Solr简单总结
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Solr简单总结,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含6537字,纯文字阅读大概需要10分钟。
内容图文

Solr
运行Solr服务
方式一:Jetty服务器启动Solr
- 进入solr-4.10.2/example目录
- 打开命令行,执行java –jar start.jar命令,即可启动Solr服务
- 打开浏览器,通过http://localhost:8983/solr来访问Solr管理页面。
方式二:Tomcat服务器启动Solr
- 部署Web服务,将solr-4.10.2/example/webapps/solr.war复制到自己的tomcat/webapps目录中,并解压,然后删除solr.war文件
- 在Tomcat中加入相关jar包:将“resource\solr在tomcat运行需要导入的jar包\lib”下的jar包复制tomcat/webapps/solr/WEB-INF/lib下。
并且把class/log4j.properties复制到tomcat/webapps/solr/WEB-INF下 - 修改Tomcat配置文件,指向Solr的索引库及配置目录。
注意,这里可以指向solr-4.10.2/example/solr目录,如果想独立出来,也可以将这个solr文件夹复制出来到任意位置(不要出现中文),例如:例如:C:/tmp/solr - 进入Tomcat文件夹,用记事本打开:tomcat/bin/catalina.bat文件,添加一条配置信息,指向我们的索引库及配置目录:set "JAVA_OPTS=-Dsolr.solr.home=C:/tmp/solr"
- 进入tomcat/bin目录,双击 startup.bat文件启动服务器
- 打开浏览器,访问http://localhost:8080/solr 进入Solr管理页面
Solr管理页面

Dashboard仪表盘
显示solr服务及系统运行信息
Logging(日志)
solr运行的日志信息
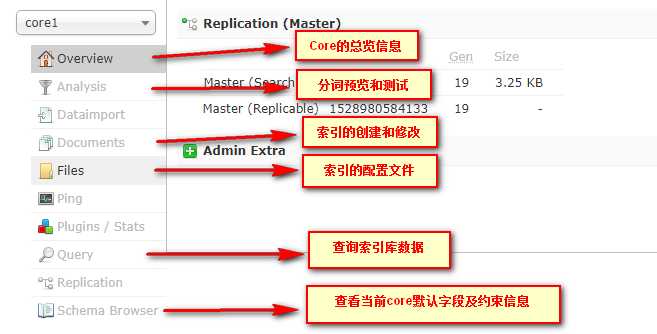
Core Admin(Core管理)
在Solr中,每一个Core,代表一个索引库,里面包含索引数据及其配置信息。
Solr中可以拥有多个Core,也就同时管理多个索引库!就像在MySQL中可以有多个database一样!
JavaProperties
Java运行环境信息
ThreadDump
solr运行线程信息
CoreSelector(Core选择器)


schema.xml
注意:在本文件中,有两个字段是Solr自带的字段,绝对不要删除:_version_节点和_root_节点
Field字段定义字段的属性信息段
属性及含义:
name:字段名称,最好以下划线或者字母开头
type:字段类型,指向的是本文件中的
FieldType指定数据类型
属性及含义:
name:字段类型的名称,可以自定义,
唯一主键
Lucene中本来是没有主键的。删除和修改都需要根据词条进行匹配。而Solr却可以设置一个字段为唯一主键,这样删改操作都可以根据主键来进行!
IK分词器
<fieldType name="text_ik" >
<analyzer />
</fieldType>
SolrJ的使用
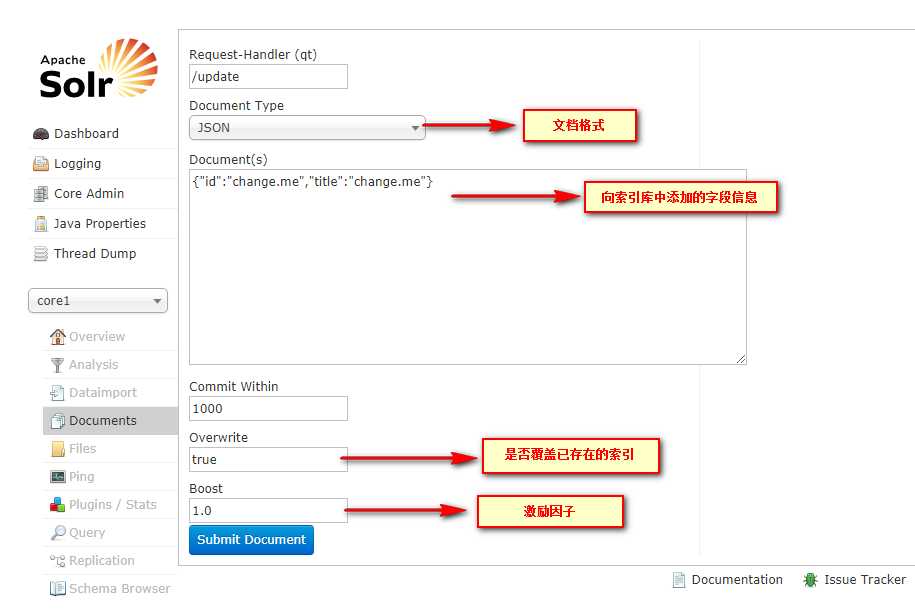
添加或修改索引库数据
private static String baseURL = "http://localhost:8080/solr/core1";
@Test
public void createTest() throws Exception {
//连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
//创建文档对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "5");
document.addField("title", "8848手机,钛合金外壳,注定不平凡");
document.addField("content", "8848发发发");
//向solr服务器写入文档
solrServer.add(document);
solrServer.commit();
}
@Test
public void create2Test() throws Exception {
//连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
//创建文档对象
Item item = new Item();
item.setId("6");
item.setTitle("金立M2017成功人士的标配");
item.setContent("金立你值得拥有");
//向solr服务器写入文档
solrServer.addBean(item);
solrServer.commit();
}
//添加@Field注解
public class Item{
@Field
private String id;
@Field
private String title;
@Field
private String content;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
删除索引库数据
@Test
public void deleteTest() throws SolrServerException, IOException {
// 连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
// 删除索引
//solrServer.deleteById("6");
solrServer.deleteByQuery("title:金立");
// 提交
solrServer.commit();
}
查询索引库数据
在创建SolrQuery时,我们填写的Query语句,可以有以下高级写法:
- 通配符?和 *:“*”表示匹配任意字符;“?”表示匹配出现的位置
- 布尔操作:AND、OR和NOT布尔操作(推荐使用大写,区分普通字段)
- 子表达式查询(子查询):可以使用“()”构造子查询。比如:(query1 AND query2) OR (query3 AND query4)
- 相似度查询:指定编辑距离的相似度查询:对模糊查询可以设置编辑距离,可选0-2的整数(默认为2):title:appla~1。
- 范围查询(Range Query):Lucene支持对数字、日期甚至文本的范围查询,并且两端范围。结束的范围可以使用“*”通配符。
(1)日期范围(ISO-8601时间GMT):a_begin_date:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
(2)数字:salary:[2000 TO *]
(3)文本:entryNm:[a TO a]
@Test
public void queryTest() throws SolrServerException{
// 连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
//创建查询条件对象
SolrQuery params = new SolrQuery("*:*");
//执行查询,获取响应数据
QueryResponse response = solrServer.query(params);
//获取数据结果集
SolrDocumentList list = response.getResults();
System.out.println("一共获取了" + list.size()+"条结果:");
for (SolrDocument solrDocument : list) {
System.out.println("id: " + solrDocument.getFieldValue("id"));
System.out.println("title:" + solrDocument.getFieldValue("title"));
}
}
@Test
public void queryBeanTest() throws SolrServerException{
// 连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
//创建查询条件对象
SolrQuery params = new SolrQuery("*:*");
//执行查询,获取响应
QueryResponse response = solrServer.query(params);
List<Item> beans = response.getBeans(Item.class);
System.out.println("一共获取了" + beans.size()+"条结果:");
for (Item item : beans) {
System.out.println("id: " + item.getId());
System.out.println("title:" + item.getTitle());
}
}
实现排序
@Test
public void querySortTest() throws SolrServerException, IOException {
// 连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
// 创建查询条件对象,范围查询,包含两端
SolrQuery query = new SolrQuery("*:*");
// 设置查询的排序参数,1-排序的字段名,2-排序方式(ORDER:asc desc)
query.setSort("id", ORDER.asc);
// 执行查询,获取响应数据
QueryResponse response = solrServer.query(query);
// 获取结果集数据
List<Item> list = response.getBeans(Item.class);
System.out.println("总记录数 numFound:"+response.getResults().getNumFound());
for (Item item : list) {
System.out.println("id: " + item.getId());
System.out.println("title:" + item.getTitle());
}
}
实现分页
@Test
public void queryPageTest() throws SolrServerException, IOException {
// 准备分页参数
int pageNum = 1; //页码
int pageSize = 2; //每页条数
// 连接solr服务器
HttpSolrServer solrServer = new HttpSolrServer(baseURL);
// 创建查询条件对象
SolrQuery params = new SolrQuery("*:*");
// 设置查询的排序参数,1-排序的字段名,2-排序方式(ORDER:asc desc)
params.setStart((pageNum-1)*pageSize);//设置起始条数
params.setRows(pageSize);//设置每页条数
// 执行查询,获取响应数据
QueryResponse response = solrServer.query(params);
// 获取结果集数据
SolrDocumentList list = response.getResults();
System.out.println("一共获取了" + list.size() + "条结果:");
for (SolrDocument solrDocument : list) {
System.out.println("id: " + solrDocument.getFieldValue("id"));
System.out.println("title:" + solrDocument.getFieldValue("title"));
}
}
实现高亮
@Test
public void highLightingTest() throws SolrServerException, IOException{
// 初始化solrj服务
HttpSolrServer server = new HttpSolrServer(baseURL);
// 设置查询条件
SolrQuery params = new SolrQuery("title:手机");
// 设置前置标签
params.setHighlightSimplePre("<em >");
// 设置后置标签
params.setHighlightSimplePost("</em>");
// 添加高亮字段
params.addHighlightField("title");
// 执行查询
QueryResponse queryResponse = server.query(params);
// 外层的Map,key:id,value:id以外的其他高亮字段,可能有多个,也是一个Map
// 内层的Map,key:高亮字段的名称,value:字段的内容,集合
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
// 遍历map,获取结果
Set<String> ids = highlighting.keySet();
for (String id : ids) {
System.out.println("id: " + id);;
// 获取高亮字段的集合
Map<String, List<String>> map = highlighting.get(id);
// 获取高亮字段
System.out.println(map.get("title").get(0));
// 因为content不是高亮字段,所以打印出的内容为null
System.out.println(map.get("content"));
}
}
原文:https://www.cnblogs.com/lifuwei/p/9184754.html
内容总结
以上是互联网集市为您收集整理的Solr简单总结全部内容,希望文章能够帮你解决Solr简单总结所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。