首页 / 邮件 / 朴素贝叶斯应用:垃圾邮件分类
朴素贝叶斯应用:垃圾邮件分类
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了朴素贝叶斯应用:垃圾邮件分类,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1961字,纯文字阅读大概需要3分钟。
内容图文

1. 数据准备:收集数据与读取
2. 数据预处理:处理数据
3. 训练集与测试集:将先验数据按一定比例进行拆分。
4. 提取数据特征,将文本解析为词向量 。
5. 训练模型:建立模型,用训练数据训练模型。即根据训练样本集,计算词项出现的概率P(xi|y),后得到各类下词汇出现概率的向量 。
6. 测试模型:用测试数据集评估模型预测的正确率。
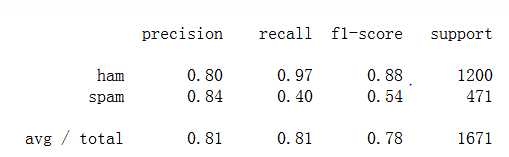
混淆矩阵
准确率、精确率、召回率、F值
7. 预测一封新邮件的类别。
#要点#
理解朴素贝叶斯算法
理解机器学习算法建模过程
理解文本常用处理流程
理解模型评估方法
#导入邮件数据
import csv
file_path=r‘F:\Pycharm\11.22\SMSSpamCollection‘
sms=open(file_path,‘r‘,encoding=‘utf-8‘)
sms_data=[]
sms_label=[]
csv_reader=csv.reader(sms,delimiter=‘\t‘)
for line in csv_reader:
sms_label.append(line[0])
sms_data.append(preprocessing(line[1]))
sms.close()
sms_data
#将数据分类并对模型进行类别预测
from sklearn.model_selection import train_test_split
x_train, x_text, y_train, y_test = train_test_split(sms_data, sms_label, test_size=0.3, random_state=0, stratify=sms_label)
from sklearn.feature_extraction.text import TfidfVectorizer #向量化
vectorizer=TfidfVectorizer(min_df=2,ngram_range=(1,2),stop_words=‘english‘,strip_accents=‘unicode‘,norm=‘12‘)
X_train=vectorizer.fit_transform(x_train)
X_text=vectorizer.transform(x_test)
X_train
a=X_train.toarray()
print(a)
for i in range(1000):
for j in range(5984):
if a[i,j]!=0:
print(i,j,a[i,j])
from sklearn.navie_bayes import MultinomialNB #导入贝叶斯分类器
clf= MultinomialNB().fit(X_train,y_train)
y_nb_pred=clf.predict(X_test)
from sklearn.metrics import confusion_matrix #导入混淆矩阵
from sklearn.metrics import classification_report #分类报告
print(y_nb_pred.shape,y_nb_pred)#预测结果
print(‘nb_confusion_matrix:‘)
cm=confusion_matrix(y_test,y_nb_pred)
print(cm)
print(‘nb_classification_report:‘)
cr=classification_report(y_test,y_nb_pred)#分类指标文本报告
print(cr)
feature_name=vectorizer.get_feature_name()
coefs=clf_coef_
intercept=clf.intercept_
coefs_with_fns=sorted(zip(coefs[0],feature_names))#对数概率p(x_i|y)与单词x_i映射
n=10
top=zip(coefs_with_fns[:n],coefs_with_fns[:-(n+1):-1])#最大的10个单词与最小的10个单词
for (coef_1,fn_1),(coef_2,fn_2) in top:
print(‘\t%.4f\t%-15s\t\t%.4f\t%-15s‘ % (coef_1,fn_1,coef_2,fn_2))
#运行结果
原文:https://www.cnblogs.com/MIS-67/p/10073390.html
内容总结
以上是互联网集市为您收集整理的朴素贝叶斯应用:垃圾邮件分类全部内容,希望文章能够帮你解决朴素贝叶斯应用:垃圾邮件分类所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。