内存列式存储vsBufferCache
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了内存列式存储vsBufferCache,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2413字,纯文字阅读大概需要4分钟。
内容图文

Oracle DB 12c的In-Memory选项(DBIM)将表中列的所有行的数据载入内存,为何不能像Buffer Cache那样只把频繁访问的数据块置入内存中呢? 内存列式存储和Buffer Cache的访问模式 原因是两者支持的访问模式不同,对于Buffer Cache,支持的是OLTP应用,访问模式为
Oracle DB 12c的In-Memory选项(DBIM)将表中列的所有行的数据载入内存,为何不能像Buffer Cache那样只把频繁访问的数据块置入内存中呢?
内存列式存储和Buffer Cache的访问模式
原因是两者支持的访问模式不同,对于Buffer Cache,支持的是OLTP应用,访问模式为non-uniform access patterns,也就是说表中的某些行访问比其它行频繁,因此才能通过只缓存10%的数据,就可以涵盖95%的数据访问。可以假设缓存10%的数据就可以得到20倍的性能提升。
而内存列式存储支持的是分析型应用,访问的是少数列,但却需要扫描表中所有行的数据。缓存部分行的数据意义不大,例如如果内存列式存储可以得到100倍性能提升,如果只缓存表中10%的数据只能得到1.1倍的性能提升,而不是100倍。所以在DBIM的设置中,你可以指定全表,表中的部分列,部分分区,表空间,但你无法用where条件指定只缓存列中的部分行。
所以对于分析性的应用,之所以内存列式存储比行式存储(即使是通过alter table tablename cache 全部缓存到内存)快,最重要的原因就是列存储的格式非常适合分析性应用。
列存储格式
以下的图很好的说明了为何列式存储适合分析。
如果采用传统的行式存储来进行分析,例如查询第4列,这时需要逐行访问,需要查询第1到第3列这些无关数据。
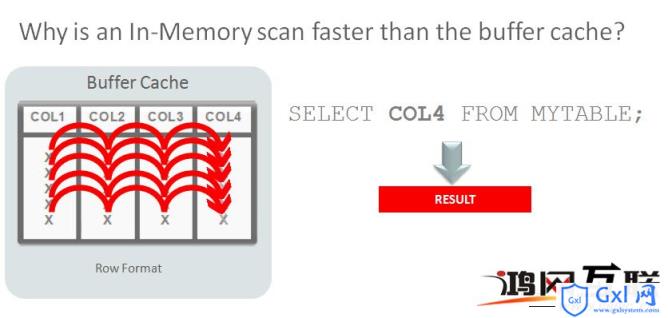
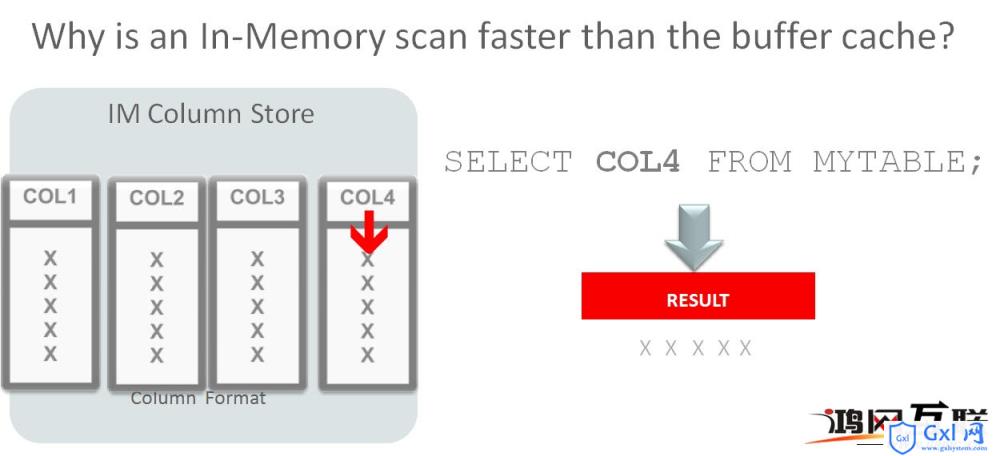
如果是采用列式存储,则只需要访问第4列即可,避免了无效I/O,效率自然提升了。
看一下Oracle在Open World 2013上发布的测试结果:
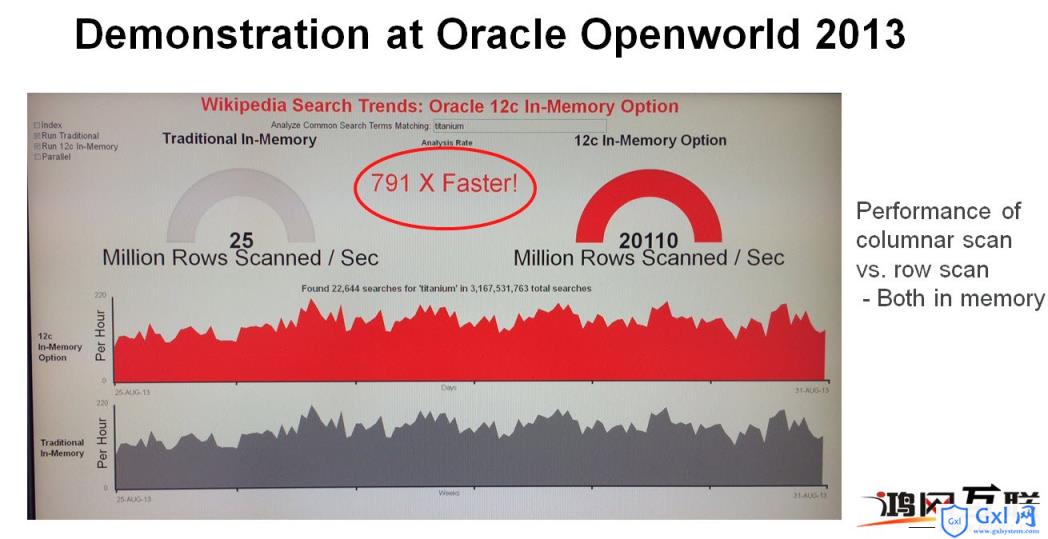
行式和列式都是在内存中,DBIM快了近800倍,单个core每1/6秒处理30亿行数据,难以置信?!
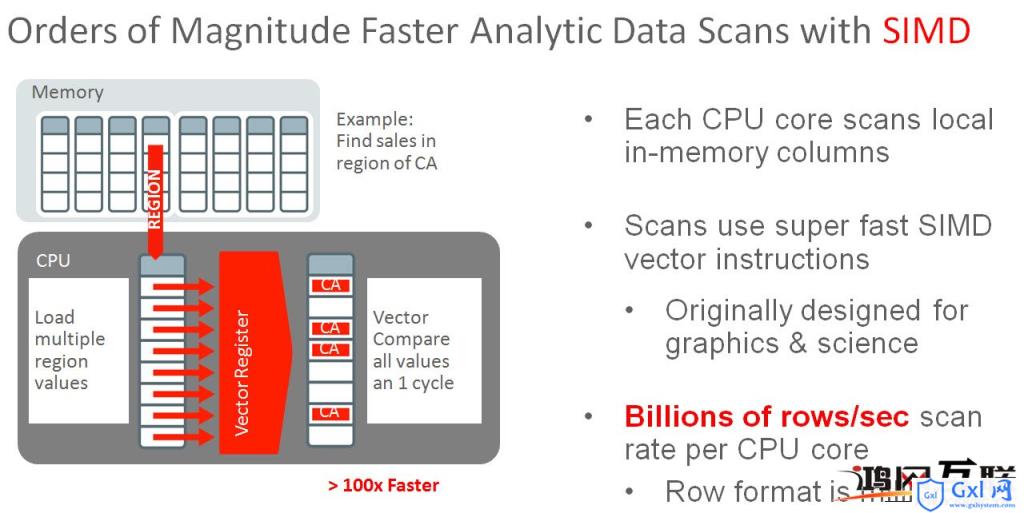
SIMD
这时以前在高性能计算和图像处理中使用的技术,即Single Instruction Multiple Data,其实就是对于数据的批处理,只不过其非常适合列式数据。
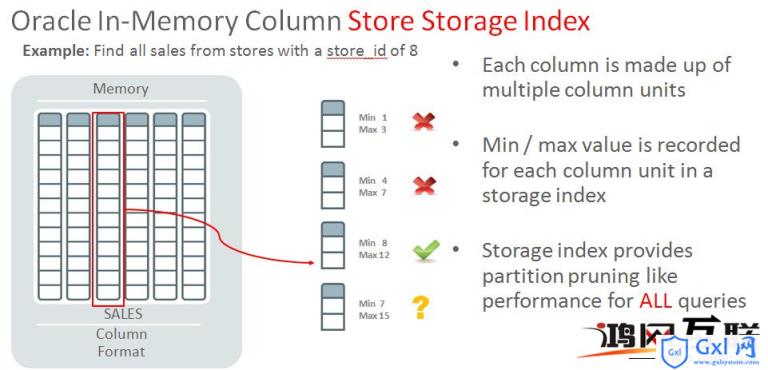
storage index
storage index其实在Exadata中就有了,其实就是将列分区为IMCU,预先计算和实时维护好每一个IMCU中的最大和最小值,查询时匹配where条件,就可以跳过许多无关的IMCU,从而节省I/O和时间。原理上和分区是类似的。
不过数据库重启后需要重新计算。
压缩
列式存储通常都会压缩,因为其中的数据重复值较多,DBIM中压缩是缺省的选项。
压缩不仅可以在内存中缓存更多的数据,而且还可以减少I/O。不过考虑到如果有较多OLTP的访问,这时不要选取压缩比较高的压缩方式,以免压缩和解压时消耗过多的资源。
内存中Join和Aggregation的优化
通过Bloom Filter将Join转换为列扫描可以加快Join速度,在内存中更是如此。
而通过key vector,原理与Bloom Filter类似,也可以在线构建聚集表的结果,具体原理看白皮书。
参考
In-Memory Column Store versus the Buffer Cache
内容总结
以上是互联网集市为您收集整理的内存列式存储vsBufferCache全部内容,希望文章能够帮你解决内存列式存储vsBufferCache所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。