hadoop生态系统学习之路(九)MR将结果输出到数据库(DB)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了hadoop生态系统学习之路(九)MR将结果输出到数据库(DB),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含8617字,纯文字阅读大概需要13分钟。
内容图文
MR将结果输出到数据库(DB)") <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
二、数据以及数据库表准备
我们还是使用之前博文中入到hive的输入文件user_info.txt,放在hdfs中的/qiyongkang/input目录下:
11 1200.0 qyk1 21
22 1301 qyk2 22
33 1400.0 qyk3 23
44 1500.0 qyk4 24
55 1210.0 qyk5 25
66 124 qyk6 26
77 1233 qyk7 27
88 15011 qyk8 28然后,我们这里使用的是mysql数据库,在test数据库建表:
CREATE TABLE `user_info` (
`id` bigint(20) DEFAULT NULL,
`account` varchar(50) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8三、MR编写
首先,我们来看主类LoadDataToDbMR:
/**
* Project Name:mr-demo
* File Name:LoadDataToDbMR.java
* Package Name:org.qiyongkang.mr.dbstore
* Date:2016年4月10日下午3:16:05
* Copyright (c) 2016, CANNIKIN(http://http://code.taobao.org/p/cannikin/src/) All Rights Reserved.
*
*/
package org.qiyongkang.mr.dbstore;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
/**
* ClassName:LoadDataToDbMR <br/>
* Function: TODO ADD FUNCTION. <br/>
* Reason: TODO ADD REASON. <br/>
* Date: 2016年4月10日 下午3:16:05 <br/>
* @author qiyongkang
* @version
* @since JDK 1.6
* @see
*/
public class LoadDataToDbMR {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//数据库配置
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver","jdbc:mysql://192.168.52.31:3306/test","root", "root");
Job job = Job.getInstance(conf, "db store");
job.setJarByClass(LoadDataToDbMR.class);
// 设置Mapper
job.setMapperClass(DbStoreMapper.class);
// 由于没有reducer,这里设置为0
job.setNumReduceTasks(0);
// 设置输入文件路径
FileInputFormat.addInputPath(job, new Path("/qiyongkang/input"));
DBOutputFormat.setOutput(job, "user_info", "id", "account", "name", "age");
job.setOutputFormatClass(DBOutputFormat.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
然后,我们再来看Mapper:
/**
* Project Name:mr-demo
* File Name:DbStoreMapper.java
* Package Name:org.qiyongkang.mr.dbstore
* Date:2016年4月10日下午3:15:46
* Copyright (c) 2016, CANNIKIN(http://http://code.taobao.org/p/cannikin/src/) All Rights Reserved.
*
*/
package org.qiyongkang.mr.dbstore;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* ClassName:DbStoreMapper <br/>
* Function: TODO ADD FUNCTION. <br/>
* Reason: TODO ADD REASON. <br/>
* Date: 2016年4月10日 下午3:15:46 <br/>
*
* @author qiyongkang
* @version
* @since JDK 1.6
* @see
*/
public class DbStoreMapper extends Mapper<LongWritable, Text, UserInfoDBWritable, UserInfoDBWritable> {
private UserInfo userInfo = new UserInfo();
private UserInfoDBWritable userInfoDBWritable = null;
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, UserInfoDBWritable, UserInfoDBWritable>.Context context)
throws IOException, InterruptedException {
// 每行以制表符分隔 id, account, name, age
String[] strs = value.toString().split("\t");
// id,
userInfo.setId(Long.valueOf(strs[0]));
// account
userInfo.setAccount(strs[1]);
// name
userInfo.setName(strs[2]);
// age
userInfo.setAge(Integer.valueOf(strs[3]));
// 写入到db,放在key
userInfoDBWritable = new UserInfoDBWritable(userInfo);
context.write(userInfoDBWritable , null);
}
}
这里,我们准备了一个Model,UserInfo:
/**
* Project Name:mr-demo
* File Name:UserInfo.java
* Package Name:org.qiyongkang.mr.dbstore
* Date:2016年4月10日下午3:30:01
* Copyright (c) 2016, CANNIKIN(http://http://code.taobao.org/p/cannikin/src/) All Rights Reserved.
*
*/
package org.qiyongkang.mr.dbstore;
/**
* ClassName:UserInfo <br/>
* Function: TODO ADD FUNCTION. <br/>
* Reason: TODO ADD REASON. <br/>
* Date: 2016年4月10日 下午3:30:01 <br/>
* @author qiyongkang
* @version
* @since JDK 1.6
* @see
*/
public class UserInfo {
private long id;
private String account;
private String name;
private int age;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getAccount() {
return account;
}
public void setAccount(String account) {
this.account = account;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
然后,我们要想MR输出到Db,那么此类必须实现DBWritable,如下:
/**
* Project Name:mr-demo
* File Name:UserInfoDBWritable.java
* Package Name:org.qiyongkang.mr.dbstore
* Date:2016年4月10日下午3:27:32
* Copyright (c) 2016, CANNIKIN(http://http://code.taobao.org/p/cannikin/src/) All Rights Reserved.
*
*/
package org.qiyongkang.mr.dbstore;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
/**
* ClassName:UserInfoDBWritable <br/>
* Function: TODO ADD FUNCTION. <br/>
* Reason: TODO ADD REASON. <br/>
* Date: 2016年4月10日 下午3:27:32 <br/>
* @author qiyongkang
* @version
* @since JDK 1.6
* @see
*/
public class UserInfoDBWritable implements DBWritable {
private UserInfo userInfo;
public UserInfoDBWritable() {}
public UserInfoDBWritable(UserInfo userInfo) {
this.userInfo = userInfo;
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setLong(1, userInfo.getId());
statement.setString(2, userInfo.getAccount());
statement.setString(3, userInfo.getName());
statement.setInt(4, userInfo.getAge());
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
}
}
这里面的参数设置顺序与主类中设置DBOutputFormat时的字段顺序一致。
四、执行并查看结果
下面,还是同样的打包方式,只需修改下main函数所在的类即可。然后,上传到主节点,使用hdfs用户执行,注意此jar的权限设置。
接下来,执行yarn jar mr-demo-0.0.1-SNAPSHOT-jar-with-dependencies.jar,日志如下:
bash-4.1$ yarn jar mr-demo-0.0.1-SNAPSHOT-jar-with-dependencies.jar
16/04/10 16:14:11 INFO client.RMProxy: Connecting to ResourceManager at massdata8/172.31.25.8:8032
16/04/10 16:14:12 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/04/10 16:14:13 INFO input.FileInputFormat: Total input paths to process : 1
16/04/10 16:14:13 INFO mapreduce.JobSubmitter: number of splits:1
16/04/10 16:14:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1458262657013_0982
16/04/10 16:14:14 INFO impl.YarnClientImpl: Submitted application application_1458262657013_0982
16/04/10 16:14:14 INFO mapreduce.Job: The url to track the job: http://massdata8:8088/proxy/application_1458262657013_0982/
16/04/10 16:14:14 INFO mapreduce.Job: Running job: job_1458262657013_0982
16/04/10 16:14:21 INFO mapreduce.Job: Job job_1458262657013_0982 running in uber mode : false
16/04/10 16:14:21 INFO mapreduce.Job: map 0% reduce 0%
16/04/10 16:14:29 INFO mapreduce.Job: map 100% reduce 0%
16/04/10 16:14:29 INFO mapreduce.Job: Job job_1458262657013_0982 completed successfully
16/04/10 16:14:29 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=91506
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=259
HDFS: Number of bytes written=0
HDFS: Number of read operations=2
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
Job Counters
Launched map tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4459
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=4459
Total vcore-seconds taken by all map tasks=4459
Total megabyte-seconds taken by all map tasks=4566016
Map-Reduce Framework
Map input records=8
Map output records=8
Input split bytes=117
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=21
CPU time spent (ms)=1530
Physical memory (bytes) snapshot=321511424
Virtual memory (bytes) snapshot=1579036672
Total committed heap usage (bytes)=792199168
File Input Format Counters
Bytes Read=142
File Output Format Counters
Bytes Written=0然后,我们在数据库执行查询SELECT * FROM user_info;可以看到:
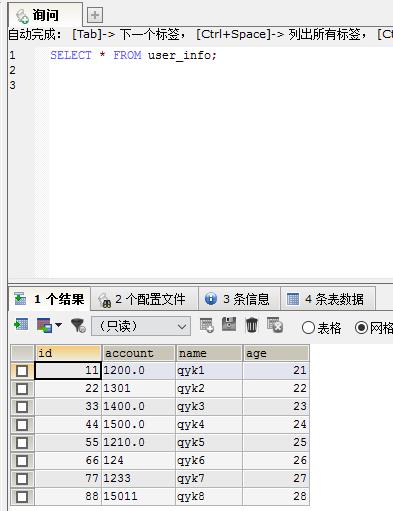
说明入库成功!
好了,就介绍到这儿了。
hadoop生态系统学习之路(九)MR将结果输出到数据库(DB)
标签:
本文系统来源:http://blog.csdn.net/qiyongkang520/article/details/51113477
内容总结
以上是互联网集市为您收集整理的hadoop生态系统学习之路(九)MR将结果输出到数据库(DB)全部内容,希望文章能够帮你解决hadoop生态系统学习之路(九)MR将结果输出到数据库(DB)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。