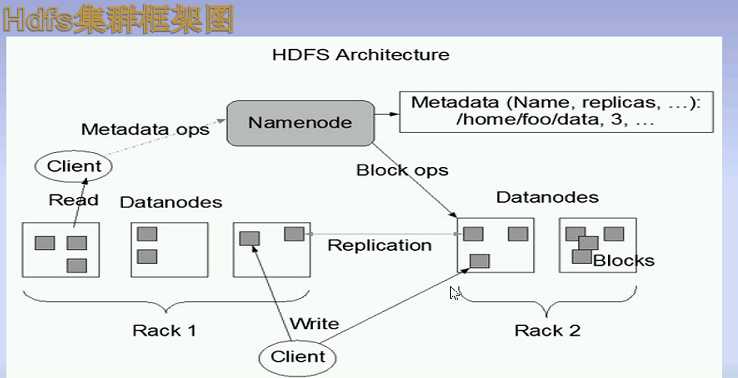
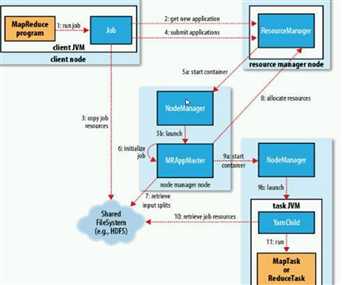
1.hadoop是一份分布式的基础架构(分服务器部署)2.优点:可扩展3.NameNode:名称节点,管理文件系统DataNode:数据节点,文件系统的工作者4.HDFS:不适合低延迟的数据访问,不适合大量的小文件。默认128MB5.主要的是ResourceManger和NodeManager 原文:https://www.cnblogs.com/sunxiaoyan/p/9216664.html
转载自http://blessht.iteye.com/blog/2095675Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身。 《Hadoop基础教程》是我读的第一本Hadoop书籍,当然在线只能试读第一章,不过对Hadoop历史、核心技术和应用场景有了初步了解。 Hadoop历史 雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引...
Hadoop基础-HDFS的写入过程 作者:尹正杰版权声明:原创作品,谢绝转载!否则将追究法律责任。原文:https://www.cnblogs.com/yinzhengjie/p/9136447.html
我使用了4台虚拟机centos7来搭建环境,2个主结点(一般是一个,但为了体验zookeeper,万一其中一个master挂掉呢,另外一个会自动启动接管),2个从结点注意:下面的配置主要以主节点为例进行说明第一步:同步四台机器的时钟 sudo yum install ntpdate,确保已安装ntpdate,分别运行sudo ntpdate cn.pool.ntp.org第二步:设置主机名修改/etc/sysconfig/network文件,NETWORKING = yesHOSTNAME = master(主节点)其实在centos7下面...
Hadoop历史 雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 随后在2003年Google发表了一篇技术学术论文谷歌文件系统(GFS)。GFS也就是google File System,google公司为了存储海量搜索数据而设计的专用文件系统。 2004年Nutch创始人Doug Cutting基于Google的GFS论文实现了分布式文件存储系统名为NDFS。 ...
目录HDFS项目实战需求分析代码框架编写上下文处理类实现功能实现HDFS项目实战需求分析使用HDFS Java API 才完成HDFS文件系统上的额文件的词频统计例子/test/1.txt
==> ‘ hello world‘/test/2.txt
==> ‘ hello world world‘得出 hello 两个, world 三个代码框架编写1:读取HDFS上的文件2:词频统计3:将处理的结果混存起来 Map4:将结果输出到HDFS上下文package com.bigdata.hadoop.hdfs;import java.util.HashMap;
import java.u...
1.基本语法bin/hadoop fs 具体命令 OR bin/hdfs dfs 具体命令dfs是fs的实现类。 2.命令大全 [atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop fs[-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-checksum <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] <localsrc> ... <dst>][-copyToLocal...
距离上次博客时间已经9天,简单记录下这几天的学习过程2020-02-15 10:38:47一、Linux学习关于Linux命令,我在之前就已经学过一部分了,所以这段时间的linux学习更多的是去学习Linux系统的安装以及相关配置多一些,命令会一些比较常用的就够了,下面记录下安装配置Linux系统时的注意事项。 这里配置的虚拟机的内存为4g使用的 CentOS-6.5-x86_64-minimal.iso 映射文件在进入linux系统中时,需要将虚拟机的主机名修改成自己想要的名...
认知和学习Hadoop,我们必须得了解Hadoop的构成,我根据自己的经验通过Hadoop构件、大数据处理流程,Hadoop核心三个方面进行一下介绍:Hadoop组件650) this.width=650;" src="/upload/getfiles/default/2022/11/7/20221107084403110.jpg" title="Hadoop组件.png" />由图我们可以看到Hadoop组件由底层的Hadoop核心构件以及上层的Hadoop生态系统共同集成,而上层的生态系统都是基于下层的存储和计算来完成的。首先我们来了解一下核心...
11.jpg (17.57 KB, 下载次数: 61)下载附件2015-6-24 13:36 上传课程讲师:Cloudy课程分类:大数据适合人群:中级课时数量:120课时更新程度:完毕服务类型:A类(就业服务类课程)用到技术:Hadoop MapReduce HDFS HBASE 部署Hadoop集群涉及项目:日志分析,电商 北风首次推出包跳槽大数据高端培训课程,包学会,包跳槽,包高薪, 在线互动+讲师直播大数据课程,4周助你突破职业瓶颈,做企业核心技术骨干。 课程共分为两大阶段...
基本概念 模块 RPC 通常采用客户机/服务器模型。请求程序是客户机,服务提供程序则是一个服务器。包括以下几个模块 通信模块:两个相互协作的通信模块实现请求-应答协议。同步方式和异步方式。 Stub程序:客户端和服务器端均包含Stub程序,代理程序。它使得基本概念
模块
RPC通常采用客户机/服务器模型。请求程序是客户机,服务提供程序则是一个服务器。包括以下几个模块
通信模块:两个相互协作的通信模块实现请求-应答协议。同步...
一:测试数据1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C...
在历经千辛万苦后,终于把所有的东西都配置好了。
下面开始介绍pyspark的一些基础内容,以字数统计为例。
1)在本地运行pyspark程序
读取本地文件
textFile=sc.textFile("file:/usr/local/spark/README.md")
textFile.count()
读取HDFS文件
textFile=sc.textFile(hdfs://master:9000/user/*********/wordcount/input/LICENSE.txt")
textFile.count()
2)在Hadoop YARN运行pyspark
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop py...
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插...
【原创 Hadoop&Spark 动手实践 9】SparkSQL程序设计基础与动手实践(上)
目标:
1. 理解Spark SQL最基础的原理
2. 可以使用Spark SQL完成一些简单的数据分析任务
3. 可以利用Spark SQL完成一个完整的案例
【原创 Hadoop&Spark 动手实践 9】Spark SQL 程序设计基础与动手实践(上)标签:程序设计 使用 程序 动手 blog .com ima 技术分享 数据 本文系统来源:http:/...