600多G数据库的sphinx全文检索案例
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了600多G数据库的sphinx全文检索案例,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2987字,纯文字阅读大概需要5分钟。
内容图文

社工库的规模越来越大,MSSQL的查询速度已经不够用了,改用全文检索,目前效果不错,全库在650G左右,索引160G,全文检索响应时间在5秒以内。
主要参考了The Web Of Answers的一个搭建帖子,具体链接找不到了,做了很多修改和改进,便于添加新库。
给出一些配置信息,有兴趣的同学可以留言交流。
索引配置信息:

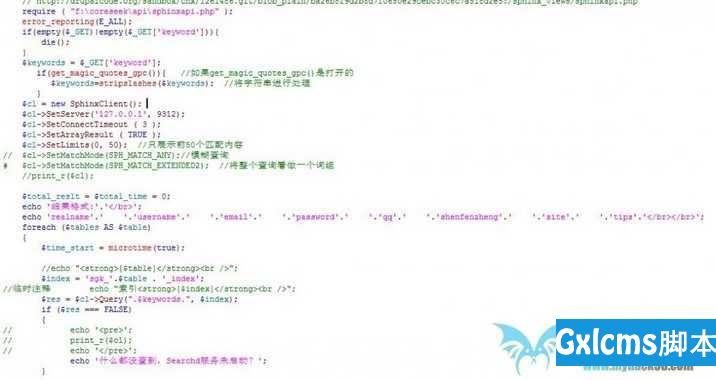
搭建期间遇到的几个问题:
做索引时报 “out of memory” 错误:很多人认为是内存不够大,超过4G的索引就不行了,真是 too young,不好好看手册,看我怎么解决: Coreseek “out of memory” 解决 。
邮箱作为关键词搜索时将@自动作为分隔符断开:也就是说,你搜索 helloyouyou@163.com这个邮箱,它自动给你分割为helloyouyou和163.com进行搜索并给出结果~看我怎么解决:Coreseek搭建的社工库中@特殊字符的搜索 。(其实最终没能解决??)
搭建流程备忘:
创建数据库
CREATE TABLE `shegongku` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`description` text COLLATE utf8_unicode_ci,
`entry` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT ‘主要存放的表‘,
`hits` int(10) DEFAULT ‘0‘,
`date_created` int(10) DEFAULT NULL,
`date_updated` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
CREATE TABLE `shegongku_0001` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`db_id` int(10) DEFAULT NULL,//这里的db_id按照上面shekongku表的id来设置,可以在创建一行后设置默认值。
`line` text,
PRIMARY KEY (`id`),
KEY `db_id` (`db_id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `shegongku_0002` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`db_id` int(10) DEFAULT NULL,
`line` text,
PRIMARY KEY (`id`),
KEY `db_id` (`db_id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
导入数据
load data local infile "c:/test.txt" ignore into table shegongku_0001 character set utf8 fields terminated by ‘|||‘ lines terminated by ‘\n‘ (line);
注意TXT文档必须为UTF8格式
load data local infile "c:/aipai.com/1-20W.txt" ignore into table shegongku_0001 character set utf8 fields terminated by ‘|||‘ lines terminated by ‘\n‘ (line);
进coreseek根目录设置路径set PATH=%CD%\bin;%PATH%
建索引 bin\indexer -c etc\csft_shegongku.conf --all(bin\indexer -c etc\csft_shegongku.conf sgk_twshegongku_0001_index单个索引)
搜索 bin\search -c etc\csft_shegongku.conf -a venus
创建临时服务 bin\searchd -c etc\csft_shegongku.conf --console
创建服务 bin\searchd --install --config f:/coreseek/etc/csft_shegongku.conf --servicename coreseek
PHP调用API,使用PHP搜索
删除服务 bin\searchd --delete --servicename coreseek
每次添加数据库首先在shegongku表添加一行,记录id号,然后创建一个表,db_id按照id号设置默认值。修改search.php第63行。
insert into xunlei(`realname`,`tips`,`shenfenzheng`,`qq`,`site`,`username`,`email`,`password`) select `realname`,`tips`,`shenfenzheng`,`qq`,`site`,`username`,`email`,`password` from xunlei_bak
改进数据库结构和建表方式,直接添加一个新库,然后在search.php和csft_shegongku.conf添加相应库名就OK了。
600多G数据库的sphinx全文检索案例
标签:
本文系统来源:http://www.cnblogs.com/qijiu/p/5702158.html
内容总结
以上是互联网集市为您收集整理的600多G数据库的sphinx全文检索案例全部内容,希望文章能够帮你解决600多G数据库的sphinx全文检索案例所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。