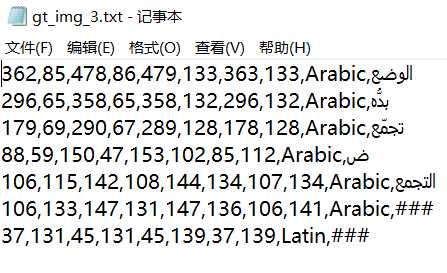
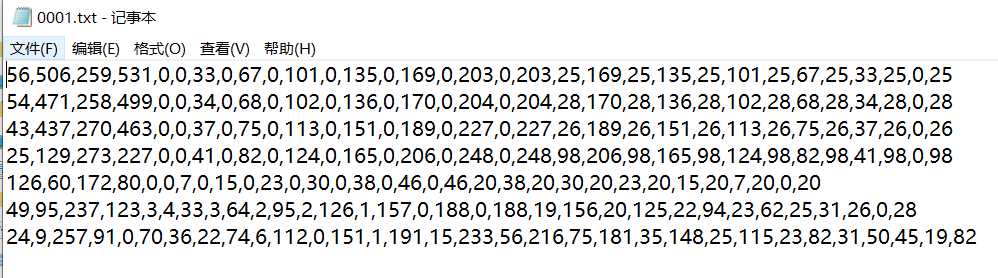
文本检测数据集以及标签形式说明icdar15系列,带角度的四边形标签 打开标签文件,每行为一个文本框坐标以及语言类型,文字,###代表模糊不清形式,是四边形的四个点的坐标。 ctw1500系列任意形状的数据集标签 每行共32个数字,前四个数字为该弯曲文本在整张图上的矩形框坐标值,剩下的28个值为14个点,为相对于矩形框左上角得误差补偿即为与左上角坐标所形成的差值,形成封闭的弯曲文本框,其计算方式可以简单的理解为:1.将前4...
我目前正在分析一组要分类的图片.分类是通过人工神经网络以监督方式进行的.我有一个测试集,为每个图片分配其类.
我现在想做的是生成很多描述符,然后在这些描述符上执行PCA并进行统计分析,描述符可以描述多少图片的类别.
如何以编程方式为这些图片生成描述符?这也可以帮助我解决将来的分类问题.让我们假设我有足够的计算能力(100个核心集群)是否有包含大量图像描述符的库?解决方法:您基本上可以遵循两种方法开始:
>基于特征,使用...
对一些现有的数据集进行反推,生成labelme标注的格式。生成的效果如下图:使用了 RSOD部分数据,将VOC数据集反推为labelme的标注数据。
代码如下:
import sys
import os.path as osp
import io
from labelme.logger import logger
from labelme import PY2
from labelme import QT4
import PIL.Image
import base64
from labelme import utils
import os
import cv2
import xml.etree.ElementTree as ETmodule_path = os.path.abs...
这是coursea吴恩达老师的Neural Networks and Deep Learning week2的编程作业和离线数据import numpy as np
import matplotlib.pyplot as plt
import h5py
import scipy
from PIL import Image
from scipy import ndimage
from lr_utils import load_dataset#读入数据库,如图像,训练集,测试集
train_set_x_orig,train_set_y,test_set_x_orig,test_set_y,classes=load_dataset()#此乃训练集数量
m_train=train_set_x_orig.shap...
MR数据集 https://www.cs.cornell.edu/people/pabo/movie-review-data/ 上下载 SST数据集 https://nlp.stanford.edu/sentiment/ 上下载 word2vec下载 https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit 国内地址:https://pan.baidu.com/s/1jJ9eAaE glove下载 http://downloads.cs.stanford.edu/nlp/data/glove.840B.300d.zip 国内地址:https://apache-mxnet.s3.cn-north-1.amazonaws.com.cn/gluon/embeddings/...
代码来源Pytorch Quick Tip: Calculate Mean and Standard Deviation of Data
import torch
import torch.utils.data.dataloader as dataloader
import torchvision.datasets as datasets
from torchvision import transformstrain_dataset = datasets.CIFAR10(root="dataset/", train=True, transform=transforms.ToTensor(), download=True)
train_loader = dataloader.DataLoader(dataset=train_dataset, batch_size=64, shuffl...
手写数字数据集(下载地址:http://www.cs.nyu.edu/~roweis/data.html) 手写数字数据集包括1797个0-9的手写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度。 使用sklearn.datasets.load_digits即可加载相关数据集。参数:* return_X_y:若为True ,则以(data, target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。* n_class:表示返回数据的类别数,如...
1 #!/usr/bin/python2 # coding=utf-83 from sklearn.datasets import load_iris4 from sklearn.model_selection import train_test_split5 from sklearn.tree import DecisionTreeClassifier, export_graphviz6 def dectree_demo():7 #决策树对鸢尾花数据集进行分类8 9 #获取数据
10 iris = load_iris()
11
12 #划分数据
13 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
1...
原文链接:https://mp.weixin.qq.com/s/ETnBeIIkusvdFc3a2J0QAA以BERT为代表的预训练模型为自然语言处理领域带来了新的春天,在人机对话问题上也不例外。检索式多轮对话任务中,最有名的对话数据集就是Ubuntu Dialogue Corpus了,ACL2018提出的DAM是76.7%的,然而基于BERT来做却直接刷到了85.8%的,93.1%的和高达98.5%的,已经基本逼近了人类的表现(英语差的可能已被BERT超越),这让很多研究检索式聊天机器人的小伙伴直呼这个领域...
1、概述
我们知道,行式引擎按页取数只适用于Oracle,mysql,hsql和sqlserver2008及以上数据库,其他数据库,如access,sqlserver2005,sqlite等必须编写分页SQL。
下面以Access数据库为例介绍需要写分页SQL的数据库怎样利用行式的引擎实现层式报表。
解决方案提供工具:报表开发工具FineReport
2、解决思路
对于mysql这类可以直接使用行式的引擎实现层式报表的数据库来说,如果勾选了行式引擎,程序会自动生成分页sql,如,我新建了...
用mapreduce 处理气象数据集编写程序求每日最高最低气温,区间最高最低气温气象数据集下载地址为:ftp://ftp.ncdc.noaa.gov/pub/data/noaa按学号后三位下载不同年份月份的数据(例如201506110136号同学,就下载2013年以6开头的数据,看具体数据情况稍有变通)解压数据集,并保存在文本文件中对气象数据格式进行解析编写map函数,reduce函数将其权限作出相应修改本机上测试运行代码放到HDFS上运行将之前爬取的文本文件上传到hdfs上用...
美团作为全球最大的本地生活服务平台,拥有由遍布全国的市场人员所拍摄的众多门脸招牌图片数据。每张图片都是由全国的不同个人,采用不同设备,在不同地点,不同时间和不同环境下所拍摄的不同目标,是难得的可以公正评价算法鲁棒性和识别效果的图片数据,挑战也非常大。
近年来业界围绕着文字检测和文字识别提出了许多有效的算法和技术方案。由于之前公开的数据集普遍以英文为主,因此所提出的技术方案对中文特有问题关注不足。表现...
from keras.preprocessing import sequencefrom keras.models import Sequentialfrom keras.layers import Dense, Embeddingfrom keras.layers import LSTMfrom keras.datasets import imdbmax_features = 20000maxlen = 80 # cut texts after this number of words (among top max_features most common words)batch_size = 32print(Loading data...)
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_feat...