MySQL 重复索引探讨(持续更新中...)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了MySQL 重复索引探讨(持续更新中...),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3937字,纯文字阅读大概需要6分钟。
内容图文
")
<一> 创建‘有问题的‘表
1.创建表test1
CREATE TABLE test1 ( id int(11) NOT NULL, f1 int(11) DEFAULT NULL, f2 int(11) DEFAULT NULL, f3 int(11) DEFAULT NULL, PRIMARY KEY (id), KEY k1 (f1,id), KEY k2 (id,f1), KEY k3 (f1), KEY k4 (f1,f3), KEY k5 (f1,f3,f2) )
2.创建表 test2
CREATE TABLE test2 ( id1 int(11) NOT NULL DEFAULT 0, id2 int(11) NOT NULL DEFAULT 0, b int(11) DEFAULT NULL, PRIMARY KEY (id1,id2), KEY k1 (b) )
<二> 存在问题的索引
1. 包含主键的索引
innodb 本身是聚簇表,每个二级索引本身就包含主键,类似f1,id 的索引,虽然实际没什么害处,但反映使用者对mysql 索引的不了解。而 id,f1 这种多余索引,会浪费存储空间,并影响数据更新性能。包含主键的索引用这样一句sql 就能全部找出来:
select c.*, pk from (select table_schema, table_name, index_name, concat(‘|‘, group_concat(column_name order by seq_in_index separator ‘|‘), ‘|‘) cols from INFORMATION_SCHEMA.STATISTICS where index_name != ‘PRIMARY‘ and table_schema != ‘mysql‘ group by table_schema, table_name, index_name) c, (select table_schema, table_name, concat(‘|‘, group_concat(column_name order by seq_in_index separator ‘|‘), ‘|‘) pk from INFORMATION_SCHEMA.STATISTICS where index_name = ‘PRIMARY‘ and table_schema != ‘mysql‘ group by table_schema, table_name) p where c.table_name = p.table_name and c.table_schema = p.table_schema and c.cols like concat(‘%‘, pk, ‘%‘);
结果:

2.重复的索引
包含重复前缀的索引,索引能由另一个包含该前缀的索引完全代替,是多余索引。多余的索引会浪费存储空间,并影响数据更新性能。这样的索引同样用一句 sql 可以找出来。
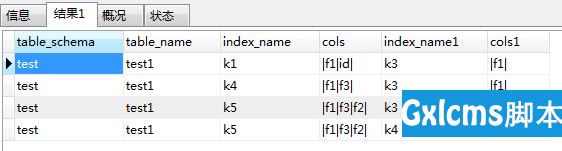
select c1.table_schema, c1.table_name, c1.index_name,c1.cols,c2.index_name, c2.cols from (select table_schema, table_name, index_name, concat(‘|‘, group_concat(column_name order by seq_in_index separator ‘|‘), ‘|‘) cols from INFORMATION_SCHEMA.STATISTICS where table_schema != ‘mysql‘ and index_name!=‘PRIMARY‘ group by table_schema,table_name,index_name) c1, (select table_schema, table_name,index_name, concat(‘|‘, group_concat(column_name order by seq_in_index separator ‘|‘), ‘|‘) cols from INFORMATION_SCHEMA.STATISTICS where table_schema != ‘mysql‘ and index_name != ‘PRIMARY‘ group by table_schema, table_name, index_name) c2 where c1.table_name = c2.table_name and c1.table_schema = c2.table_schema and c1.cols like concat(c2.cols, ‘%‘) and c1.index_name != c2.index_name;
结果:
3. 低区分度索引
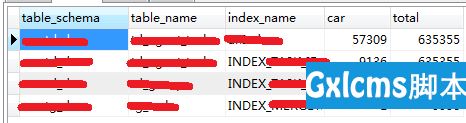
这样的索引由于仍然会扫描大量记录,在实际查询时通常会被忽略。但是在某些情况下仍然是有用的。因此需要根据实际情况进一步分析。这里是区分度小于 10% 的索引,可以根据需要调整参数。
select p.table_schema, p.table_name, c.index_name, c.car, p.car total from (select table_schema, table_name, index_name, max(cardinality) car from INFORMATION_SCHEMA.STATISTICS where index_name != ‘PRIMARY‘ group by table_schema, table_name,index_name) c, (select table_schema, table_name, max(cardinality) car from INFORMATION_SCHEMA.STATISTICS where index_name = ‘PRIMARY‘ and table_schema != ‘mysql‘ group by table_schema,table_name) p where c.table_name = p.table_name and c.table_schema = p.table_schema and p.car > 0 and c.car / p.car < 0.1;
结果:
4. 复合主键
由于 innodb 是聚簇表,每个二级索引都会包含主键值。复合主键会造成二级索引庞大,而影响二级索引查询性能,并影响更新性能。同样需要根据实际情况进一步分析。
sql 为:
select table_schema, table_name, group_concat(column_name order by seq_in_index separator ‘,‘) cols, max(seq_in_index) len from INFORMATION_SCHEMA.STATISTICS where index_name = ‘PRIMARY‘ and table_schema != ‘mysql‘ group by table_schema, table_name having len>1;
结果为:

MySQL 重复索引探讨(持续更新中...)
标签:
本文系统来源:http://my.oschina.net/pingjiangyetan/blog/514623
内容总结
以上是互联网集市为您收集整理的MySQL 重复索引探讨(持续更新中...)全部内容,希望文章能够帮你解决MySQL 重复索引探讨(持续更新中...)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。