首页 / IDEA / IDEA中环境配置和使用
IDEA中环境配置和使用
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了IDEA中环境配置和使用,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5889字,纯文字阅读大概需要9分钟。
内容图文

pom.xml文件配置
1
<!--
声明公有的属性
-->
2
<
properties
>
3
<
maven.compiler.source
>1.8</maven.compiler.source> 4<maven.compiler.target>1.8</maven.compiler.target> 5<encoding>UTF-8</encoding> 6<scala.version>2.11.8</scala.version> 7<spark.version>2.2.0</spark.version> 8<hadoop.version>2.7.1</hadoop.version> 9<scala.compat.version>2.11</scala.compat.version>10</properties>11<!-- 声明并引入公有的依赖 -->12<dependencies>13<dependency>14<groupId>org.scala-lang</groupId>15<artifactId>scala-library</artifactId>16<version>${scala.version}</version>17</dependency>18<dependency>19<groupId>org.apache.spark</groupId>20<artifactId>spark-core_2.11</artifactId>21<version>${spark.version}</version>22</dependency>23<dependency>24<groupId>org.apache.hadoop</groupId>25<artifactId>hadoop-client</artifactId>26<version>${hadoop.version}</version>27</dependency>28</dependencies>2930<!-- 配置构建信息 -->31<build>32<!-- 资源文件夹 -->33<sourceDirectory>src/main/scala</sourceDirectory>34<!-- 声明并引入构建的插件 -->35<plugins>36<!-- 用于编译Scala代码到class -->37<plugin>38<groupId>net.alchim31.maven</groupId>39<artifactId>scala-maven-plugin</artifactId>40<version>3.2.2</version>41<executions>42<execution>43<goals>44<goal>compile</goal>45<goal>testCompile</goal>46</goals>47<configuration>48<args>49<arg>-dependencyfile</arg>50<arg>${project.build.directory}/.scala_dependencies</arg>51</args>52</configuration>53</execution>54</executions>55</plugin>56<plugin>57<!-- 程序打包 -->58<groupId>org.apache.maven.plugins</groupId>59<artifactId>maven-shade-plugin</artifactId>60<version>2.4.3</version>61<executions>62<execution>63<phase>package</phase>64<goals>65<goal>shade</goal>66</goals>67<configuration>68<!-- 过滤掉以下文件,不打包 :解决包重复引用导致的打包错误-->69<filters>70<filter><artifact>*:*</artifact>71<excludes>72<exclude>META-INF/*.SF</exclude>73<exclude>META-INF/*.DSA</exclude>74<exclude>META-INF/*.RSA</exclude>75</excludes>76</filter>77</filters>78<transformers>79<!-- 打成可执行的jar包 的主方法入口-->80<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">81<mainClass></mainClass>82</transformer>83</transformers>84</configuration>85</execution>86</executions>87</plugin>88</plugins>89</build>
第一个WordCount
1
package
SparkCore_01
2
3
import
org.apache.spark.rdd.RDD
4
import
org.apache.spark.{SparkConf, SparkContext}
5
6
/**
7
* 第一个Spark程序
8
*/
9
object SparkWordCount {
10
//
Spark程序都需要使用main
11 def main(args: Array[String]): Unit = {
12//0.构建系统环境变量,为了SparkContext加在环境变量所使用13/*14 三个核心方法
15 set(key,value) --> 主要应对的是 环境变量设置 key 环境变量名 value 是具体值
16 setAppName(name) --> 设置程序运行的名称
17 setMaster(执行方式),如果需要运行本地环境,那么就需要配置SetMaster这个值
18 "local" --> 代表本地模式,相当于启用一个线程来模拟Spark运行
19 "local[数值]" --> 代表本地模式, 根据数值来决定启用多少个线程来模拟spark运行
20 ps:数值不能大于当前cpu 核心数
21 "local[*]" --> 代表本地模式 * 相当于是系统空闲多少线程就用多少线程来执行spark程序
22*/23 val conf =new SparkConf().setAppName("SparkWordCount").setMaster("local")
24//1.先构建SparkContext对象,需要对SparkContext对象进行环境配置即将conf对象传入到SparkContext中25 val sc = new SparkContext(conf)
2627//Spark对数据的处理
28//1.读取文件内容,参数是文件路径(多用于读取txt或log文件)29 val lines: RDD[String] = sc.textFile("dir/SparkCore_01/File.txt")
30//2.对文件中数据进行切分处理31 val words: RDD[String] = lines.flatMap(_.split(" "))
32//3.对单词进行统计之前,需要对单词的个数进行计数33 val tuples: RDD[(String, Int)] = words.map((_,1))
34//Spark中提供了一个根据key计算value的算子(这个算子是你使用最广泛一个算子),相同key为一组计算一次value的值35 val sumed: RDD[(String, Int)] = tuples.reduceByKey(_+_)
3637//println(sumed.collect().toList)3839 sc.stop()//关闭Sparkcontext
404142//提交集群版本(修改位置):
43//sc.textFile(args(0)) //获取外部输入读取数据路径
44//将数据文件存储到集群(也可以存储在本地)没有返回值
45// sumed.saveAsTextFile(args(1)) // 获取外部输入的存储路径 ,不要打印语句46 }
47 }
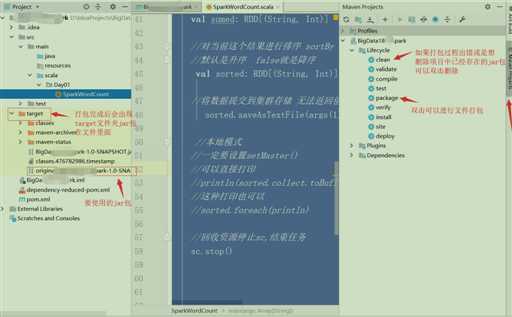
程序打包提交集群

将jar包上传到对应节点,然后在Spark安装目录下bin目录下执行以下操作
./spark-submit \
> --class SparkCore_01.SparkWordCount\
> --master spark://hadoop01:7077 \
> --executor-memory 512m \
> --total-executor-cores 2 \
> /root/Spark_1905-1.0-SNAPSHOT.jar hdfs://hadoop01:8020/word.txt hdfs://hadoop01:8020/out2
ps: jar包所在路径 hdfs集群读取文件 写入到hdfs集群中
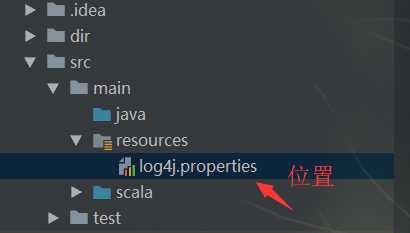
去掉打印日志
log4j.properties
1 # contributor license agreements. See the NOTICE file distributed with
2 # this work for additional information regarding copyright ownership.
3 # The ASF licenses this file to You under the Apache License, Version 2.0 4 # (the "License"); you may not use this file except in compliance with
5 # the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0 8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and13 # limitations under the License.
14 #
15 # Set everything to be logged to the console
16 # 修改此处更改显示信息级别
17 log4j.rootCategory=ERROR, console
18 log4j.appender.console=org.apache.log4j.ConsoleAppender
19 log4j.appender.console.target=System.err
20 log4j.appender.console.layout=org.apache.log4j.PatternLayout
21 log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n

原文:https://www.cnblogs.com/yumengfei/p/12028338.html
内容总结
以上是互联网集市为您收集整理的IDEA中环境配置和使用全部内容,希望文章能够帮你解决IDEA中环境配置和使用所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。