Java 进阶day14XML Dom4j 工厂模式 Base64
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Java 进阶day14XML Dom4j 工厂模式 Base64,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含6036字,纯文字阅读大概需要9分钟。
内容图文

目录
XML
概念
XML的全称为(eXtensible Markup Language),是一种可扩展的标记语言。
XML的作用(保存数据)
不同软件之间进行数据传输。
各种框架的配置文件。
XML文件的后缀名为:xml
文档声明必须是XML第一行
<?xml version="1.0" encoding="UTF-8" ?>
version: 版本号,该属性是必须存在的
encoding: 文件编码,该属性不是必须的(一般取值都是UTF-8)
文档声明告诉别人这个一个XML文件
标签也称为元素
xml标签名字都是小写的
标签必须成对出现
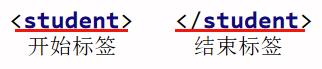
特殊的标签可以不成对,但是必须有结束标记

标签中可以定义属性,属性和标签名空格隔开
属性值必须用引号引起来
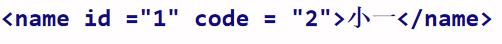
在一个XML文档中,只允许有一个根标签
在XML中注释不能嵌套(Ctrl + / )
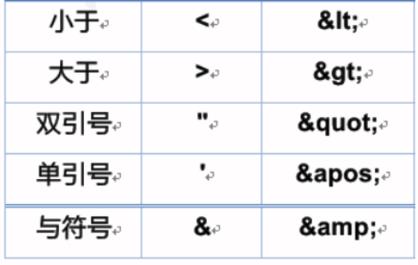

<?xml version="1.0" encoding="utf-8" ?>
<student>
<!-- 这是第一个学生-->
<name>小一</name>
<age>18</age>
<score>100</score>
<address/>
<note>
<![CDATA[
<1>
]]>
2 < 3
</note>
<!-- 这是第二个学生-->
<name>小二</name>
<age>20</age>
<score>99</score>
<address/>
<note>
<![CDATA[
<2>
]]>
</note>
</student>
XML约束
因为XML文件的标签和属性可以随意扩展,通过XML约束来限定XML文件中可使用的标签以及属性。
XML的两种约束
DTD约束,比较简单,功能相对弱
Schema,比较复杂,功能相对强
DTD约束


<!ELEMENT books (book+)>
<!ELEMENT book (name,price,author)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE books SYSTEM "book.dtd">
<books>
<book>
<name>Java</name>
<price>12</price>
<author>Au</author>
</book>
</books>
DTD的不足
不能验证数据类型 (比如,可以在price中写入“呵呵”,这是不正确的)
因为DTD是一个文本文件,本身不能验证是否正确。
Schema约束
Schema约束介绍
Schema约束文件扩展名(XML Schema Definition)
XML模式定义:xsd
Schema 功能更强大,数据类型约束更完善
Schema文件本身也是XML文件,所以也有根元素,根元素的名字叫:schema
一个XML中可以引用多个Schema约束文件
<根标签
? ? xmlns=“命名空间”
? ? xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
? ? xsi:schemaLocation=“命名空间 schema约束文件名”>
? ? < !-- 编写XML元素 -->
</根标签>

<?xml version="1.0" encoding="UTF-8" ?>
<书架
xmlns="http://www.itcast.cn/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/ books.xsd">
<!-- 编写XML元素 -->
<书>
<书名>Java</书名>
<作者>呵呵</作者>
<售价>88</售价>
</书>
</书架>
XML解析
什么是XML的解析
使用程序读取XML中的数据
两种解析方式
Dom4j解析
XPath解析
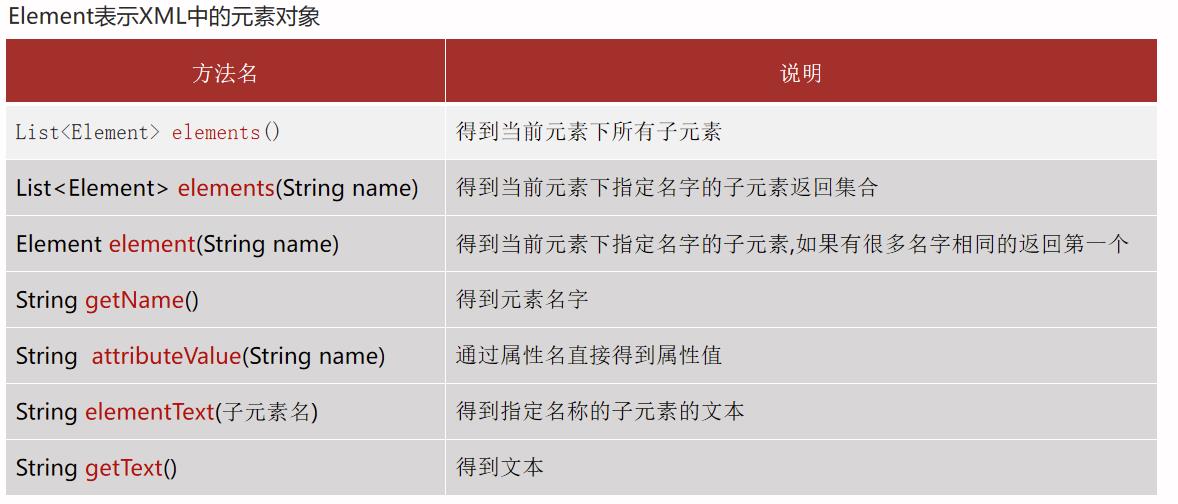
Dom4j(Dom for java)


public class Contact {
private String id;
private boolean vip;
private String name;
private String gender;
private String email;
\\默认无参、有参、get\set
}
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1" vip="true">
<name>潘金莲</name>
<gender>女</gender>
<email>panpan@itcast.cn</email>
</contact>
<contact id="2">
<name>武松</name>
<gender id="1000">男</gender>
<email>wusong@itcast.cn</email>
</contact>
<contact id="3">
<name>武大狼</name>
<gender>男</gender>
<email>wuda@itcast.cn</email>
</contact>
</contactList>
获取XML文件中的元素
public class Test {
public static void main(String[] args) throws DocumentException {
//1、创建解析器
SAXReader reader = new SAXReader();
//2、解析XML
Document doc = reader.read("day14\\src\\Contact.xml");
//3、获得根标签
Element rootElement = doc.getRootElement();
//4、创建集合保存元素
ArrayList<Contact> list = new ArrayList<>();
//5、获得所有子标签
List<Element> elements = rootElement.elements();
for (Element element : elements) {
//6、获取数据
String id = element.attributeValue("id");
String vips = element.attributeValue("vip");
boolean vip = Boolean.parseBoolean(vips);
String name = element.elementText("name");
String gender = element.elementText("gender");
String email = element.elementText("email");
// 7、创建对象
Contact c = new Contact(id, vip, name, gender, email);
// 8、保存数据
list.add(c);
}
// 9、打印数据
for (Contact c : list) {
System.out.println(c);
}
}
}
XPath
需要导入两个包(XPath是对dom4j的加强)
导入jar包 ( dom4j 和 jaxen-1.1.2.jar )
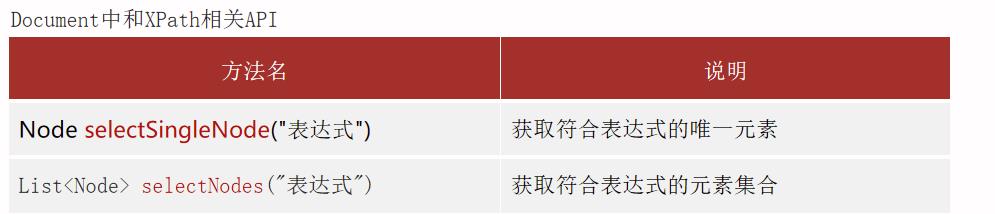
绝对路径:/根元素/子元素/孙元素
相对路径:./子元素/孙元素 ( 注意:前面有个 . )
全文搜索
 属性查找
属性查找

public class Test2 {
private static Document document;
static{
try {
SAXReader reader = new SAXReader();
document = reader.read("day14\\src\\Contact.xml");
} catch (DocumentException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
test1();
System.out.println("----------------------");
test2();
test3();
test4();
}
//绝对路径
public static void test1(){
List<Node> nodes = document.selectNodes("contactList/contact/name");
for (Node node : nodes) {
System.out.println( node.getName() + " : " + node.getText());
}
}
//相对路径
public static void test2(){
Element rootElement = document.getRootElement();
List<Node> nodes = rootElement.selectNodes("./contact/email");
for (Node node : nodes) {
System.out.println(node.getName() + " : " + node.getText());
}
}
//全文搜索
public static void test3(){
List<Node> nodes = document.selectNodes("//contact/name");
for (Node node : nodes) {
System.out.println(node.getName());
}
}
//属性查找
public static void test4(){
List<Node> nodes = document.selectNodes("//contact[@id = '1']");
for (Node node : nodes) {
System.out.println(node.getName());
}
}
}
注意:
1、xml文件一般放在src下
2、和所有写代码的路径不能有中文或空格
工厂模式
简单工厂模式用于创建对象的。通过专门定义一个类来负责创建其他类的实例。
工厂模式作用
解决类与类之间的耦合问题,屏蔽了外界对具体类的依赖,让类的创建更加简单。
interface Car {
void run();
}
class Bmw implements Car{
@Override
public void run() {
System.out.println("Bmw");
}
}
class Benz implements Car{
@Override
public void run() {
System.out.println("Benz");
}
}
class Company {
public static Car Creatcar(String car){
if (car.equals("b1")){
return new Benz();
}if( car.equals("b2")){
return new Bmw();
}else {
return null;
}
}
}
public class Test {
public static void main(String[] args) {
Car b1 = Company.Creatcar("b1");
b1.run();
Car b2 = Company.Creatcar("b2");
b2.run();
}
}
Base64
在Java 8中,Base64编码已经成为Java类库的标准。Java 8 内置了 Base64 编码的编码器和解码器。
编码: 文字变成特殊的64字符
解码: 特殊的64字符变成文字
基本的Base64: 输出被映射到一组字符A-Za-z0-9+/,编码不添加任何行标,输出的解码仅支持A-Za-z0-9+/。
URL的Base64: 输出映射到一组字符A-Za-z0-9-_,输出是URL和文件。
MIME的Base64: 输出映射到MIME友好格式。输出每行不超过76字符。(超过会换行)

内容总结
以上是互联网集市为您收集整理的Java 进阶day14XML Dom4j 工厂模式 Base64全部内容,希望文章能够帮你解决Java 进阶day14XML Dom4j 工厂模式 Base64所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。