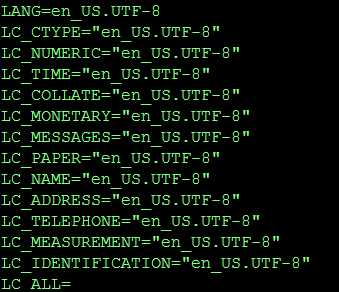
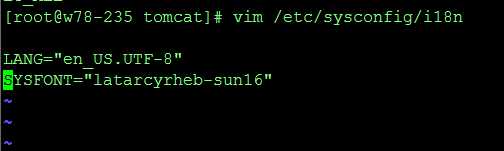
1、查看项目编码格式与日志文件格式是否一致,如统一UTF-82、使用 Linux命令 locale 查看Linux系统编码 保证跟项目编码一致。 修改Linux系统编码 vim /etc/sysconfig/i18n 2、首先查看Tomcat启动脚本catalina.sh是否有 JAVA_OPTS="-Dfile.encoding=UTF8 -Dsun.jnu.encoding=UTF8" 没有添加该启动参数。重启项目,查看日志或生成文件 一切OK!原文:https://www.cnblogs.com/xingtangxiaoga/p/9685883.html
import java.io.BufferedReader;import java.io.FileReader;import java.io.FileWriter;import java.io.IOException;public class TestFileWriter {public static void main(String [] args) {try {FileReader out = new FileReader("d:/a.txt");BufferedReader br=new BufferedReader(out);char a[]=new char[1024];String line=null;for(;(line=br.readLine())!=null;){System.out.print(new String(line.getBytes("UTF-8"))+"\n...
1、前台中文传递到后台乱码,
前台不需要处理,
系统一般都会默认把中文转化为ISO-8859-1类型,
只需在后台接受数据是处理 Str为前台传过来的中文字符串: String inputer = new String( Str.getBytes("ISO-8859-1") , "GB2312"); 2、前台不仅包含中文,而且包含特殊字符,如果只在后台转码,比较困难。采用前台转码,那么就采用后台解码的方式处理var theid = encodeURI(encodeURI(id)); //中文及全角字符转码 URLDecoder.d...
js代码function editImage(userName){ var userName1= encodeURI(userName);//中文转码 userName1 = userName1.replace("+","%2B");//防止web容器自动转码 userName1 = userName1.replace(/%/g,"@");//防止web容器自动转码}java代码userName = java.net.URLDecoder.decode(userName.replaceAll("@", "%"),"utf-8");原文:http://www.cnblogs.com/ddfan/p/4530566.html
自从接触Java和JSP以来,就不断与Java的中文乱码问题打交道,现在终于得到了彻底的解决,现将我们的解决心得与大家共享。
一、Java中文问题的由来 Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,Java和JSP文件本身编译时产生的乱码问题和Java程序于其他媒介交互产生的乱码问题。 首先Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件...
最近需要从某个网页上抓取数据。一波三折。1. 先要找到网站页面调用后台数据服务的url地址,但是本人对js不了解,花了不少时间在分析其网页源代码的js部分,试图寻找出调用数据的链接。后来得知浏览器都会追踪页面发出去的所有链接,chrome中,“F12->网络” 会显示所有的调用链接。读取后端数据的链接就在里面。2. 找到url链接之后,接下来读取数据。 开始时用的是HttpGet类来读取,代码如下:HttpGet httpGet = new HttpGet(url)...
package Test0;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FilenameFilter;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.sql.DriverManager;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.mysql.jdbc.Connection;
import com.mysql.jdbc.Statement;
public class Test00 {
static Connection co...
中文乱码问题及其解决方法1.解决HTML页面中的中文问题:为了使HTML页面很好地支持中文,就必须在每个HTML页面的头部增加如下代码:<HEAD>...<META http-equiv=Content-Type content="text/html;charset=utf-8">...<HEAD>2.解决JSP页面中的中文问题为了使JSP页面很好地支持中文,就必须在每个JSP页面的头部增加如下代码:<%@ page contentType="text/html;charset=utf-8" language="java"%>3.解决Servlet响应结果的中文问题为了使Se...
0.说在前面 基于SpringMVC--注解项目1.新建encoding.jsp和success.jsp页面encoding.jsp<%@ page language="java" contentType="text/html; charset=UTF-8"pageEncoding="UTF-8"%><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><title>中文乱码问题</title></head><body><form acti...
如果使用Tomcat服务器,在提交过程中,经常会出现中文乱码问题。乱码问题分为两个方面:1.中文无法显示有些JSP中,中文根本无法显示。通常的原因是没有把文件头的字符集设置为中文字符集。一定要保证文件头上写明:<%@ page language="java" contentType="text/html;charset=gb2312"%>
或者
<%@ page language="java" pageEncoding="gb2312"%>2.提交过程中显示乱码前台提交给服务器时,服务器将其认为ISO-8859-1编码,而网页显示的...
可能的错误地方: 1.jsp页面编码 2.表单编码 3.servlet可接受编码 4.tomcat中server.xml文件中的指定编码 所有的编码要统一,一般使用“UTF-8”比较好我最近一次出错的是第四种情况,问题已经解决,解决方法:修改发布solr的tomcat服务器中“server.xml”配置文件。 修改前: <Connector port="8089" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" /> 修改后: <Connec...
在做关于 Java Web 的项目中,有时候项目的整体设置为 utf-8 编码以后,你还是会发现项目还是乱码。1.出现乱码实例正如下图所示:虽然在代码中,加入了:request.setCharacterEncoding("utf-8"); 结果还是会乱码。/*** 插入管理员*/
@WebServlet("/intsertinfo")
public class IntsertAdmininfoServlet extends HttpServlet {private static final long serialVersionUID = 1L;public IntsertAdmininfoServlet() {super();}protect...
注意问题:在学习用selvert的过滤器filter处理中文乱码时,在filter配置初始化时用了utf-8处理中文乱码,而在提交的jsp页面中却用了gbk。虽然两种都可以出来中文乱码,但是却造成了处理乱码的格式不一致。所以编译出错。解决方法:所有地方都用utf-8或gbk//过滤器类CharactorFilter.jsp
package cn.com.Filter;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet...
最近接手一个手机端服务端的程序(JAVA实现),我这边测试的话前台直接用的get方式传数据,get请求编码方式和post请求提交编码方式不同,get是把数据直接放到url中,例如以上的uname,IE浏览器先对中文进行utf-8编码(一个中文3个字符表示 太长),继而为了缩短字符又用ISO8859-1编码后传递给服务器。服务器的doGet方法中要先进行ISO8859-1解码再utf-8解码才能看到中文。post请求则在浏览器端把数据以utf-8的形式存储到http的请求体中...
/*** 区分ie 和其他浏览器的下载文件乱码问题* @param request* @param fileName* @return*/public String getFileName(HttpServletRequest req,String fileName){String userAgent = req.getHeader("user-agent");userAgent = userAgent ==null?"":userAgent.toLowerCase();String name = fileName;try { //针对IE或者以IE为内核的浏览器:if(userAgent.contains("msie") ||userAgent.contains("trident")){name = U...