假设,你有这样一个网络层: 第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。 现在对他们赋上初值,如下图: 其中,输入数据 i1=0.05,i2=0.10; 输出数据 o1=0.01,o2=0.99; 初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30; w5=0.40,w...
机器学习AI算法工程 公众号: datayx
深度学习学习7步骤
1.学习或者回忆一些数学知识 因为计算机能做的就只是计算,所以人工智能更多地来说还是数学问题[1]。我们的目标是训练出一个模型,用这个模型去进行一系列的预测。于是,我们将训练过程涉及的过程抽象成数学函数:首先,需要定义一个网络结构,相当于定义一种线性非线性函数;接着,设定一个优化目标,也就是定义一种损失函数(loss function)。
而训练的过程,就是求解最...
??????????????????????? ??????????????????????? ??????????????????????? ??????????????? 1. 神经网络这是一个常见的神经网络的图:设置学习速率,计算的到w1的权重值3. 计算获取最佳的权重我们将获取的新的权重不停的迭代,迭代一定的次数后直到接近期望值o1:0.5 o2:0.9后,所的到权重w1...w8,就是所需要的权重。???????????? ???????????????????
以此网络为例进行反向传播分析前向传播算法
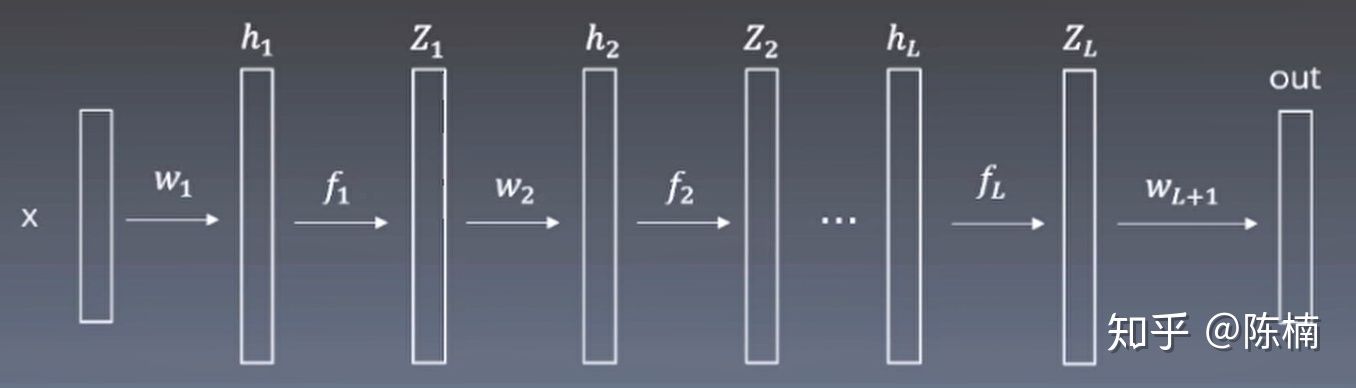
从输入\(x\)经过第一层网络\(W_1\)有
\(W_1 = \begin{equation} \left( \begin{array}{ccc} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ b_{11} & b_{12} & b_{13} \\ \end{array} \right) \end{equation}\) , \(X_1=\begin{equation}\left( \begin{array}{ccc} i_1 \\ i_2 \\i_3 \\ 1 \end{array}\right)\end{equation}\), \(Z_1 = \begin{e...
向量化编程
参考:
https://www.zybuluo.com/hanbingtao/note/476663
神经网络
神经网络最开始是受生物神经系统的启发,为了模拟生物神经系统而出现的。大脑最基本的计算单元是神经元,人类的神经系统中大概有86亿的神经元,它们之间通过1014-1015的突触相连接。每个神经元从它的树突(dendrites)接受输入信号,沿着唯一的轴突(axon)产生输出信号,而轴突通过分支(branches of axon),通过突触(synapses)连接到其他神经元的树突,神经元之间就这通过这样的连接,进行传递。如下图。链式法则
先来...
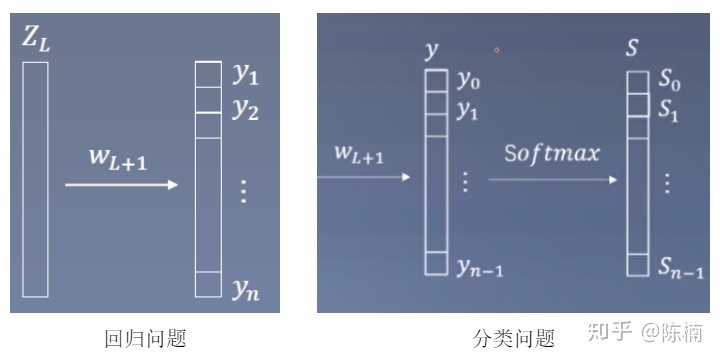
1 代价函数假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络层数,S_I表示每层的neuron个数(S_l表示输出层神经元个数),S_L代表最后一层中处理单元的个数。 将神经网络的分类定义为两种情况:二类分类和多类分类,二类分类:表示哪一类;K类分类:表示分到第i类;k>2 我们回顾逻辑回归问题中我们的代价函数为: 在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量y,...
直观理解反向传播
反向传播算法是用来求那个复杂到爆的梯度的。
上一集中提到一点,13000维的梯度向量是难以想象的。换个思路,梯度向量每一项的大小,是在说代价函数对每个参数有多敏感。如上图,我们可以这样里理解,第一个权重对代价函数的影响是是第二个的32倍。
我们来考虑一个还没有被训练好的网络。我们并不能直接改动这些激活值,只能改变权重和偏置值。但记住,我们想要输出层出现怎样的变动,还是有用的。我们希望图像...
前一章介绍了Deep Learning 中DBN算法(DL 系列一),发现当参数W经过stacked RBM 后,还需要Supervised Learning,即NN来优化参数。然而 怎样去优化呢? 参见 UFLDL教程之神经网络与反向传导算法,以及 Dark_Scope 的NN代码解读。 本章将结合DBN与NN的算法前一章介绍了Deep Learning 中DBN算法(DL 系列一),发现当参数W经过stacked RBM 后,还需要Supervised Learning,即NN来优化参数。然而怎样去优化呢?
参见
UFLDL教程之神...
原文链接:https://blog.csdn.net/weixin_41718085/article/details/79381863原文地址:https://blog.csdn.net/weixin_41718085/article/details/79381863
摘要: 最近在学习 Coursera 上 Andrew Ng 的 Machine Learning 课程。这是一个面向应用,注重实践而尽量避免数学证明的课程,好处在于能快速帮助更多新人入门。然而从新手到高手的路是绕不开数学的。第五周的课程讲授了人工神经网络参数的训练,其中用到了反向传播算法。本文...
神经网络的损失函数为
\[J\left( \Theta \right) = - \frac{1}{m}\left[ {\sum\limits_{i = 1}^m {\sum\limits_{k = 1}^k {y_k^{\left( i \right)}\log {{\left( {{h_\Theta }\left( {{x^{\left( i \right)}}} \right)} \right)}_k} + \left( {1 - y_k^{\left( i \right)}} \right)\log \left( {1 - {{\left( {{h_\Theta }\left( {{x^{\left( i \right)}}} \right)} \right)}_k}} \right)} } } \right] + \frac{\lambda }{{2m}}\...
神经网络中反向传播算法(BP)
本文只是对BP算法中的一些内容进行一些解释,所以并不是严格的推导,因为我在推导的过程中遇见很多东西,当时不知道为什么要这样,所以本文只是对BP算法中一些东西做点自己的合理性解释,也便于自己理解。
要想看懂本文,要懂什么是神经网络,对前向传播以及神经网络中一些常见定义要熟悉。
为什么是 δ\deltaδ假如上面是一个神经网络的任意层l和l+1层,那么我们如果进行BP算法,就是相当于把一个损...
??????????? ??????????? ??????????? ??????????????? 1 反向传播算法和BP网络简介 误差反向传播算法简称反向传播算法(即BP算法)。使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为:(1)先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的);(2)计算每一层的误差,误差的计算过程是从最后一层向前推进的(这就是反向传播算法名字的由来);(3)更新参数(目标是误差变小...
???????????????????????????????????? 1 反向传播算法和BP网络简介 误差反向传播算法简称反向传播算法(即BP算法)。使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为:(1)先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的);(2)计算每一层的误差,误差的计算过程是从最后一层向前推进的(这就是反向传播算法名字的由来);(3)更新参数(目标是误差变小)。迭代前面两个...
循环神经网络(RNN)模型与前向反向传播算法,LSTM模型笔记输出和模型间有反馈的神经网络:循环神经网络(Recurrent Neural Networks),广泛用于自然语言处理中的语音识别、手写识别以及机器翻译等领域。特点:1.隐藏状态h由输入x和前一隐藏状态hi-1共同决定。2.模型的线性关系参数U、W、V矩阵在整个RNN网络中共享,从而体现了RNN模型的循环反馈思想。在语音识别、手写识别以及机器翻译等领域实际应用比较广泛的是基于RNN模型的LST...
")
之间的KL距离:
,其中1为第