首页 / 爬虫 / python之 爬虫入门一
python之 爬虫入门一
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python之 爬虫入门一,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3132字,纯文字阅读大概需要5分钟。
内容图文

文章目录
1.基础概念
什么是爬虫
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程
爬虫的价值
实际运用 就业
爬虫在使用场景中的分类
- 通用爬虫:抓取系统重要组成部分,抓取的是一整张页面数据
- 聚焦爬虫:建立在通用爬虫基础上。抓取的是页面中特定的局部内容
- 增量式爬虫:检测网站中数据更新的情况。只会抓取网站中更新出来的数据
爬虫的矛与盾
- 反爬机制:门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取
- 反反爬机制:爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据
robots.txt协议
君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬虫爬取
http协议
概念
服务器和客户端进行数据交互的一种形式
常用的请求头信息
- User-Agent:请求载体的身份标识
- Connection:请求完毕后,断开连接还是保持连接 close,keep alive两种
常见的响应头信息
Content-Type:服务器响应客户端的数据类型
HTTPS协议
安全的超文本传输协议(传输和交互过程中数据进行加密)
加密方式
- 对称密钥加密
- 非对称密钥加密
- 证书密钥加密
2.Request模块
2.1概念
Python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高
2.2作用
模拟浏览器发请求
2.3使用方法(request模块的编码流程)
- 指定URL
- 发起请求
- 获取响应数据
- 持久化存储
样例展示爬取
#爬取百度首页
import requests
if __name__=="__main__":
#指定url
url='https://www.sogou.com/'
# 发起get请求 get方法会返回一个对象
req = requests.get(url=url)
# 获取响应数据 text返回的是字符串形式1的响应数据
page_text = req.text
print(page_text)
with open('./sogou.html','w',encoding='utf-8') as fp :
fp.write(page_text)
print('爬虫结束')
UA监测
门户网站的服务器会监测对应请求载体 的身份标识,如果监测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求,但是,如果监测到的请求载体的身份标识不是基于某一款浏览器,说明该请求为不正常的请求(爬虫),则服务器端就很有可能拒绝该次请求
UA伪装
让爬虫对应的请求载体身份标识伪装成某一款浏览器
User-Agent:请求载体的身份标识
样例展示
import requests
kw=input('请输入你要查询的信息')
param={
'query':kw
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.57'
}
reponse=requests.get(url='https://www.sogou.com/web',params=param,headers=headers)
page=reponse.text
filename='./'+kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page)
print('保存成功')
百度翻译
由于在运用百度翻译时输入单词后就会有响应是翻译显示,属于ajax同步请求,打开控制台找sug找到响应的ip地址和其他的配置
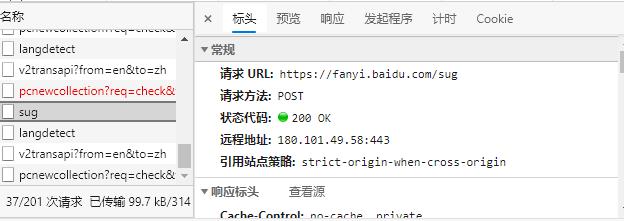
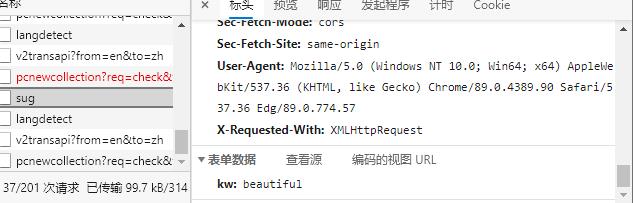
代码展示
import requests
#指定url
post_url='https://fanyi.baidu.com/sug'
word=input('请输入要翻译的单词')
#post请求参数处理(同get请求一样)
data={
'kw':word
}
# 进行UA伪装
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.57'
}
# 发送请求
response=requests.post(url=post_url,data=data,headers=headers)
# 获取响应数据:json()方法返回的是obj(如果缺人响应数据是json类型的,才可以使用json)
ans=response.json();
print(ans)
内容总结
以上是互联网集市为您收集整理的python之 爬虫入门一全部内容,希望文章能够帮你解决python之 爬虫入门一所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。