hadoop得知;datajoin;chain署名;combine()
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了hadoop得知;datajoin;chain署名;combine(),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1370字,纯文字阅读大概需要2分钟。
内容图文
")
hadoop一种简化机制来管理job和control作业之间的非线性依赖,job对象mapreduce表明。
job该目的是通过使实例化jobconf对象的构造函数的工作落实。
x.addDeopendingJob(y)意味着x在y完毕之前不会启动。
鉴于job对象存储着配置和依赖信息,jobcontrol对象会负责监管作业的运行。通过addjob(),你能够为jobcontrol加入作业,当全部作业和依赖关系加入完毕后,调用jobcontrol的run()方法,生成一个线程提交作业并监视其运行,有allFinised(),getFailedJobs()方法
hadoop引入chainMapper和chainReducer来简化预处理和后处理
driver会先设置“全局”jobconf对象。包括作业名。输入路径和输出路径等。它一次性加入全部步骤,然后按顺序运行
ChainMapper.addMapper()方法的签名来具体了解怎样一步步的链接作业

byvalue用于推断是否是值传递,若为false则採用引用传递。初始mapper的输出内容保存在内存中。假设后期不再调用传入的值,能够这样,效率高,一般设为true
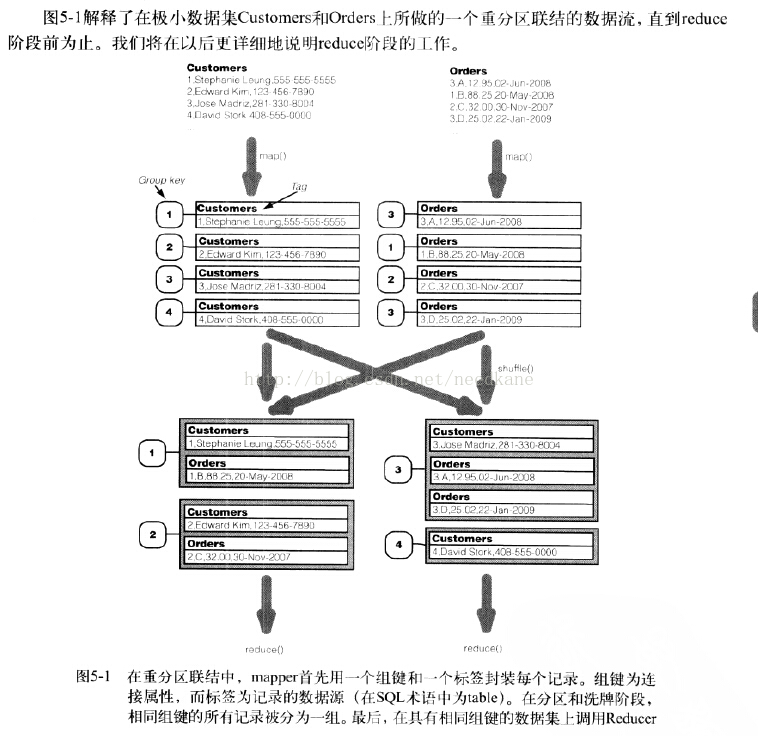
reduce函数接收输入数据,并对其值进行交叉乘积,reduce生成这些值的全部合并结果。
交叉乘积得到的每一个合并结果被送入函数combine()(不是combiner)生成一个输出记录,对于随意特定的合并,combine能够选择不输出。交叉乘积的本质确保了combine看到的记录都有同样的连接键
在解释怎样使用DatajoingMapperBase和DataJoinReduceBase之前。你须要了解在代码通篇所使用的一个抽象数据类TaggedMapOutput(用Text标签封装记录的数据类型)
在数据流的描写叙述中,mapper输出的包带有一个组键和一个被标签记录的值,datajoin软件包指定组键为text类型。而值为TaggerMapOutput类型,它详细实现了getTag()和setTag(Text Tag)方法
作为mapper的输出,TaggerMapOutput必须是Writable类型,因此我们的子类必须实现readFile()和write()方法
DataJoinMapper运行全部的封装,指定了三个能够填充的抽象方法
generateInputTag在map任务開始前调用。来为这个map任务所处理的全部记录指定一个全局标签,

假设横跨几个文件。能够用它们的前缀作为标签
完毕map任务初始化后。为每一个记录调用DataJoinMapperBase的map()方法。
里面调用generateTaggedOutput()和generateGroupKey()方法
原则上。在同一文件里,不同的记录能够用不同的标签,在标准情况下。我们希望一个标签代表一个数据源,它早先由generateInputTag()计算好并存在this.InputTag中
版权声明:本文博主原创文章。博客,未经同意不得转载。
原文:http://www.cnblogs.com/bhlsheji/p/4800620.html
内容总结
以上是互联网集市为您收集整理的hadoop得知;datajoin;chain署名;combine()全部内容,希望文章能够帮你解决hadoop得知;datajoin;chain署名;combine()所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。