Hadoop之Reduce侧的联结
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop之Reduce侧的联结,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5407字,纯文字阅读大概需要8分钟。
内容图文

理解其就像关系型数据库中的链接查询一样,数据很多的时候,几个数据文件的数据能够彼此有联系,可以使用Reduce联结。举个很简单的例子来说,一个只存放了顾客信息Customer.txt文件,和一个顾客相关联的Order.txt文件,要进行两个文件的信息组合,原理图如下: 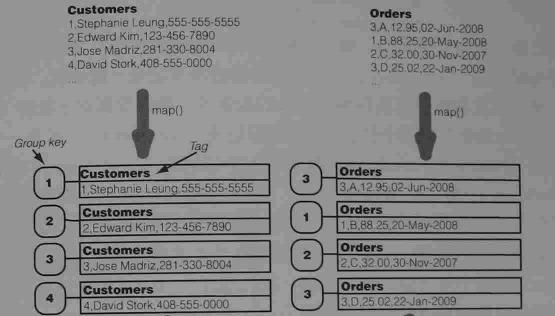
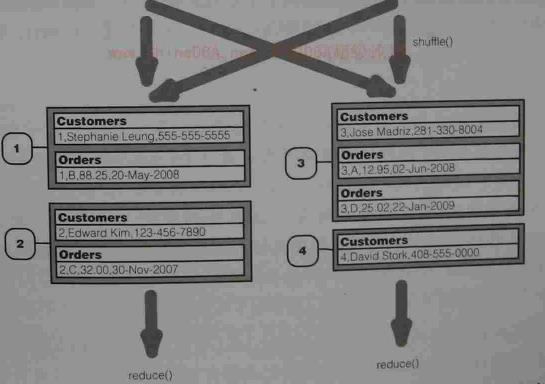
这里涉及的几个专业术语:Group key ,datasourde,Tag.前者的话通俗点来说的话就相当于关系型数据库中的主键和外键,通过其id进行的联结依据。datasource,顾名思义,就是数据的来源,那么这里指的就是Custonmers和Orders,Tag的话也比较好理解,就是里面的字段到底是属于哪个文件的。
操作Reduce的侧联结,要用到hadoop-datajoin-2.6.0.jar包,默认路径:
E:\hadoop-2.6.0\share\hadoop\tools\lib(hadoop的工作目录)。
用到的3个类:
1、DataJoinMapperBase
2、DataJoinReducerBase
3、TaggedMapOutput
比较正式的工作原理:
1、mapper端输入后,将数据封装成TaggedMapOutput类型,此类型封装数据源(tag)和值(value);
2、map阶段输出的结果不在是简单的一条数据,而是一条记录。记录=数据源(tag)+数据值(value).
3、combine接收的是一个组合:不同数据源却有相同组键的值;
4、不同数据源的每一条记录只能在一个combine中出现;
好,了解了这些我们就进行编码阶段:
这里的话将几个类写在一起测试,感觉另有一番感觉:
联结之前的Custmoner.txt文件: 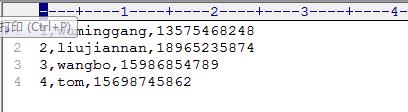
联结之前的Order.txt文件: 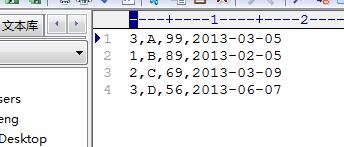
测试代码:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.contrib.utils.join.DataJoinMapperBase;
import org.apache.hadoop.contrib.utils.join.DataJoinReducerBase;
import org.apache.hadoop.contrib.utils.join.TaggedMapOutput;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
publicclassDataJoinextendsConfiguration{//DataJoinMapperBase默认没导入,路径E:\hadoop-2.6.0\share\hadoop\tools\libpublicstaticclassMapClassextendsDataJoinMapperBase{// 设置组键@Overrideprotected Text generateGroupKey(TaggedMapOutput aRecord) {
String line=((Text)aRecord.getData()).toString();
String [] tokens=line.split(",");
String groupkey=tokens[0];
returnnew Text(groupkey);
}
/*
* 这个在任务开始时调用,用于产生标签
此处就直接以文件名作为标签
*/@Overrideprotected Text generateInputTag(String inputFile) {
returnnew Text(inputFile);
}
// 返回一个任何带任何我们想要的Text标签的TaggedWritable@Overrideprotected TaggedMapOutput generateTaggedMapOutput(Object value) {
TaggedWritable retv=new TaggedWritable((Text) value);
retv.setTag(this.inputTag);
return retv;
}
}
publicstaticclassReduceextendsDataJoinReducerBase{// 两个参数数组大小一定相同,并且最多等于数据源个数@Overrideprotected TaggedMapOutput combine(Object[] tags, Object[] values) {
if(tags.length<2){
returnnull;// 这一步,实现内联结
}
String joinedStr="";
for(int i=0;i<values.length;i++){
if(i>0){
joinedStr+=",";// 以逗号作为原两个数据源记录链接的分割符
TaggedWritable tw=(TaggedWritable)values[i];
String line=((Text)tw.getData()).toString();
String[] tokens=line.split(",",2);// 将一条记录划分两组,去掉第一组的组键名。
joinedStr+=tokens[1];
}
}
TaggedWritable retv=new TaggedWritable(new Text(joinedStr));
retv.setTag((Text)tags[0]);
return retv;// 这只retv的组键,作为最终输出键。
}
}
/*TaggedMapOutput是一个抽象数据类型,封装了标签与记录内容
此处作为DataJoinMapperBase的输出值类型,需要实现Writable接口,所以要实现两个序列化方法
自定义输入类型*/publicstaticclassTaggedWritableextendsTaggedMapOutput{private Writable data;
//如果不给其一个默认的构造方法,Hadoop的使用反射来创建这个对象,需要一个默认的构造函数(无参数)publicTaggedWritable(){
}
publicTaggedWritable(Writable data){
//TODO 这里可以通过setTag()方法进行设置this.tag=new Text("");
this.data=data;
}
@OverridepublicvoidreadFields(DataInput in) throws IOException {
this.tag.readFields(in);
//加入以下的代码.避免出现空指针异常,当时一定要在其写的时候加入out.writeUTF(this.data.getClass().getName());//不然会出现readFully错误
String temp=in.readUTF();
if(this.data==null||!this.data.getClass().getName().equals(temp)){
try {
this.data=(Writable)ReflectionUtils.newInstance(Class.forName(temp), null);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
this.data.readFields(in);
}
@Overridepublicvoidwrite(DataOutput out) throws IOException {
this.tag.write(out);
out.writeUTF(this.data.getClass().getName());
this.data.write(out);
}
@Overridepublic Writable getData() {
return data;
}
}
publicstaticvoidmain(String[] args) throws Exception {
Configuration conf = new Configuration(); //组件配置是由Hadoop的Configuration的一个实例实现
JobConf job = new JobConf(conf, DataJoin.class);
Path in=new Path("hdfs://master:9000/user/input/yfl/*.txt");
Path out=new Path("hdfs://master:9000/user/output/testfeng1");
FileSystem fs=FileSystem.get(conf);
//通过其命令来删除输出目录if(fs.exists(out)){
fs.delete(out,true);
}
//TODO这里注意别导错包了
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("DataJoin");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TaggedWritable.class);
job.set("mapred.textoutputformat.separator", ",");
JobClient.runJob(job);
}
}
运行的结果: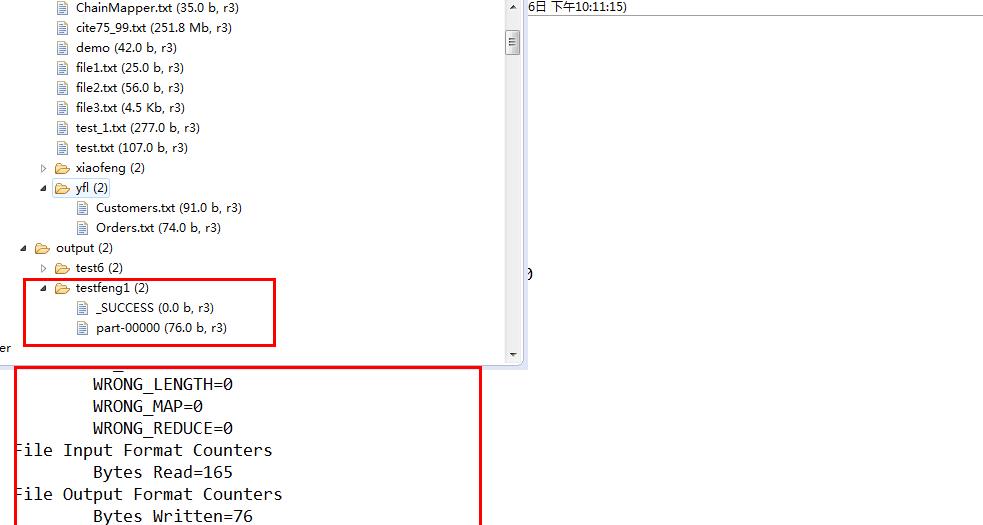
为了让调试更加的方便,在程序中直接使用delete命令已达到删除输出目录的功能,省去每次都要手动删除的麻烦,这里需要在我们的工程目录下面的bin目录下面添加主机的core-site.xml和hdfs-site.xml文件,然后给对于的目录赋上权限chmod -R 777 xxx,即可。 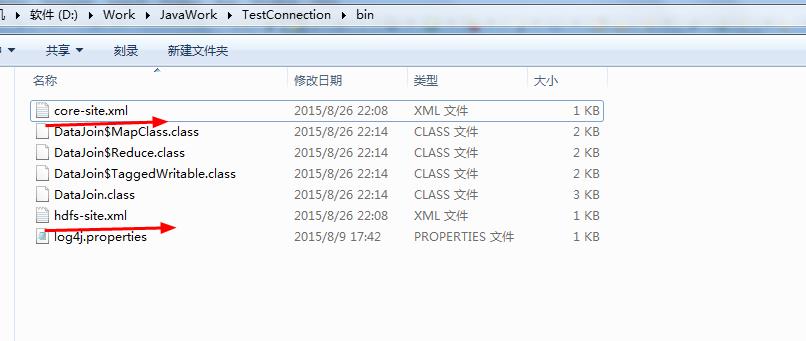
hadoop很有意思,我希望自己能走的更远!!!坚持,加油!!!
版权声明:本文为博主原创文章,未经博主允许不得转载。
原文:http://blog.csdn.net/watering_sea/article/details/48015575
内容总结
以上是互联网集市为您收集整理的Hadoop之Reduce侧的联结全部内容,希望文章能够帮你解决Hadoop之Reduce侧的联结所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。