首页 / JAVA / java实训一——词频统计
java实训一——词频统计
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了java实训一——词频统计,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2505字,纯文字阅读大概需要4分钟。
内容图文

---恢复内容开始---
驾驶员:葛晨延(16012010)
领航员:张广哲(16012007)
码云:https://gitee.com/happywindmannn/GCYshixun1/tree/master
实训过程照片:

1
import java.io.*;
2import java.util.*;
3import java.io.BufferedReader;
4import java.io.FileReader;
5import java.util.ArrayList;
6import java.util.Map;
7import java.util.List;
8import java.util.Map.Entry;
9import java.util.TreeMap;
10publicclass wtf{
11publicstaticvoid main(String args[])throws Exception{
12 StringBuilder result = new StringBuilder();
13 BufferedReader file = new BufferedReader(new FileReader("D:\\javas\\a.txt"));
14 List<String> s =new ArrayList<String>();
15 String s1 = null;
16while((s1 = file.readLine()) != null){
17 String [] s2 = s1.split("[[^a-zA-Z]]");
18for(String s3 : s2){
19if(s3.length() != 0){
20 s.add(s3);
21 }
22 }
23 }
24 Map<String, Integer> TreeMap = new TreeMap<String,Integer>();
25for(String s4:s){
26if(TreeMap.get(s4) != null){
27 TreeMap.put(s4,TreeMap.get(s4)+1);
28 }
29else{
30 TreeMap.put(s4,1);
31 }
32 }
333435 System.out.println("以下是本文章中出现单词频率前十的单词,以及频率:\t");
36 showmap(TreeMap);
37 file.close();
38 }
39publicstaticvoid showmap(Map<String,Integer> oldmap){
4041 ArrayList<Map.Entry<String,Integer>> map = new ArrayList<Map.Entry<String,Integer>>(oldmap.entrySet());
4243 Collections.sort(map,new Comparator<Map.Entry<String,Integer>>(){
4445publicint compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
46return o2.getValue() - o1.getValue();
47 }
48 });
4950for(int i = 0; i<10; i++){
5152 System.out.println(map.get(i).getKey()+ ": " +map.get(i).getValue());
53 }
54 }
5556 }
运行结果:
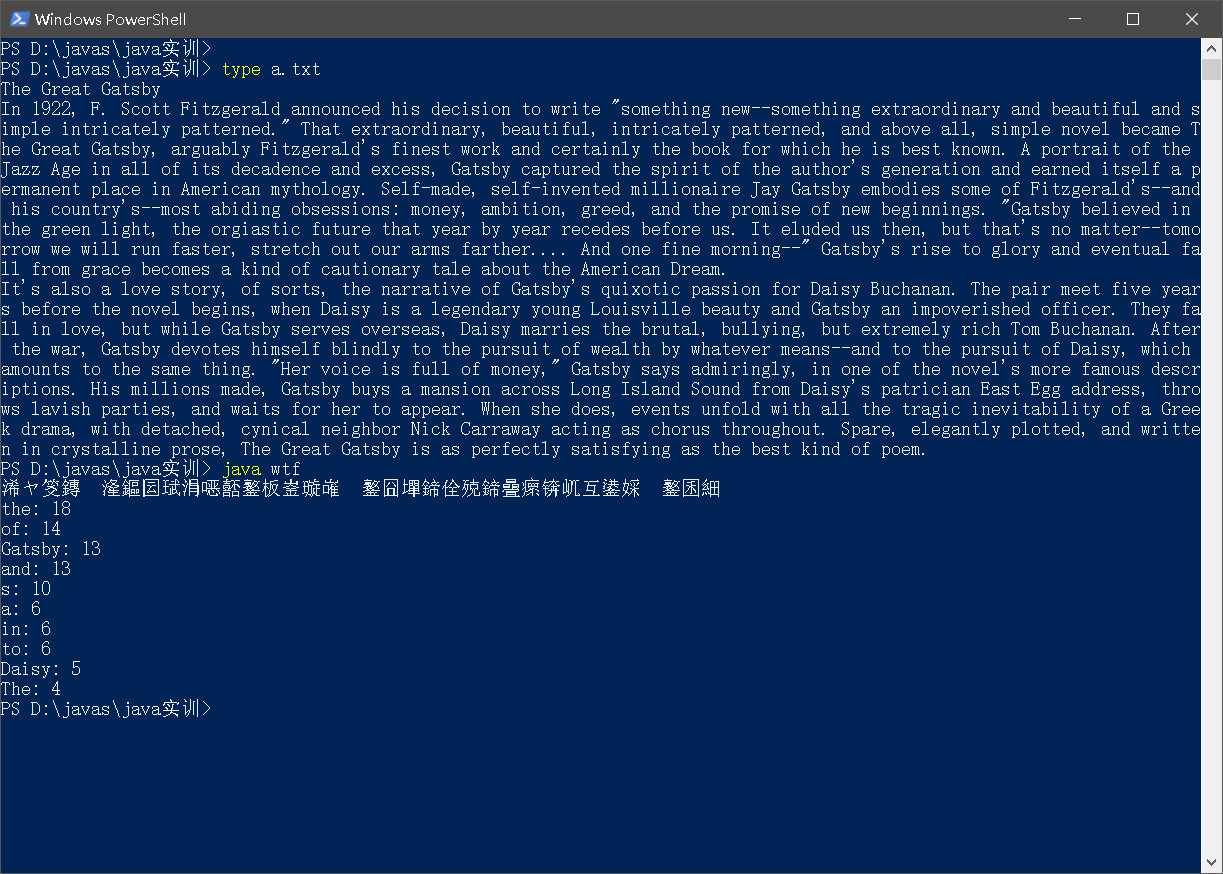
需求:
1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符。
2.统计英文单词在本文件的出现次数
3.将统计结果排序
4.显示排序结果
解题思路:
x代表对象
1.BufferedReader x = new BufferedReader(new FileReader(文件绝对路径));
缓冲流,更加油效率的读取文件,缓冲访问区(类似于内存条)。
另有方法readline()按行读取可以使用。
相比InputStream()字节流,FileReader()字符流更快。
2.List<String> x = new ArrayList<String>();
创建动态数组,<>中的位数组类型,如int,double,String。
该数组用于存储文章的所有单词。
3. String[] x = readLine.split("[^a-zA-Z]");
创建数组,用readLine()逐行过滤,括号内位正则表达式。
4.for(String x:y){}
“增强的for循环”,x为字符串,y为字符数组
作用是将数组内所有元素,赋值到x中,有多少元素创建多少个x。
5.Map<String, Integer> x = new TreeMap<String,Integer>();
HashMap<String, Integer> x = new HashMap<String, Integer>();
map树(有序) hashmap哈希表(无序)
存储单词计数信息,Stinrg是key值为单词,Integer是value为词频
map.put(k,v)给表赋值
map.get(key)获取key的value
ps:因为某些不可抗力原因程序还不够完整,由下次实训补全。
---恢复内容结束---
原文:https://www.cnblogs.com/happywindman/p/10116015.html
内容总结
以上是互联网集市为您收集整理的java实训一——词频统计全部内容,希望文章能够帮你解决java实训一——词频统计所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。