首页 / 正则 / python中正则表达式的详细介绍
python中正则表达式的详细介绍
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python中正则表达式的详细介绍,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4147字,纯文字阅读大概需要6分钟。
内容图文
 本篇文章给大家带来的内容是关于python中正则表达式的详细介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
本篇文章给大家带来的内容是关于python中正则表达式的详细介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。正则
re = regular experssion
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
作用: 对于字符串进行处理, 会检查这个字符串内容是否与你写的正则表达式匹配
如果匹配, 拿出匹配的内容;如果不匹配, 忽略不匹配内容;
编写正则的规则
pattern 匹配的正则表达式
string 要匹配的字符串
三种查找方法
1). findall
import re str = 'hello sheen,hello cute.' pattern_1 = r'hello' pattern_2 = r'sheen' print(re.findall(pattern_1,str)) #['hello', 'hello'] print(re.findall(pattern_2,str)) #['sheen']
2).match
match尝试从字符串的起始位置开始匹配,
如果起始位置没有匹配成功, 返回一个None;
如果起始位置匹配成功, 返回一个对象;
import re str = 'hello sheen,hello cute.' pattern_1 = r'hello' pattern_2 = r'sheen' print(re.match(pattern_1,str)) #<_sre.SRE_Match object; span=(0, 5), match='hello'> print(re.match(pattern_1,str).group()) #返回match匹配的字符串内容,hello print(re.match(pattern_2,str)) #None
3).search
search会扫描整个字符串, 只返回第一个匹配成功的内容;
如果能找到, 返回一个对象, 通过group方法获取对应的字符串;
import re str = 'hello sheen,hello cute.' pattern_1 = r'hello' pattern_2 = r'sheen' print(re.search(pattern_1,str)) #<_sre.SRE_Match object; span=(0, 5), match='hello'> print(re.search(pattern_1,str).group()) #hello print(re.search(pattern_2,str)) #<_sre.SRE_Match object; span=(6, 11), match='sheen'> print(re.search(pattern_2,str).group()) #sheen
特殊字符类
.: 匹配除了\n之外的任意字符; [.\n]
\d: digit--(数字), 匹配一个数字字符, 等价于[0-9]
\D: 匹配一个非数字字符, 等价于[^0-9]
\s: space(广义的空格: 空格, \t, \n, \r), 匹配单个任何的空白字符;
\S: 匹配除了单个任何的空白字符;
\w: 字母数字或者下划线, [a-zA-Z0-9_]
\W: 除了字母数字或者下划线, [^a-zA-Z0-9_]
import re # . print(re.findall(r'.','sheen\nstar\n')) #['s', 'h', 'e', 'e', 'n', 's', 't', 'a', 'r'] #\d#\D print(re.findall(r'\d','当前声望30')) #['3', '0'] print(re.findall(r'\D','当前声望30')) #['当', '前', '声', '望'] #\s#\S print(re.findall(r'\s', '\n当前\r声望\t为30')) #['\n', '\r', '\t'] print(re.findall(r'\S', '\n当前\r声望\t为30')) #['当', '前', '声', '望', '为', '3', '0'] #\w#\W print(re.findall(r'\w','lucky超可爱!!')) #['l', 'u', 'c', 'k', 'y', '超', '可', '爱'] print(re.findall(r'\W','lucky超可爱!!')) #['!', '!']

指定字符出现次数
匹配字符出现次数:
*: 代表前一个字符出现0次或者无限次; d*, .*
+: 代表前一个字符出现一次或者无限次; d+
?: 代表前一个字符出现1次或者0次; 假设某些字符可省略, 也可以不省略的时候使用
第二种方式:
{m}: 前一个字符出现m次;
{m,}: 前一个字符至少出现m次; * == {0,}; + ==={1,}
{m,n}: 前一个字符出现m次到n次; ? === {0,1}
import re
#* 代表前一个字符出现0次或者无限次
print(re.findall(r's*','sheenstar')) #['s', '', '', '', '', 's', '', '', '', '']
print(re.findall(r's*','hello')) #['', '', '', '', '', '']
#+ 代表前一个字符出现一次或者无限次
print(re.findall(r's+','sheenstar')) #['s', 's']
print(re.findall(r's+','hello')) #[]
# ? 代表前一个字符出现1次或者0次
print(re.findall(r'188-?', '188 6543')) #['188']
print(re.findall(r'188-?', '188-6543')) #['188-']
print(re.findall(r'188-?', '148-6543')) #[]
# 匹配电话号码
pattern = r'\d{3}[\s-]?\d{4}[\s-]?\d{4}'
print(re.findall(pattern,'188 0123 4567')) #['188 0123 4567']
print(re.findall(pattern,'188-0123-4567')) #['188-0123-4567']
print(re.findall(pattern,'18801234567')) #['188-0123-4567']练习--匹配IP
可以从网上搜索正则表达式生成器,使用别人写好的规则,自己测试。
import re
# | 表示或者
pattern = r'(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)$'
print(re.findall(pattern,'172.25.254.34')) #[('172', '25', '254', '34')]
matchObj_1 = re.match(pattern,'172.25.254.34')
if matchObj_1:
print('匹配项:',matchObj_1.group()) #172.25.254.34
else:
print('未找到匹配项')
matchObj_2 = re.match(pattern,'172.25.254.343')
if matchObj_2:
print('匹配项:',matchObj_2.group())
else:
print('未找到匹配项')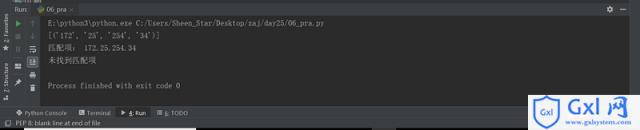
以上就是python中正则表达式的详细介绍的详细内容,更多请关注Gxl网其它相关文章!
内容总结
以上是互联网集市为您收集整理的python中正则表达式的详细介绍全部内容,希望文章能够帮你解决python中正则表达式的详细介绍所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。