1
self.pages = []
self.enable = False
def Start(self):
self.enable = True
page = self.page
thread.start_new_thread(self.LoadPage,())
while self.enable:
...
import requests
from bs4 import BeautifulSoup
import re
response = requests.get(url="https://www.autohome.com.cn/news/")
response.encoding= response.apparent_encoding
suop = BeautifulSoup(response.text,features="lxml")
target = suop.find(id="auto-channel-lazyload-article")
li_list = target.find_all("li")
for i in li_list:a = i.find("a")if a:print(a.attrs.get("href"))test = a.find("h3").texttx = re...
1import requests2import re3 html = ‘http://www.jingcaiyuedu.com/book/317834.html‘ 4 response = requests.get(html)5‘‘‘while(str(response)!="<Response [200]>"):6 response = requests.get(html)7 print(response)8‘‘‘ 9 response.encoding = ‘utf-8‘10 html = response.text
11 title =re.findall(r‘<meta property="og:novel:book_name" content="(.*?)"/>‘,html)[0]
12 dl = re.findall(r‘<dl id="l...