首页 / 算法 / LeetCode-算法
LeetCode-算法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了LeetCode-算法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含24529字,纯文字阅读大概需要36分钟。
内容图文

文章目录
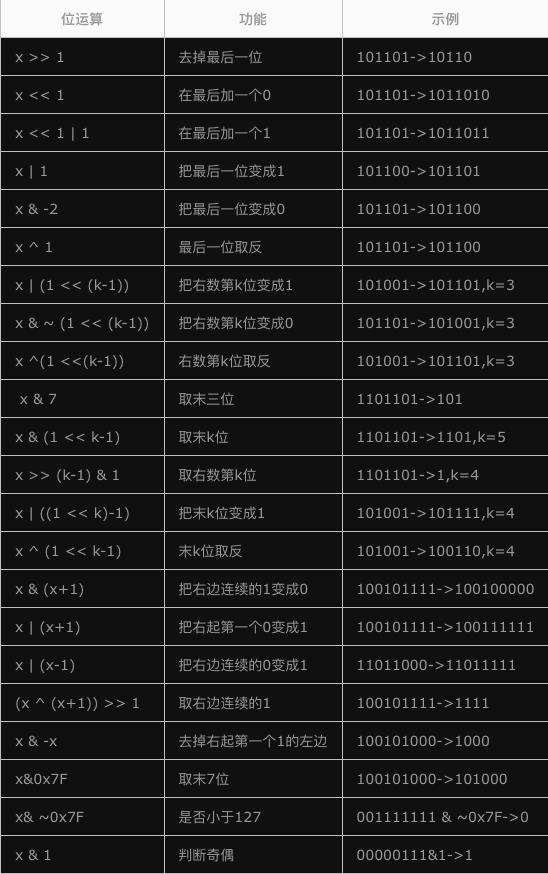
4.4位运算
常见的位运算
更多参考:状态压缩
布赖恩·克尼根算法/popcount/汉明权重
目的:不需要移位即可知道所有位中1的个数
算法:当我们在 number 和 number-1 上做 AND 位运算时,原数字 number 的最右边等于 1 的比特会被移除
应用:n&(n-1) => 相当于将n的最右边的1变成0(布赖恩·克尼根算法)
题目:191. 位1的个数
338. 比特位计数 => 结合动态规划
201. 数字范围按位与
lowbit算法
lowbit(x)是x的二进制表达式中最低位的1所对应的值。
比如,6的二进制是110,所以lowbit(6)=2。
int lowbit(int x){
return x & (-x); //x+(-x)==0; 因此x与-x按位与,最低位必定为1,其他位为0
}
//或者
int lowbit(int x){
return x-(x & (x-1)); // x&(x-1)相当于将x最低位的1变成0,所以...
}
位运算进行整数加法
int add(int x, int y){
int answer; int carry;
while(y){
answer=x^y; // x^y的结果是不考虑进位的和
carry=(x&y) << 1; // (x&y)产生进位,(x&y)<<1是进位的值(进位补偿)
x=answer; y=carry; //由上面注释:x+y=x^y + (x&y)<<1 => 由于不使用加法,此处通过循环继续迭代下去完成x^y 和 (x&y)<<1的求和
}
return x;
}
格雷码
-
格雷码定义
格雷码 -
格雷码与二进制码的转换
方法很多,推荐使用异或的方法
二进制码=> 格雷码

即将二进制码的第i位和第i+1位的异或结果作为格雷码的第i位(左边是高位,右边是低位)// 二进制码转换为格雷码 public List<Integer> grayCode(int n) { int max=1<<n; List<Integer> res=new ArrayList<Integer>(); for(int i=0;i<max;i++){ res.add(i^(i>>1)); // i右移保证移动之前每一位的前一位 和 该位 对齐 } return res; }
格雷码 => 二进制码

- 题目
89. 格雷编码
4.5排序
写在前面:排序的基础/基准题目:912. 排序数组
选择排序(简单选择、堆)
- 简单选择排序
在数组中,每次遍历剩余元素,选择剩余元素中的最小值
时间O(N^2),空间O(1)void SelectSort(ElemType A[],int n){ for(i=0;i<n-1;i++){ min_idx=i; for(j=i+1;j<n;j++) if(A[j]<A[min_idx]) min_idx=j; swap(A[i],A[min_idx]); } }
不稳定,比如{2,2,1} => {1,2,2} - 堆排序
详见[树]部分的—堆
插入排序(直接插入、折半、希尔)
插入排序的思路:每次将一个待排序元素按照大小插入前面已经排序的序列中…
- 直接插入排序
void InsertSort(int[] A){ for(i=2;i<=n;i++){ if(A[i]<A[i-1]){ A[0]=A[i]; //A[0]为哨兵,不存放元素 => 不用判断是否越界 // 感觉哨兵用处也不大 for(j=i-1;A[0]<A[j];j--) A[j+1]=A[j]; A[j+1]=A[0]; } } }
交换排序(冒泡排序、快速排序)
- 快速排序
注:int partition(int[] nums,int low,int high){ int pivot=nums[low]; while(low<high){ while(low<high && nums[high]>=pivot) //右边找到第一个小于pivot的值 high--; nums[low]=nums[high]; while(low<high && nums[low]<=pivot) //左边找到第一个大于pivot的值 low++; nums[high]=nums[low]; } //最终必定是low==high nums[low]=pivot; return low; } void qsort(int[] nums,int low,int high){ if(low>=high) return; int mid=partition(nums,low,high); qsort(nums,low,mid-1); qsort(nums,mid+1,high); }
1.快速排序其实利用了分治法的思想;
2.快速排序是不稳定的排序,比如{3,2,2} => {2,2,3};
3.partition中,low<high的条件不能取等,取等需要作为退出条件:因为按照上面的逻辑,low、high中至少有一个是空位,当low==high时,说明最后一个位置恰好是空位,应该用于放置pivot;而不是继续移动,因为low左边和high右边都已经访问过了;
4.partition中,nums[low]<=pivot,nums[high]>=pivot至少有一个要取等=>目的是避免low<high但是nums[low]==pivot ==nums[high]时导致死循环(可在912题中测试);此外,如果一个取等,则与pivot相等的值仅放在pivot的一边,如果两个取等,则与pivot相等的值在pivot两侧都有
5.非递归实现(栈):由于递归中是传递的关键参数就是左右指针,我们可以直接用栈来存储,参考:快速排序(三种算法实现和非递归实现)
6.空间复杂度:取决于栈的深度,最坏O(n),平均O(logn)
7.时间复杂度:最坏(有序或者逆序)O(n^2),平均O(nlogn) => 最好翻一下书,用递推式计算Tavg
归并排序(二路归并)
- 自顶向下
采用递归方式(可转换为用栈); 典型的分治法
代码参考:二路归并排序// 自底向上使用循环; 自顶向下使用递归 => 此用自顶向下,更简单 // merge,将a[low,...mid]与 a[mid+1...high]两个有序子表合并,需要使用额外空间暂存 void merge(int[] nums, int low, int mid, int high){ int[] tmp=new int[high-low+1]; int idx=0; int i=low; int j=mid+1; while(i<=mid && j<=high){ if(nums[i]<nums[j]) tmp[idx++]=nums[i++]; else tmp[idx++]=nums[j++]; } while(i<=mid) tmp[idx++]=nums[i++]; while(j<=high) tmp[idx++]=nums[j++]; // 暂存在tmp的归并后的数据写入原数组 for(int k=0;k<idx;k++) nums[low+k]=tmp[k]; } void mergeSort(int[] nums,int low,int high){ if(low<high){ int mid=low+(high-low)/2; mergeSort(nums,low,mid); mergeSort(nums,mid+1,high); merge(nums,low,mid,high); } }
时间复杂度:每一轮归并所有数字都会被遍历到O(n),共log2n轮 => O(nlog2n)
空间复杂度:需要一个数组来暂存中间元素,O(n); 递归栈的空间复杂度O(log2n)
可以是稳定的排序
- 自底向上
采用迭代方式
代码参考归并排序-自底向上的二路归并
时间复杂度:每轮归并所有元素都被遍历到O(n),共log2n轮 => O(nlog2n)
空间复杂度:需要一个数组暂存O(n),但是不需要栈空间!! - 空间复杂度O(1)的二路归并
当要排序的是链表时,只需要修改指针,不用暂存元素;此时若使用自底向上的二路归并,也不需使用栈,故空间复杂度O(1) => 148. 排序链表 - k路归并排序
使用小根堆/优先队列辅助排序更方便 =>
几种排序算法的对比(待完成)
| 排序方式 | 最好 | 最坏 | 平均 | 空间 | 稳定性 | 复杂性 |
|---|---|---|---|---|---|---|
| 直接插入排序 | 单元格 | 单元格 | ||||
| 折半插入排序 | 单元格 | 单元格 | ||||
| 希尔排序 | ||||||
| 冒泡排序 | ||||||
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | 不稳定 | |
| 简单选择排序 | O(n^2) | O(N^2) | O(n^2) | O(1) | 不稳定 | |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | |
| 归并排序 | ||||||
| 基数排序 |
分类如下=>
插入排序:直接插入、折半插入排序、希尔排序
交换排序:冒泡排序、快速排序
选择排序:简单选择排序、堆排序
归并排序:…
基数排序:…(比较少见)
4.6 查找
二分查找基本思路框架
-
二分查找的基本框架
int binarySearch(int[] nums, int target) { int left = 0; int right = nums.length - 1; // 注意 while(left <= right) { int mid = left + (right - left) / 2; if(nums[mid] == target) return mid; else if (nums[mid] < target) left = mid + 1; // 注意 else if (nums[mid] > target) right = mid - 1; // 注意 } return -1; }1.左右指针都是对应的闭区间
2.退出循环的条件要取等,否则idx== left==right处的元素,且该元素恰好就是目标元素
3.注意mid的计算方法,(right-left)/2是为了防止溢出 -
搜索左边界的二分法
对于target存在重复的数组,基本的二分法找到的不一定是最左边的下标,比如[1,2,2,2,3,4]。需要更新如下:int left_bound(int[] nums, int target) { int left = 0, right = nums.length - 1; // 搜索区间为 [left, right] while (left <= right) { int mid = left + (right - left) / 2; if (nums[mid] < target) { // 搜索区间变为 [mid+1, right] left = mid + 1; } else if (nums[mid] > target) { // 搜索区间变为 [left, mid-1] right = mid - 1; } else if (nums[mid] == target) { // 收缩右侧边界 right = mid - 1; } } // 检查出界情况 if (left >= nums.length || nums[left] != target) return -1; return left; }1.搜索的仍然是闭区间,且循环条件依然是 <=
2.关键是nums[mid] == target时,需要收缩右指针,从而找到最左边界
3.由于 while 的退出条件是 left == right + 1,所以当 target 比 nums 中所有元素都大时,会存在上边界溢出的情况,所以需要检查边界left >= nums.length
3.若target比所有元素都小时,left始终为0,nums[left] != target的检查可剔除这一情况(当然同时也剔除了target处于中间值但是不在数组的情况)
4.对于正常返回的结果left,可看做数组中有left个数小于target,这一思路可用于解决部分题目
题目:34. 在排序数组中查找元素的第一个和最后一个位置 -
搜索右边界的二分法
int right_bound(int[] nums, int target) { int left = 0, right = nums.length - 1; while (left <= right) { int mid = left + (right - left) / 2; if (nums[mid] < target) { left = mid + 1; } else if (nums[mid] > target) { right = mid - 1; } else if (nums[mid] == target) { // 这里改成收缩左侧边界即可 left = mid + 1; } } // 这里改为检查 right 越界的情况,见下图 if (right < 0 || nums[right] != target) return -1; return right; }…略
二分查找之旋转排序数组
- 思路
二分查找适用于有序的数组 => 不仅是整体有序,分段有序的数组也可以使用二分查找
1. 对于33. 搜索旋转排序数组 每次二分后,必定至少一侧完全有序,判断目标是否在完全有序的部分,是则对该部分继续二分,否则二分另一半 - 题目
33. 搜索旋转排序数组
二分查找练习题目
- 题目
69. x 的平方根
4.x 贪心算法
贪心算法求解区间调度问题
- 问题描述
给你很多形如 [start, end] 的闭区间,请你设计一个算法,算出这些区间中最多有几个互不相交的区间
求解方法:贪心算法之区间调度问题 - 题目
435. 无重叠区间
贪心法经典题目
4.x 动态规划
概述
-
自底向上与自顶向下
都需要一个动态规划数组,用于记录每个子结果,从而减少重复计算
自顶向下使用向下递归的方法,这个动态规划数组常称为备忘录
自底向上使用向上迭代的方法,相对而言效率更高 -
动态规划的空间优化/状态压缩
观察动态规划数组元素计算特点,二维数组或许可以压缩为一维;一维数组或许可以压缩为不使用数组 -
动态规划的核心
动态规划的核心是状态定义和状态转移,递归、缓存(备忘录)都只是手段; 更多参考:什么是动态规划(Dynamic Programming)?动态规划的意义是什么? -
动态规划的性质
最优子结构:问题的最优解所包含的子问题的解也是最优的 => 必须满足
无后效性:某个状态以后的过程不会影响以前的状态,只与当前状态有关 => 必须满足
重叠子问题:如Fibonacci问题,不是必须的,但是若不满足重叠子问题,则动态规划并无优势 -
与其他算法的比较
分治法:分治法中各子问题是独立的,动态规划多用于重叠子问题
状态机
-
状态机
DP的本质也就是 状态定义, 动作选择(状态转移),使用穷举的方法遍历所有状态 => 个人认为,动态规划其实就是状态机;关键就是选取合适的状态,所谓状态就是DP table中下标为(i,j,k)的情况下对应的dp[i,j,k]值及其含义,当然,弄清楚坐标轴的含义也是极其重要,从而可以遍历所有情况来更新状态(状态转移)
一个方法团灭 LeetCode 股票买卖问题(链接中的题目或许能帮助理解,文中对状态的解释与个人理解有出入!) -
状态机再理解
上面关于动态规划和状态机的描述个人认为基本没有问题,但是依然不够清晰,对刷题而言帮助不大;
具体到题目中,有一类显然的问题,那就是我们可以找到一个“状态组”,给定数组中的每一个数据都可能处于“状态组”中的某个状态,而且这个状态组中的状态总数很少(通常只有2-3) => 为了方便理解,此时我们仅将这个2-3个状态视为状态机中的状态(区别于上文,这里我们理解时不将遍历数组的下标看成状态的一部分)
这种情况下仅将遍历数组过程中那2-3个“状态”间的转换看做状态机,这2-3个状态也占dp数组的一维,但是不需要通过循环访问这个维度,循环只需要用于遍历数组下标即可(比如int[][] dp[n][2],只需一重循环就更新了第二个维度的信息)
说得比较绕,看题即可理解:
LCP 19. 秋叶收藏集
一个方法团灭 LeetCode 股票买卖问题
原来状态机也可以用来刷 LeetCode?
动态规划求解背包问题
-
0/1背包问题
经典动态规划:0-1 背包问题
通常dp数组为二维:i代表前i个物品,j代表背包剩余容量
=>dp[i]][j]即当背包剩余j的容量时,考虑前i个物品,能装入背包的最大价值
474. 一和零 => 比较灵活,可转换为01背包 -
子集背包
416. 分割等和子集=> 虽然不是求能装下的最大价值,但是依然几乎一样;
子集背包本质上就是01背包 -
完全背包问题
经典动态规划:完全背包问题
框架依然是dp数组为二维:i代表前i物品,j代表背包剩余容量,但是在状态转移方程上需要具体问题具体分析 -
背包问题相关题目
494. 目标和 => 显然可以回溯法;但是可以转换为背包问题,进而使用动态规划求解(=> 动态规划和回溯算法到底谁是谁爹?仔细看,很难想到)
动态规划求解最长公共子序列问题(LCS)
- 概述
对于两个字符串的动态规划问题, 通常的套路都是假设二维的动态规划数组,dp[i][j]表示s1的前i个字符与s2的前j个字符的…
(最长公共子序列通常不要求子序列中的元素连续!!!) - 题目
1143. 最长公共子序列
动态规划求解最长递增子序列问题(LIS)
- 概述
动态规划的难点始终在于动态规划数组的定义;
最长子序列问题上,通常只需要一维的dp数组,dp[i]代表以nums[i]结尾的最长子序列长度,dp[i]=max(dp[i],dp[j]+1), j=0,1,…i-1;
错误定义1:dp[i]表示nums[0,…i]的最长子序列长度=> 没有体现最优子结构,因为nums[i]这个值不一定包含在最长子序列长度中,求dp[i+1]时无法利用dp[i]
错误的定义2:dp[i,j]表示nums[i,…j]的最长子序列长度 => 理由同上; 而且就算是增加空间存储nums[i…j]对应最长子序列的最大值和最小值,也依然无法保证nums[i-1,…j+1]对应的最长子序列一定包含了nums[i,…j]对应的最长子序列!! <=>这种定义方式与回文子串问题很相似,但是需要注意两类题目并不相同!!
300. 最长上升子序列
=> 注意可进一步使用二分查找,提高效率(不要求必会,动态规划设计:最长递增子序列
334. 递增的三元子序列
354. 俄罗斯套娃信封问题
动态规划求解最大连续子序和问题
- 概述
类似于最长递增子序列问题,依然令dp[i]表示以nums[i]结尾的最大子序列和…
53. 最大子序和 - 类似题目
152. 乘积最大子数组
动态规划求解回文子串相关问题
- 概述
参考:[回文子串部分] - 相关题目
131. 分割回文串
132. 分割回文串 II
树形动态规划
-
概述
就是动态规划,只是遍历的是一颗层次分明的树。在树上就可以方便的使用DFS进行遍历(或者说是记忆化搜索/递归的动态规划/备忘录方法)。
树状动态规划的特点:没有环,dfs是不会重复,而且具有明显而又严格的层数关系。利用这一特性,我们可以很清晰地根据题目写出一个在树(形结构)上的记忆化搜索的程序 -
求解过程
1. 判断是否是一道树规题:即判断数据结构是否是一棵树,然后是否符合动态规划的要求。如果是,那么执行以下步骤
2. 建树:通过数据量和题目要求,选择合适的树的存储方式。如果节点数小于5000,那么我们可以用邻接矩阵存储,如果更大可以用邻接表来存储
3. 写出树规方程:通过观察孩子和父亲之间的关系建立方程。我们通常认为,树规的写法有两种:
a.根到叶子: 不过这种动态规划在实际的问题中运用的不多。本文只有最后一题提到。
b.叶子到根: 既根的子节点传递有用的信息给根,完后根得出最优解的过程。这类的习题比较的多。
更多讲解及题目参考:不撞南墙不回头——树规总结 -
题目
834. 树中距离之和 => 其实自己也想到了用floyd解法,不过效果过低,不推荐
1024. 视频拼接
状压dp(未完成)
- 概述
参考这个通俗的讲解:状压DP详解(位运算) - 题目
698. 划分为k个相等的子集
动态规划求解编辑距离
-
概述
两个字符串word1和word2之间的编辑距离即:只通过增加、删除、替换三种操作,将word1变成word2的最少操作次数 -
动态规划数组
动态规划 => d p [ i ] [ j ] dp[i][j] dp[i][j]表示将 w o r d 1 [ 0 , . . . i ] word1[0,...i] word1[0,...i]变成 w o r d 2 [ 0 , . . . j ] word2[0,...j] word2[0,...j]的最少编辑次数(字符串相关问题的动态规划数组都是类似的假设) -
状态转移
考虑 w o r d 2 [ 0 , . . . j ] word2[0,...j] word2[0,...j]的最后一个字符 w o r d 2 [ j ] word2[j] word2[j]是如何得到的,有以下三种情况:
1.在末尾添加的 w o r d 2 [ j ] word2[j] word2[j]:先将 w o r d 1 [ 0 , . . . i ] word1[0,...i] word1[0,...i]转变成了 w o r d 2 [ 0 , . . . j ? 1 ] word2[0,...j-1] word2[0,...j?1],末尾再添加一个字符 => d p [ i ] [ j ? 1 ] + 1 dp[i][j-1]+1 dp[i][j?1]+1
2删除一个字符后保留的 w o r d 2 [ j ] word2[j] word2[j]: w o r d 1 [ 0 , . . . . i ] word1[0,....i] word1[0,....i]转变成了 w o r d 2 [ 0 , . . . j , j + 1 ] word2[0,...j,j+1] word2[0,...j,j+1],然后删掉末尾的字符 => d p [ i ? 1 ] [ j ] + 1 dp[i-1][j]+1 dp[i?1][j]+1
3.直接将末尾字符替换成 w o r d 2 [ j ] word2[j] word2[j]:先将 w o r d 1 [ 0 , . . . i ? 1 ] word1[0,...i-1] word1[0,...i?1]转换成了长度为 j j j的字符串(0,…j-1完成了正确转换,最后一个字符没有进行任何改动),于是只需将最后一个字符替换成正确字符即可(当然如果最后一个字符本就是正确的,便不需替换) => d p [ i ? 1 ] [ j ? 1 ] + 1 / 0 dp[i-1][j-1]+1/0 dp[i?1][j?1]+1/0
题外话:状态转移很多时候有不同的解释,也很费脑力,有一种合理的思路即可
更多思路也可参考:经典动态规划:编辑距离 -
题目
72. 编辑距离
动态规划求解博弈问题
-
思路
动态规划之博弈问题
博弈问题的前提一般都是在两个聪明人之间进行,编程描述这种游戏的一般方法是二维 dp 数组,数组中通过元组分别表示两人的最优决策。
之所以这样设计,是因为先手在做出选择之后,就成了后手,后手在对方做完选择后,就变成了先手。这种角色转换使得我们可以重用之前的结果,典型的动态规划标志
以为877为例://博弈问题一般化的动态规划模板:dp[N][N][2] // => 其中a.dp[i][j][0]表示先手在arr[i,...j]的最大收益 // b.dp[i][j][1]表示后手在arr[i,...j]的最大收益, // 当然,后手的选择取决于先手,后手的结果其实来自arr[i+1,...j]或者arr[i,...j-1]; // 不过,直接说它来自arr[i,...j]也没有错,且更方便 /* 可优化空间 */ public boolean stoneGame(int[] piles) { // return true; // 官答思路,可直接分析出true int n=piles.length; int[][] dpFir=new int[n][n]; // 先手 int[][] dpSec=new int[n][n]; // 后手 for(int i=0;i<n;i++){ dpFir[i][i]=piles[i]; dpSec[i][i]=0; } //往右上角遍历 for(int i=n-2;i>=0;i--){ for(int j=i+1;j<n;j++){ //先手选左侧能获得的收益=左侧节点值+它在下一轮选取中的最大收益 //而在下一轮选取中,它其实是后手,故取dpSec[i+1][j] int left=piles[i]+dpSec[i+1][j]; int right=piles[j]+dpSec[i][j-1]; if(left > right){ dpFir[i][j]=left; dpSec[i][j]=dpFir[i+1][j]; } else{ dpFir[i][j]=right; dpSec[i][j]=dpFir[i][j-1]; } } } return dpFir[0][n-1]>dpSec[0][n-1]; }
动态规划之正则表达式(多次没做对,待完成)
动态规划求解最大矩形
- 问题及思路
问题:求解二维数组中,由"1"组成的最大矩形
思路:对于每个点mat[i][j] 将其往上、往左、往右扩展,直至不能构成矩形。则每个点mat[i][j] 对应一个矩形,遍历过程中更新最大矩形即可。而往上、往左、往右扩展获取height、left、right实际上可以用动态规划来计算 - 题目
85. 最大矩形
区间DP
-
概念
区间dp,顾名思义就是在一段区间上进行动态规划。对于每段区间,他们的最优值都是由几段更小区间的最优值得到,是分治思想的一种应用,将一个区间问题不断划分为更小的区间直至一个元素组成的区间,枚举他们的组合 ,求合并后的最优值
区间型 dp 一般用 dp[i][j]表示 ,i 代表左端点,j 代表右端点 -
套路
//初始化DP数组 for(int i=1;i<=n;i++){ dp[i][i]=初始值 } for(int len=2;len<=n;len++){ //区间长度 for(int i=1;i<=n;i++){ //枚举起点 int j=i+len-1; //区间终点 if(j>n) break; //越界结束 for(int k=i;k<j;k++){ //枚举分割点,构造状态转移方程 dp[i][j]=max(dp[i][j],dp[i][k]+dp[k+1][j]+w[i][j]); } } }典型例题:87. 扰乱字符串
动态规划求解整数拆分
-
概述
将整数拆分成至少两个正整数的和,在此基础上可以延伸出一些题目
=> 比如求拆分后整数积的最大值?比如求拆分方案的个数? -
总体思路
最基本的想法是:对于整数n,假设第一次将其拆分成k和n-k,k之后不再拆分 => 讨论之后n-k不拆分的情况、n-k继续拆分的情况…
上述是基本思路,针对不同的题目,后续dp数组的设定不同 -
题目
343. 整数拆分
李春葆算法书,8.2
动态规划求解股票买卖问题
-
思路
即上文提到的状态机 -
题目
121. 买卖股票的最佳时机
122. 买卖股票的最佳时机 II
123. 买卖股票的最佳时机 III
188. 买卖股票的最佳时机 IV
动态规划求解字符串(子串)匹配
通用思路:详解「字符串匹配」的通用思路和技巧 …
115. 不同的子序列
动态规划经典题目
- 题目
845. 数组中的最长山脉
85. 最大矩形
139. 单词拆分
140. 单词拆分 II
338. 比特位计数 => x&(x-1)的思路转换为动态规划!
115. 不同的子序列 => 类似于字符串匹配、背包问题…
4.x记忆化搜索
=> 记忆化搜索与动态规划比较类似,都是存储了中间计算结果,只是记忆化很多时候使用了递归/深度优先搜索!!!
动态规划要求按照拓扑顺序解决子问题。对于很多问题,拓扑顺序与自然秩序一致。而对于那些并非如此的问题,需要首先执行拓扑排序。因此,对于复杂拓扑问题(如329),使用记忆化搜索通常是更容易更好的选择。
注:更确切地说,上面的动态规划指自底向上的动态规划(迭代),记忆化搜索指自顶向下的动态规划(备忘录方法,递归) => 递归虽然效率低,但是能解决拓扑顺序的问题!
4.x 回溯法
回溯法基础
-
核心代码
result = [] def backtrack(路径, 选择列表): if 满足结束条件: result.add(路径) return for 选择 in 选择列表: 做选择 backtrack(路径, 选择列表) 撤销选择组合树和排列树其实都是这个思路 => 只是
组合树每次只有两个选择,要么选、要么不选,有时候撤销的动作不突出!
子集树和排列树的递归回溯框架
子集树参考:子集树的递归回溯框架=>子集元素个数为2^n
排列树参考:排列树的递归回溯框架,注意对于排列树而言,交换之后需要再交换回来(排列树的另一种复杂度稍高的写法,不用交换:回溯算法解题套路框架) => 排列元素个数为n!
排列树中交换的目的:对于swap(x[i],x[j]);意思是第[0…i-1]个位置的数字已经确定,第i个位置尝试放置x[j] => 为了得到剩余部分的所有结果,所以需要交换回来,第i个位置继续尝试放置其余数字!
注:回溯法中并不是只有组合树和排列树,还有很多其他形式,不过核心都是选择—撤销选择
回溯法典型例题
- 题目
51. N 皇后 尝试用回溯法的思路来解 => 由于不同行不同列,所以对行和列的选择是同时进行的,可以按照对行(列)的选择进行回溯…每选择一行/列对应递归树的一层
46. 全排列
47. 全排列 II => 去重
78. 子集
90. 子集 II => 同上使用hash去重
131. 分割回文串 => 难在不易将其建模为回溯问题
4.x 滑动窗口/双指针
滑动窗口
/* 滑动窗口算法框架 */
void slidingWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// c 是将移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 进行窗口内数据的一系列更新
...
/*** debug 输出的位置 ***/
printf("window: [%d, %d)\n", left, right);
/********************/
// 判断左侧窗口是否要收缩
while (window needs shrink) {
// d 是将移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 进行窗口内数据的一系列更新
...
}
}
}
每一次窗口右移都需要判断是否需要收缩(通过循环判断,一次收缩到位)!!
题目:
76. 最小覆盖子串
3. 无重复字符的最长子串
567. 字符串的排列
424. 替换后的最长重复字符
双指针之—快慢指针
=> 主要用在链表问题中
1.判断链表中是否有环:141. 环形链表
2.判断含环链表的起始节点:142. 环形链表 II => 理解原理
3.寻找链表的中点(快指针一次前进两步,慢指针一次前进一步) => 可用于链表的归并排序
4.寻找链表的倒数第k个数 => 让快指针先走 k 步,然后快慢指针开始同速前进
相关题目:26. 删除排序数组中的重复项
83. 删除排序链表中的重复元素
61. 旋转链表
双指针之—左右指针
=> 主要用在数组问题中
1.二分查找其实也是双指针问题
2.twoSum问题(排序+双指针)
3.反转数组
4.滑动窗口问题其实也是双指针,只是相对更复杂一些
双指针/滑窗题目
nSum问题:基本思路就是排序+双指针
讲解:一个方法团灭 nSum 问题
1. 两数之和
18. 四数之和
167. 两数之和 II - 输入有序数组 => 可以双指针,也可以hash表
荷兰三色旗问题:75. 颜色分类
844. 比较含退格的字符串
334. 递增的三元子序列
其他
424. 替换后的最长重复字符 => 滑动窗口+双指针(很优秀的题目)
1208. 尽可能使字符串相等
456. 132模式 => 维护左侧最小值!!
4.x随机算法
蓄水池抽样算法
- 目的
在大数据场景中,如果想从数据量很大的n个数中以相等的概率随机选取k个数(假设总数为n,则每个数被选中的概率都应该是 k / n k/n k/n)。其中n未知或者很大,无法把所有数据直接加载到内存,从而不能对数据进行随机读取,我们需要在对数据的一次遍历中完成等概率抽取k个数的任务 - 算法
1.先读取k个数作为蓄水池
2.从 i = k + 1 i=k+1 i=k+1开始,以 k / i k/i k/i的概率选取第 i i i个数;若选取了第 i i i个数,则用它随机替换掉蓄水池中原来的某个数
3.重复2的步骤,直到对所有数据完成一次遍历,最终蓄水池中的数据就是随机抽样的结果 - 证明
P 1 ( 第 i 个 数 最 终 在 蓄 水 池 中 ) = P 2 ( 第 i 个 数 被 选 进 蓄 水 池 ) ? P 3 ( 第 i 个 数 没 有 被 后 面 的 数 字 从 蓄 水 池 中 替 换 出 来 ) P1(第i个数最终在蓄水池中)=P2(第i个数被选进蓄水池)*P3(第i个数没有被后面的数字从蓄水池中替换出来) P1(第i个数最终在蓄水池中)=P2(第i个数被选进蓄水池)?P3(第i个数没有被后面的数字从蓄水池中替换出来)
其中, P 2 = k i P2=\frac ki P2=ik?
P 3 = P ( 后 面 的 元 素 没 有 被 选 择 ) + P ( 后 面 的 元 素 被 选 择 但 是 替 换 出 来 的 不 是 第 i 个 数 ) P3=P(后面的元素没有被选择)+P(后面的元素被选择但是替换出来的不是第i个数) P3=P(后面的元素没有被选择)+P(后面的元素被选择但是替换出来的不是第i个数)
=> P 3 = [ ( i + 1 ? k i + 1 + k i + 1 ( 1 ? 1 k ) ) × ( i + 2 ? k i + 2 + k i + 2 ( 1 ? 1 k ) ) . . . ( n ? k n + k n ( 1 ? 1 k ) ) ] = i n P3=[(\frac{i+1-k}{i+1}+\frac{k}{i+1}(1-\frac1k))\times(\frac{i+2-k}{i+2}+\frac{k}{i+2}(1-\frac1k))...(\frac{n-k}{n}+\frac{k}{n}(1-\frac1k))]=\frac in P3=[(i+1i+1?k?+i+1k?(1?k1?))×(i+2i+2?k?+i+2k?(1?k1?))...(nn?k?+nk?(1?k1?))]=ni?
综上: P 1 = p 2 × P 3 = k n P1=p2\times P3=\frac kn P1=p2×P3=nk?,即每个数字最终被抽到的概率都是相同的 - 代码
choice = file[1:k] i = k+1 while file[i] != None r = random(1,k); with probability k/i: choice[r] = choice[i] i++ print choice - 特例
当k=1时的特殊情况,见:382. 链表随机节点
洗牌算法
拒绝抽样
思路:大概就是我们可以随机产生一个抽样,只是这个抽样的范围大于期望的范围,于是不断进行抽样,直到落在预期范围内
478. 在圆内随机生成点
470. 用 Rand7() 实现 Rand10()
使用数组与hash高效随机取数
- 概述
1.对于想要等概率地高效随机取数,底层多半需要使用数组来实现=> 生成地随机数 mod 数组长度
2.但是,这要求数组是紧凑的,不能随意从中间删除元素 => 将要删除地中间元素与数组末尾元素交换,在末尾删除
3.如果是要访问/删除指定的值,光凭数组时间开销较大,此时可以使用hash完成值到数组下标的映射
=> 详细讲解及题目:
给我O(1)时间,我可以删除/查找数组中的任意元素
380. 常数时间插入、删除和获取随机元素
710. 黑名单中的随机数
4.x计算几何
极角排序
- 概念
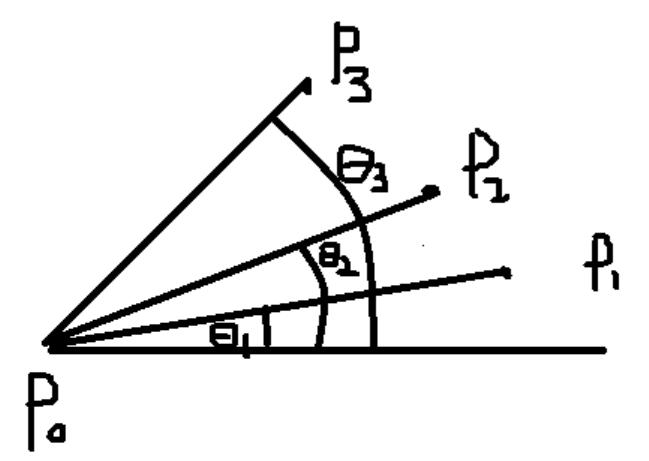
极角排序就是对于某个给定点(P0),根据其他点相对于给定点的角度大小(θ1、θ2、θ3),对其他点进行排序(排序结果为P1、P2、P3)
常用方法有:atan2、叉积法等,下文仅讲解叉积法原理 - 叉积法

注:不用纠结象限问题,不管所有点处于哪个象限,上述算法都是正确的// 以p为基准,根据返回值的正负判断q 、r的大小 int orientation(Point p, Point q, Point r) { //返回叉积结果 return (q.y - p.y) * (r.x - q.x) - (q.x - p.x) * (r.y - q.y); }
凸包问题
- 问题描述
给定一堆(二维)坐标点,找出能包围所有点的最小凸多边形(对应的点) - 极边法
思路:对于两点连成的线段,如果是凸多边形的边,则其余所有点都在该线段的一侧 => 遍历所有线段O(n^2),判断是否为凸多边形的边O(n),总时间复杂度为O(n ^3); 类似的还有极点法等 - Jarvis 算法
1.先找到一个极点(通常取x坐标最小的点 => 方便逆时针找点)
2.以此极点p为基准,遍历所有点,找到一个极角最小的点q,则q必定是极点
3.将p更新为q,重复步骤2,直到p回到步骤1选取的点
注意:实现算法时需要处理三个点在同一条线上的特殊情况
复杂度:时间O(n*m),n是点总数,m是极点个数
代码参考:587. 安装栅栏 - Graham扫描算法
参考:587. 安装栅栏
扫描线算法
不是一种具体的算法,而是一种思想
- 相关题目
218.天际线问题
4.x卡特兰数
4.x 数学
阶乘结果中0的个数
内容总结
以上是互联网集市为您收集整理的LeetCode-算法全部内容,希望文章能够帮你解决LeetCode-算法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。