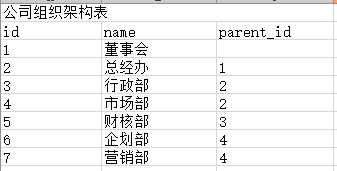
公司组织架构表 start with 1connect by prior id = parent_id start with id = 2; connect by id = prior parentid 原文:https://www.cnblogs.com/chenweichu/p/8921983.html
近来学习oracle,想要提高自己所写语句的效率和易读性,今天的笔记是关于子查询因子话这么一个东西 因子化的查询不一定可以提高效率,但是一定可以再提高程序的可读性方面成效显著--with 语句
with sales_c (select sales,e_NO,e_name from emplyee
)
select * from sales_c;
--查询的结果就是( select sales,e_NO,e_name from emplyee)这张字表中的内容
--with一次声明,在下面的例子中可以随意的使用,提升了代码的可读性--例如...
??select * from (select a.*,rownum as rn from tetm_ad_type a) b where b.rn<30
--表名不能用as 字段取别名,直接在表名后面跟一个newName 就算别名了。字段 名能够用as 取别名。 事实上我都是乱写的。 oralce原文:http://www.cnblogs.com/slgkaifa/p/7286891.html
Oracle_基本函数查询综合--【1】查询出每各月倒数第三天受雇的所有员工select * from emp where hiredate = last_day(hiredate)-2; --【2】找出早于30年前受雇的员工select * from emp where (sysdate - hiredate)/365>30;select * from emp where months_between(sysdate,hiredate)/12 > 30;select * from emp where to_char(sysdate,‘yyyy‘) - to_char(hiredate,‘yyyy‘)>30; --【3】以首字母大写的方式显示所有员工的姓名se...
不多说,直接上干货 1、查询当前用户下表的创建语句select dbms_metadata.get_ddl(‘TABLE‘,‘ux_future‘) from dual; 2、查询其他用户下表的创建语句select dbms_metadata.get_ddl(‘TABLE‘,‘ux_future‘,‘Admin‘) from dual; 3、查询当前用户下索引的创建语句select dbms_metadata.get_ddl(‘INDEX‘,‘ux_future‘) from dual; 4、查询其他用户下索引的创建语句select dbms_metadata.get_ddl(‘INDEX‘,‘ux_future‘,‘A...
在一些查询时,可能把握不准需要查询的确切值,比如百度搜索时输入关键字即可查询出相关的结果,这种查询称为模糊查询。
模糊查询使用LIKE关键字通过字符匹配检索出所需要的数据行。字符匹配操作可以使用通配符“%”和“_”:
%:表示零个或者多个任意字符。_:代表一个任意字符。语法是:LIKE ‘字符串‘[ESCAPE ‘字符‘]。匹配的字符串中,ESCAPE后面的“字符”作为转义字符。通配符表达式
‘S%‘ 以S开头的字符...
SQL>set autotrace traceonly statistics;
SQL>insertinto big_table_dir_test1 select*from big_table_dir_test;2853792 rows created.Statistics----------------------------------------------------------148 recursive calls358348 db block gets111261 consistent gets2 physical reads333542568 redo size832 bytes sent via SQL*Net to client817 bytes received via SQL*Net from client3 SQL*Net roundtrips to...
如TEST表有3表字段 id name address 如下:id name address1 小二 北京2 小二 东京3 小二 北京4 小刘 南京如要查出 name 和 address 重复的数据。 select * from ( select name,address,count(0) as mores from test group by name,address ) as a where a.mores > 1 此时查出的数据即是重复的数据,mores 显示的数量就是重复的数量。原文:http://www.cnblogs.com/ser0632/p/3964767.html
ORACLE:SELECT * FROM ( SELECT 表名.*, ROWNUM AS CON FROM 表名 WHERE ROWNUM <= 100 AND 其它查询条件 ORDER BY 排序条件 )WHERE CON >=10; MYSQL: select * from 表名 limit 10,100; 原文:http://www.cnblogs.com/renpei/p/5478736.html
--1)查询和定位数据库问题的SQL语句--Oracle常用性能监控SQL语句.sql--1查询锁表信息select vp.SPID, vs.P1, vs.P1RAW, vs.P2, vs.EVENT, vsql.SQL_TEXT, vsql.SQL_FULLTEXT, vsql.SQL_ID from v$session vs, v$sql vsql, v$process vp where vs.SQL_ID = vsql.SQL_ID and vs.PADDR = vp.ADDR and vs.WAIT_CLASS <> ‘Idle‘ ord...
select*from temp_info t innerjoin PURCHASE_BASE_INFO p on to_char(t.CREATE_TIME,‘yyyy-mm-dd‘) = to_char(p.CREATE_TIME,‘yyyy-mm-dd‘) 原文:https://www.cnblogs.com/wanlige/p/14542481.html
数据列表: table : textid datetime name value1 2015-03-1 张三 34002 2015-03-1 李四 25003 2015-03-2 张三 23004 2015-03-2 王五 2100 我要取得值是 最大时间的 name为张三的 value的值一般情况下,我们用的是 先把时间查询出来,然后根据时间再去查。但是这种情况是不符合我们现阶段要求的。 解决方法:select value from (select max(datetime) as datet...
高水位的介绍数据库运行了一段时间,经过一些列的删除、插入、更改操作有些表的高水位线就有可能和实际的表存储数据的情况相差特别多,为了提高检索该表的效率,建议对这些表进行收缩;查找高水位线的表查找表需要的存储空间:表以数据块的形式存储在数据文件中,表的存储结构是:行×行数,如果知道了总共有多少行,每行的平均长度,两者相乘,再除于90%的使用率,那么就可以知道实际需要存储的空间;表的存储结构;从统计信息得出平...
今天扒代码发现一个明细表(T_USER_INFO_LOG),但是代码里面找不到数据是何时插入的.同事提醒可能是在存储过程里面插入的数据. 下面SQL可以找到包含此表的存储过程 eg: SELECT DISTINCT NAME FROM user_source WHERE TYPE = ‘PROCEDURE‘ AND upper(text) LIKE ‘%T_USER_INFO_LOG%‘ ps: 注意表名或者关键字要大写原文:https://www.cnblogs.com/jijm123/p/14589658.html
1select * from t_hq_ryxx;2 3select nianl, xingm from t_hq_ryxx;4 5select nianl as 年龄, xingm as 姓名 from t_hq_ryxx t;6 7select nianl 年龄 from t_hq_ryxx;8 9select nianl || xingm as 年龄和姓名 from t_hq_ryxx;
1011select nianl as hhh,t.* from t_hq_ryxx t order by nianl desc ;--排序
1213select nianl as hhh,t.* from t_hq_ryxx t order by xingb desc ,bum desc;
1415select nianl,xingm,bum,xingb from t_h...