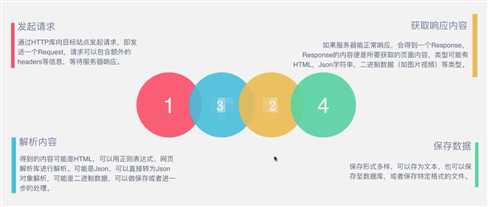
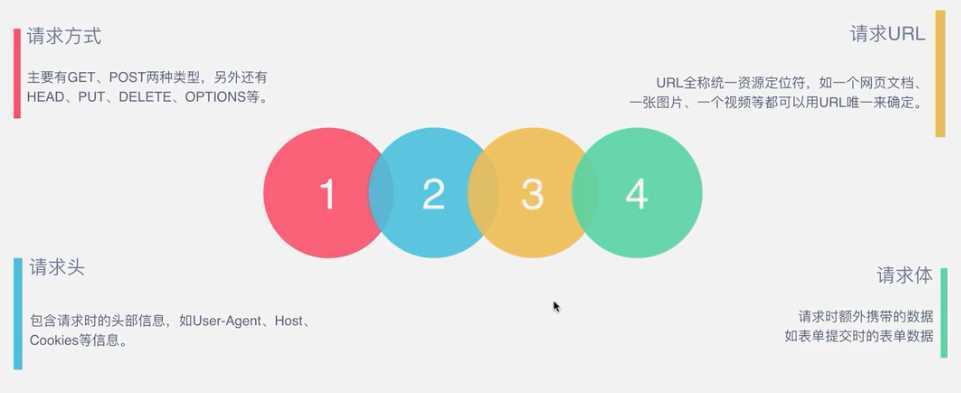
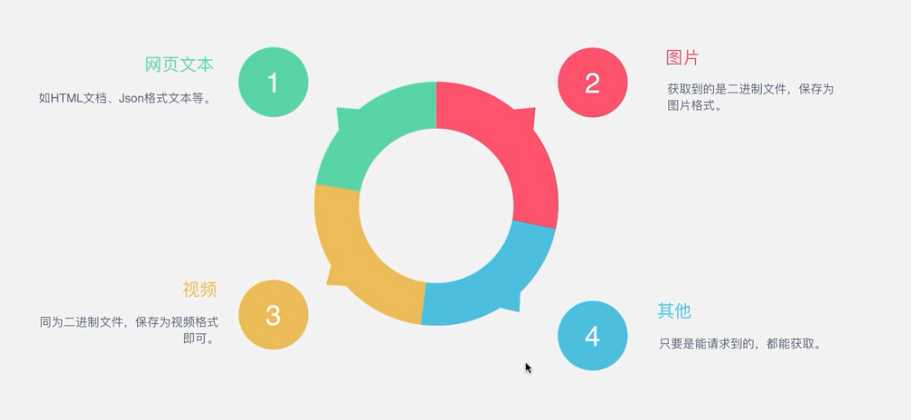
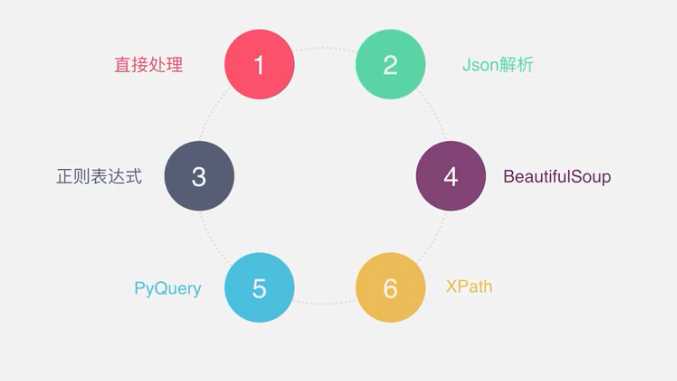
1、爬虫的基本流程2、request和response(1)request(2)response3、怎样抓取数据?4、解析方式 5、怎么解决JavaScript渲染问题?6、怎样保存数据 原文:https://www.cnblogs.com/zhuifeng-mayi/p/9640540.html
目录1. 什么是爬虫2. 爬虫工作原理3. 爬虫实现手段3.1 请求库3.2 解析库3.3 存储库3.4 其他工具1. 什么是爬虫爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。2. 爬虫工作原理发送请求模拟浏览器向web服务端获取数据如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等解析数据解析得到有用的数据保存数据将数据存储到数据库或本地3. 爬虫实现手段3.1 请求库requestsre...
1.爬虫的工作原理网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联...
Scrapy单机架构在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求但是这些request队列都是维持在本机上的,因此如果要多台主机协同爬取,需要一个request共享的机制——requests队列,在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。单主机爬虫架构调度器负责从队列中调度requests进行爬取,而...
一.爬虫是什么?二.爬虫的基本流程三.请求与响应四.Request五.Response六.总结一爬虫是什么?1、什么是互联网?互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。
2、互联网建立的目的?互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。
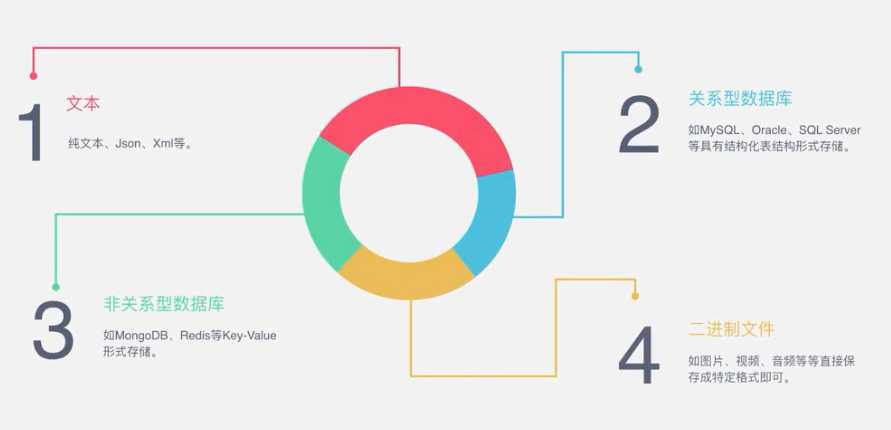
3、什么是...
一、爬虫基础简介必备知识三种爬虫方式? 通用爬虫: 抓取系统重要组成部分,获取的是整张页面数据
? 聚焦爬虫: 建立在通用爬虫之上,抓取页面指定的局部内容
? 增量式爬虫: 检测网站数据更新的情况,只抓取更新出来的数据robots.txt协议: 君子协议,规定网站哪些数据可不可爬
http协议: 服务器和客户端进行数据交互的一种形式。https协议: 安全的超文本传输协议(证书秘钥加密))请求头:User-Agent: 请求载体的身份标识Conn...
what‘s the 爬虫?了解爬虫之前,我们首先要知道什么是互联网1、什么是互联网? 互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,总体上像一张网一样。2、互联网建立的目的? 互联网的核心价值在于数据的共享和传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。3、什么是上网?爬虫要...
1.URL:
统一资源定位符,即常见的网页链接,爬虫中常用对象; eg:https://www.jianshu.com/
2.超文本:
网页是由超文本解析而成的,网页源代码HTML就称作超文本;
3.HTTP和HTTPS:
联系:两者皆为超文本传输协议,旨在启用客户端和服务器之间的通信,充当客户端和服务器之间的请求-响应协议。
区别:HTTPS多加入了SSL层,对传输的内容进行加密,现阶段所有网页都逐渐统一HTTPS化;
4.HTTP请求过程:
在浏览器输入一个URL,回车,...
请问各位大神,网络爬虫是什么原理呢?记得有一个软件叫中国菜刀爬行版,可以用来探测网络后台,这就是爬虫吗? 回复讨论(解决方案) 正和邪是有一步之遥,你那个用来探测网络后台的不是爬虫而是病毒 爬虫是爬取网页上的信息的 中国菜刀爬虫 版算是爬行 ,一般网站管理后有admin manage这些,通过爬虫 抓取这些文件夹是否存在,然后知道你的后台路径。
网络爬虫的原理请问各位大神,网络爬虫是什么原理呢?记得有一个软件叫中国菜刀爬行版,可以用来探测网络后台,这就是爬虫吗?------解决思路----------------------爬虫是爬取网页上的信息的
PHP可以写网页爬虫吗 ?原理是什么?回复内容:PHP可以写网页爬虫吗 ?原理是什么?<>几乎任何语言都能写爬虫,原理也都一样,http 协议抓网页内容,按照需求程度不同,可能还要抓响应码、Cookies、header然后自行处理。PHP 有 CURL 库,除稳定性稍差以外,基本可用。可以 通常是用curl做 不过抓取网页的速度相对java等语言来说有点慢可以写,至于原理都是基于HTTP协议,解析得到的文本,解析出其中的连接,然后再继续访问这些连接...
正则php爬虫 本人实习生小菜鸟一枚,公司让写个爬虫练练手,之前对这个完全没概念,刚才在网上看了一会,觉得大致思路是抓下来整个文件,用正则表达式处理文本似的根据文法抓取要抓的东西,然后再处理,想问问现在也是这个思路么,就拿最初级的表单里的数据来说,现在有没有更直接的抓取方法,另外希望给几个php爬虫的demo,公司服务器没有python环境,只能用php了,多谢。
本篇文章给大家带来的内容是介绍puppeteer爬虫是什么?爬虫的工作原理。有一定的参考价值,有需要的朋友可以参考一下,希望对你们有所帮助。爬虫(puppeteer)是什么?爬虫又称网络机器人。每天或许你都会使用搜索引擎,爬虫便是搜索引擎重要的组成部分,爬取内容做索引。现如今大数据,数据分析很火,那数据哪里来呢,可以通过网络爬虫爬取啊。那我萌就来探讨一下网络爬虫吧。爬虫的工作原理如图所示,这是爬虫的流程图,可以看到...
python视频教程栏目介绍分布式爬虫原理。免费推荐:python视频教程首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的。(1)打开浏览器,输入URL,打开源网页(2)选取我们想要的内容,包括标题,作者,摘要,正文等信息(3)存储到硬盘中上面的三个过程,映射到技术层面上,其实就是:网络请求,抓取结构化数据,数据存储。我们使用Python写一个简单的程序,实现上面的简单抓取功能。#!/usr/bin/python
#-*- coding: utf-...
python视频教程栏目介绍分布式爬虫原理。免费推荐:python视频教程首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的。(1)打开浏览器,输入URL,打开源网页(2)选取我们想要的内容,包括标题,作者,摘要,正文等信息(3)存储到硬盘中上面的三个过程,映射到技术层面上,其实就是:网络请求,抓取结构化数据,数据存储。我们使用Python写一个简单的程序,实现上面的简单抓取功能。#!/usr/bin/python
#-*- coding: utf-...