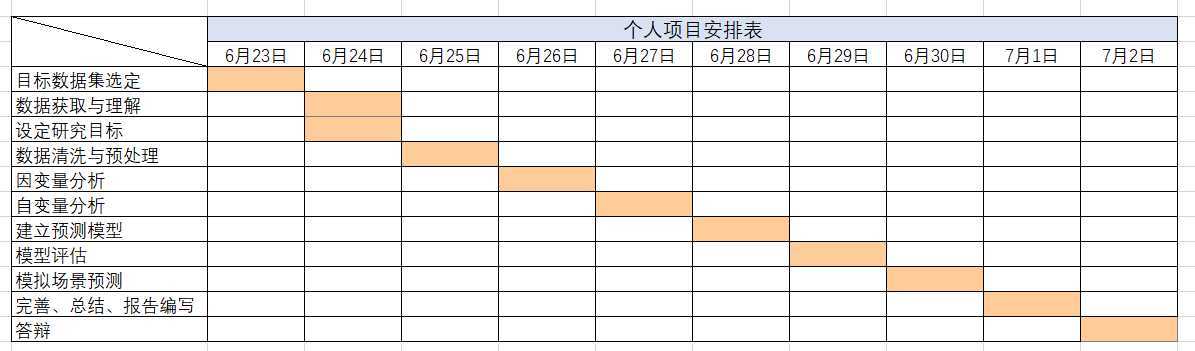
一、选题与意义1.Hadoop平台应用2.Kaggle分析数据项目简要说明理由与意义。选择Kaggle分析数据项目,电脑环境比较差对安装配置又比较不在行,故选择Kaggle上的项目进行分析。二、实践方案简要说明理由。选择了深圳市二手房房价数据进行研究。三、实践任务分解根据所选的题目,明确实验步骤,分解任务到每天1.目标数据选定2.数据获取与理解3.目标设定四、实践计划按任务分解撰写计划表,每天按计划表开展工作。根据实际情况更新计划...
mysql迁移之巨大数据量快速迁移方案-增量备份及恢复--chenjianwen一、前言: 当mysql库的大小达到几十个G或者上百G,迁移起来是一件非常费事的事情,业务中断,导出导入耗费大量的时间;所以,需要考虑怎么去节省时间的问题。二、方案: 1.制定维护时间,中断业务,登录 mysql,刷新日志 2.全备数据,备份后得到 binlog 日志文件 mysql-bin.000001 3.迁移走之前的 binlog 日志文件,只留下 mysql-bin.000001 4.恢复...
前些日子,公司要求做一个数据导入程序,要求将Excel数据,大批量的导入到数据库中,尽量少的访问数据库,高性能的对数据库进行存储。于是在网上进行查找,发现了一个比较好的解决方案,就是采用SqlBulkCopy来处理存储数据。SqlBulkCopy存储大批量的数据非常的高效,就像这个方法的名字一样,可以将内存中的数据表直接的一次性的存储到数据库中,而不需要一次一次的向数据库Insert数据。初次实验,百万级别的数据表,也只需几秒时间...
本文收藏于:http://kb.cnblogs.com/page/510982/作者: Divakar等 来源: DeveloperWorks 发布时间: 2015-01-29 18:21 推荐: 0 原文链接 [收藏] 摘要:本文中介绍的模式有助于定义大数据解决方案的参数。本文将介绍最常见的和经常发生的大数据问题以及它们的解决方案。原子模式描述了使用、处理、访问和存储大数据的典型方法。复合模式由原子模式组成,并根据大数据解决方案的范围进行分类。由于每个复合模式都有若干个维度...
1、用./bin/spark-shell启动spark时遇到异常:java.net.BindException: Can‘t assign requested address: Service ‘sparkDriver‘ failed after 16 retries!解决方法:add export SPARK_LOCAL_IP="127.0.0.1" to spark-env.sh2、java Kafka producer error:ERROR kafka.utils.Utils$ - fetching topic metadata for topics [Set(words_topic)] from broker [ArrayBuffer(id:0,host: xxxxxx,port:9092)] failed解决方法:Set ‘ad...
一、选题与意义1.Hadoop平台应用2.Kaggle分析数据项目简要说明理由与意义。二、实践方案三、实践任务分解根据所选的题目,明确实验步骤,分解任务到每天。四、实践计划按任务分解撰写计划表,每天按计划表开展工作。第天根据实际情况更新计划表,有必要时调整。 1、选题:淘宝双11数据分析与预测我选Hadoop平台应用-淘宝双11数据分析与预测因为自己机器学习的基础不是很牢固,所以不敢贸然选第二题,再加上从没接触过kaggle,时间...
一、引言: 最近一直很忙,在做一个全国性项目的IT架构,所以一直没有更新,好在算是告一段落,继续努力吧。项目沟通中过程客户反复在强调,大数据的安全性,言下之意,用了大数据,就不安全了,就有漏洞了。所以花了些时间,针对大数据的安全设计做了一个总结,算是阶段性的成果吧,分享给大家。二、安全架构 大数据安全架构主要从六个方面考虑,包括物理安全、系统安全、网络安全、应用安全、数据安全和管理安全六个维度。...
大数据提取价值信息技术实现方案分5步:1、通过FTP采集文件2、把文件入到HDFS系统3、使用HIVE从HDFS中选择数据4、使用DataStage或Infomatica把数据入库5、入库到Sybase IQ数据库注意事项:1、不一定用ftp采集文件,反正只要把海量文件采集过来即可;2、采集的源文件一定是海量的,可以文件数海量,也可以文件里的内容海量,要不然就不叫大数据了;3、这里面主要用到了hadoop的hdfs,没有用到mapreduce;4、mapreduce其实是hive帮你...
一、数据入库方式目前批量数据入库TDH大数据平台主要有如下几种方式1、手工入录一些静态表手工维护的数据,可以直接采用insert导入,或者使用waterdrop客户端工具导入,只适用少数据量的导入和更新2、dblinkTDH inceptor支持建立dblink直接连接db2,oracle,mysql等关系数据库,对于一些数据量不大的静态表,手工维护的表,可以通过建立dblink的方式获取数据优点:简单方便缺点:1)对大数据量的表,效率较差 2)初次使用相应数...
如何从Linux起步,开发出搭载Android系统并且具备深度定制和软硬整合能力特色产品,是本课程解决的问题。课程以Android的五大核心:HAL、Binder、Native
Service、Android Service(并以AMS和WMS为例)、View System为主轴,一次性彻底掌握Android的精髓。之所以是开发Android产品的必修课,缘起于:1,
HAL是Android Framework&Application与底层硬件整合的关键技术和必修技术;2,
Native Service 对上层来说代表了硬...
本文背景本文主要讨论顺序答题环节,如果题库数据量过大如何应对本文内容具体讨论一个题库有3000道题目,如何做到顺序刷题 (方案1)设置一个起始题目的标志数字,做一题,标志数字+1第一次进入顺序答题模块,从题库的第1题开始,展示1-100题,比如从第1题做到第10题,下次再进入顺序答题模块,从第11题开始获取,第11题-第110题,新的100题,直到刷完一遍为止。本文总结目前这个方案可有效应对单一题库题目过大的问题原文:https:...
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西。
1、SQLSERVER优点和缺点?
优点:支持索引、事务、安全性以及容错性高
缺点:数据量达到100万以上就需要开始优化了,一般我们会对 表进行水平拆分,分表、分区和作业同步等,这样做大大提高了逻辑的复杂性,难以维护,只有群集容错,没有多库负载均衡并行计算功能。
2、SQLSERVER真的不能处理大数据?
答案:当然可...
然后我们再来看一个hadoop,官方提供的一个案例,我运行起来看看效果.
按照上面的过程我们来做一下上面是文档上的整个流程.首先我们还是创建,输入文件夹
wcinput
然后进入这个文件夹wcinput
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 架构原理(Architecture) 测试环境(Environment) 安装Moebius(Install) Moebius测试(Testing) 负载均衡测试(Load Balancing Testing) 高可用性测试(Failover Testing) 数据安全性测试(Security Testing) 总结(Summary) 二.背景(Contexts) 前几天在SQL Server MVP宋大侠(宋沄剑)的一篇文章"数据库集群技...
随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战。下面分享下对实际10万+峰值的平台的数据库优化方案。与大家一起讨论,互相学习提高!案例:游戏平台.1、解决高并发当客户端连接数达到峰值的时候,服务端对连接的维护与处理这里暂时不做讨论。当多个写请求到数据库的时候,这时候需要对多张表进行插入,尤其一些表 达到每天千万+的存储,随着时间的积累,传统的同步写入数据的方式显然不可取,经过试验,通...