大数据入门第二十四天——SparkStreaming(2)与flume、kafka整合
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了大数据入门第二十四天——SparkStreaming(2)与flume、kafka整合,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3622字,纯文字阅读大概需要6分钟。
内容图文
与flume、kafka整合")
前一篇中数据源采用的是从一个socket中拿数据,有点属于“旁门左道”,正经的是从kafka等消息队列中拿数据!
主要支持的source,由官网得知如下:
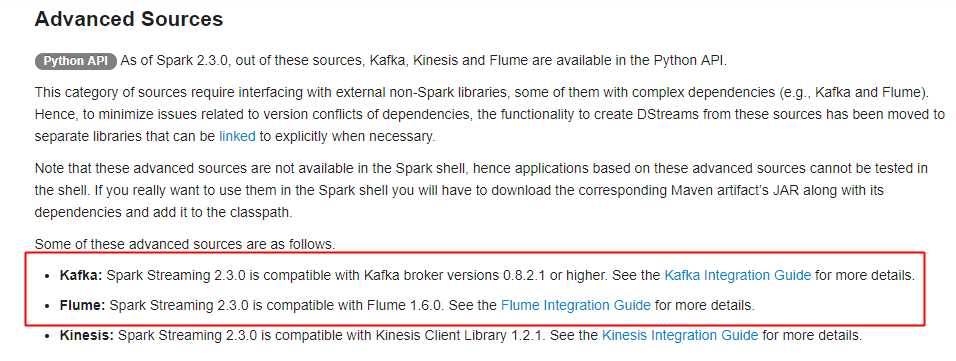
获取数据的形式包括推送push和拉取pull
一、spark streaming整合flume
1.push的方式
更推荐的是pull的拉取方式
引入依赖:
<
dependency
>
<
groupId
>org.apache.spark</groupId><artifactId>spark-streaming-flume_2.10</artifactId><version>${spark.version}</version></dependency>
编写代码:
package
com.streaming
import
org.apache.spark.SparkConf
import
org.apache.spark.streaming.flume.FlumeUtils
import
org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by ZX on 2015/6/22.
*/
object FlumePushWordCount {
def main(args: Array[String]) {
val host = args(0)
val port = args(1).toInt
val conf = new SparkConf().setAppName("FlumeWordCount")//.setMaster("local[2]")
// 使用此构造器将可以省略sc,由构造器构建
val ssc = new StreamingContext(conf, Seconds(5))
// 推送方式: flume向spark发送数据(注意这里的host和Port是streaming的地址和端口,让别人发送到这个地址)
val flumeStream = FlumeUtils.createStream(ssc, host, port)
// flume中的数据通过event.getBody()才能拿到真正的内容
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_, 1))
val results = words.reduceByKey(_ + _)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
flume-push.conf——flume端配置文件:

# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /export/data/flume a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = avro #这是接收方 a1.sinks.k1.hostname = 192.168.31.172 a1.sinks.k1.port = 8888 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.pull的方式
属于推荐的方式,通过streaming来主动拉取flume产生的数据
编写代码:(依赖同上)
package
com.streaming
import
java.net.InetSocketAddress
import
org.apache.spark.SparkConf
import
org.apache.spark.storage.StorageLevel
import
org.apache.spark.streaming.flume.FlumeUtils
import
org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePollWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("FlumePollWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
//从flume中拉取数据(flume的地址),通过Seq序列,里面可以new多个地址,从多个flume地址拉取
val address = Seq(new InetSocketAddress("172.16.0.11", 8888))
val flumeStream = FlumeUtils.createPollingStream(ssc, address, StorageLevel.MEMORY_AND_DISK)
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
配置flume
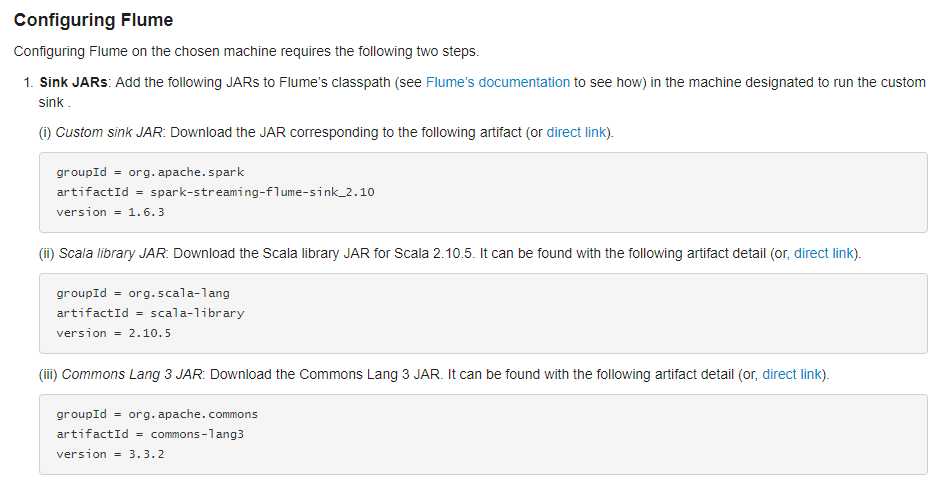
通过拉取的方式需要flume的lib目录中有相关的JAR(要通过spark程序来调flume拉取),通过官网可以得知具体的JAR信息:

配置flume:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /export/data/flume a1.sources.r1.fileHeader = true # Describe the sink(配置的是flume的地址,等待拉取) a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.hostname = mini1 a1.sinks.k1.port = 8888 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动flume,然后启动IDEA中的spark streaming:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
// -D后参数可选
原文:https://www.cnblogs.com/jiangbei/p/8856750.html
内容总结
以上是互联网集市为您收集整理的大数据入门第二十四天——SparkStreaming(2)与flume、kafka整合全部内容,希望文章能够帮你解决大数据入门第二十四天——SparkStreaming(2)与flume、kafka整合所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。