MySQL-Amoeba负载均衡、读写分离功能验证
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了MySQL-Amoeba负载均衡、读写分离功能验证,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1943字,纯文字阅读大概需要3分钟。
内容图文

由于MySQL Cluster自身就实现了数据的自动同步等功能,在此之上架一层Amoeba基本只起到了分担SQL层负载的的作用,所以我们很有必要基于传统的单点MySQL服务之上的 Amoeba都能帮我们做些什么。 环境搭建的过程不再赘述,我们在两个新的虚拟机上启动两个独立的
由于MySQL Cluster自身就实现了数据的自动同步等功能,在此之上架一层Amoeba基本只起到了分担SQL层负载的的作用,所以我们很有必要基于传统的单点MySQL服务之上的 Amoeba都能帮我们做些什么。
环境搭建的过程不再赘述,我们在两个新的虚拟机上启动两个独立的MySQL服务,然后配置在 Amoeba中即可。此时SQL节点的IP分别为:
10.4.44.206 写 10.4.44.207 读 10.4.44.208 读 10.4.44.205 Amoeba节点
这里使用的MySQL版本为,mysql-5.5.29-linux2.6-x86_64。先手动分别在三个节点上创建了相同的数据库(bigdata)和表(data_house)。修改amoeba.xml和dbServers.xml配置,重启amoeba服务。
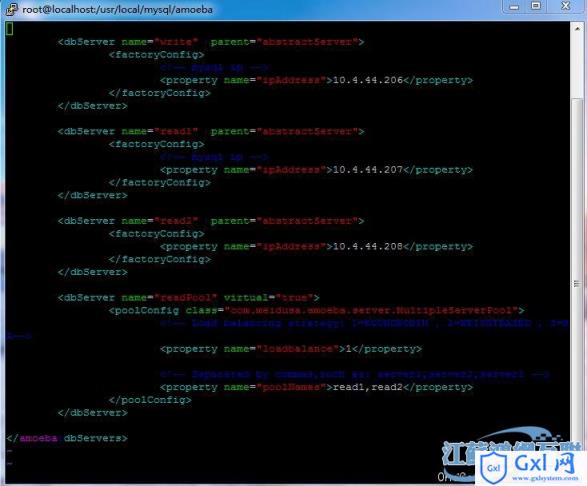
怀着好奇,先测试通过Amoeba节点写入数据和查询数据的情况,看看数据是否是各个节点自动同步的。同样,使用的之前使用的JDBC测试代码。观察写入过程中虚拟机的网络和磁盘指标情况。
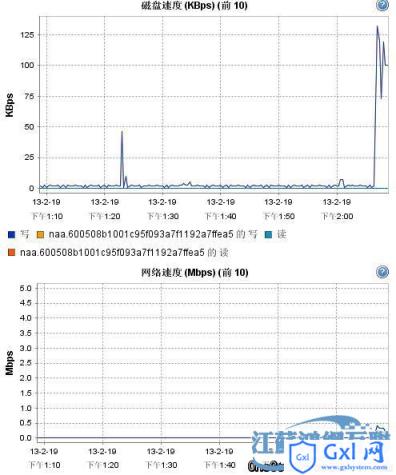
write206节点监控图表
发现果然只有206写节点有网络和磁盘传输请求,207和208节点一片平静。显然数据不是这样同步的,通过Amoeba查询,果然没有数据。在这种情况下,我们应该配置Amoeba的水平切分规则,让数据分别存储在各个节点上。不过这样的话每个节点都只有一部分数据,任何一个节点的故障都会导致数据的不完整,我们来验证看看是不是这样。
修改rule.xml中的配置,
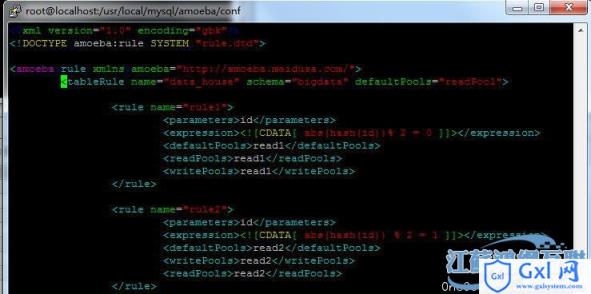
根据ID hash(2)的值水平切分数据。这里每个规则都对应自己的读写节点。这里验证就是Amoeba的路由规则功能。执行数据插入,可以看到数据平均的分配到207和208两个数据节点上,各10000条数据。

此时执行count操作,返回值始终是10000,可见此时无法查询到完整的数据。但是有了这种切分规则,你可以灵活的进行的自己的配置,比如可以进行垂直切分等。所以可见,Amoeba的主要职责是起到了一个路由的作用,把请求分发下去,数据同步不是它关心的。所以Amoeba官网中介绍的读写分离也是基于MySQL主从配置的,这也是我们接下来要进行的工作:)
原文地址:MySQL-Amoeba负载均衡、读写分离功能验证, 感谢原作者分享。
内容总结
以上是互联网集市为您收集整理的MySQL-Amoeba负载均衡、读写分离功能验证全部内容,希望文章能够帮你解决MySQL-Amoeba负载均衡、读写分离功能验证所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。