首页 / MYSQL / 如何删除数据库中的重复记录?
如何删除数据库中的重复记录?
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了如何删除数据库中的重复记录?,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1799字,纯文字阅读大概需要3分钟。
内容图文

一、题外篇 今天很悲催啊,给用户数据做datapatch的时候,每个月的数据多导入了一份,瞬间惊出一身冷汗... 这可是产品环境,要是被老板知道了可就死定了,赶紧去掉重复的记录,同时写下下面的文章以备后用。 二、准备篇 1. 先创建一张学生表student: create
一、题外篇
今天很悲催啊,给用户数据做datapatch的时候,每个月的数据多导入了一份,瞬间惊出一身冷汗... 这可是产品环境,要是被老板知道了可就死定了,赶紧去掉重复的记录,同时写下下面的文章以备后用。
二、准备篇
1. 先创建一张学生表student:
create table student(
id varchar(10) not null,
name varchar(10) not null,
age number not null
);
2. 插入几条数据到表student:
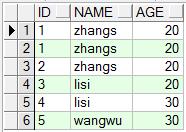
insert into student values('1', 'zhangs', 20);
insert into student values('1', 'zhangs', 20);
insert into student values('2', 'zhangs', 20);
insert into student values('3', 'lisi', 20);
insert into student values('4', 'lisi', 30);
insert into student values('5', 'wangwu', 30);
三、处理篇
1. 使用rowid
① 查询:
select *
from student s1
where rowid != (select max(rowid)
from student s2
where s1.id = s2.id
and s1.name = s2.name
and s1.age = s2.age)
注: rowid是唯一标志记录物理位置的一个id, 括号中是查询出重复数据中rowid最大的一条.
② 删除:
delete from student s1
where rowid != (select max(rowid)
from student s2
where s1.id = s2.id
and s1.name = s2.name
and s1.age = s2.age)
2. 使用 group by 和 having
① 查询:
select id, name, age, count(*) from student group by id, name, age having count(*) > 1;
3. 使用distinct
create table stud_temp as select distinct * from student; -- 创建临时表 stud_temp truncate table student; -- 清空student表 insert into student select * from stud_temp; -- 将临时表数据导入student表 drop table stud_temp; -- 删除临时表
注: distinct只适用于对小表处理, 如果是千万级别数据的表, 请使用rowid, 因为它具有唯一性, 效率更高.
内容总结
以上是互联网集市为您收集整理的如何删除数据库中的重复记录?全部内容,希望文章能够帮你解决如何删除数据库中的重复记录?所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。