首页 / 爬虫 / Python3网络爬虫开发实战(一)
Python3网络爬虫开发实战(一)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python3网络爬虫开发实战(一),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含6624字,纯文字阅读大概需要10分钟。
内容图文
")
1.开发环境配置
1.1Python3的安装
在写博客之前,楼主使用的是目前为止最新版本的Python 3.9.1。但由于在安装tesserocr时,没有对应版本的wheel文件。因此,将Python的版本降到了3.7.9。具体的影响因为刚开始学习暂时未知,先用3.7.9的版本。
1.2请求库的安装
爬虫可以简单的分为几步:抓取页面、分析页面、存储数据。
-
在抓取页面的过程中,需要模拟浏览器向服务器发出请求,需要用到一些Python库来实现HTTP请求操作。
-
用到的第三方库有
requests、Selenium、aiohttp-
requests:
中文文档:http://docs.python-requests.org/zh_CN/latest
pip安装:
pip install requests验证安装:
import requests,如没有错误提示,则安装成功。 -
Selenium:
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些JavaScript渲染的页面来说,这种抓取方式非常有效。
中文文档:http://selenium-python-zh.readthedocs.io
pip安装:
pip install selenium验证安装:
import selenium,如没有错误提示,则安装成功 -
ChromeDriver:
配合
Selenium进行使用。安装前确保正确安装Chrome浏览器并正常运行。下载地址:https://chromedriver.storage.googleapis.com/index.html
环境变量配置:Windows下,建议直接将chromedriver.exe文件拖到Python的Scripts目录下。
验证安装:配置完成后,可以直接在命令行下执行chromedriver命令
?
chromedriver? 类似输出为:
Starting ChromeDriver 88.0.4324.96 (68dba2d8a0b149a1d3afac56fa74648032bcf46b-refs/branch-heads/4324@{#1784}) on port 9515
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.? (Note:保持ChromeDriver运行)随后在程序中测试。执行如下Python代码:
from selenium import webdriver browser = webdriver.Chrome()? 运行之后,如果弹出一个空白的Chrome浏览器则配置成功。如果弹出后闪退,则可能是Chromedriver版本与Chrome版本不兼容。
-
GeckoDriver:
对于Firefox,使用同样的方式完成Selenium的对接。
下载地址:https://github.com/mozilla/geckodriver/releases
环境变量配置:在Windows下,可以直接将geckodriver.exe文件拖到Python的Scripts目录下。
验证安装:配置完成后,可以直接在命令行下执行geckodriver命令
?
geckodriver? 类似输出为:
1611245059623 geckodriver INFO Listening on 127.0.0.1:4444? (Note:保持GeckoDriver运行)随后在程序中测试。执行如下Python代码:
from selenium import webdriver browser = webdriver.Firefox()? 运行之后,若弹出一个空白的 Firefox 浏览器,则证明所有的配置都没有问题。
-
PhantomJS:
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '(Note:selenium已经放弃PhantomJS了,建议使用火狐或者谷歌无界面浏览器)
-
aiohttp:
requests是一个阻塞式HTTP请求库,当我们发出一个请求后,程序会一直等待服务器响应,直到服务器响应后,程序才会进行下一步处理。aiohttp提供异步Web服务,大大提高了效率
pip安装:
pip install aiohttp
-
-
1.3解析库的安装
-
抓取网页代码之后,下一步就是从网页中提取信息。方式多种多样,可以使用正则来提取,但是写起来相对繁琐。
-
所以提供了解析库,如
lxml、Beautiful Soup、pyquery等。-
lxml:
支持 HTML 和 XML 的解析,支持 XPath 解析方式,而且解析效率非常高。
pip安装:
pip install lxml验证安装:
import lxml,若没有错误提示,则安装成功。 -
Beautiful Soup:
是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。它拥有强大的API和多样的解析方式。
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh
准备工作:Beautiful Soup的HTML和XML解析器是依赖于lxml库的,所以在此之前请确保已经成功安装好了lxml库。
pip安装:
pip install beautifulsoup4验证安装:
from bs4 import BeautifulSoup soup = BeautifulSoup('<p>Hello</p>', 'lxml') print(soup.p.string) # 运行结果如下,则证明安装成功 #Hello -
pyquery:
提供了和jQuery类似的语法来解析HTML文档,支持CSS选择器
pip安装:
pip install pyquery验证安装:
import pyquery,若没有错误报出,则安装成功。 -
tesserocr:
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于验证码,可以使用OCR技术将其转化为电子文本,然后爬虫将识别结果提交给服务器,便可以达到自动识别验证码的过程。
(Note:在安装tesserocr之前,需要安装tesseract)
-
tesseract的安装
下载地址:http://digi.bib.uni-mannheim.de/tesseract
(Note:文件名中带有dev的为开发版本,不带的为稳定版本)
语言包:https://github.com/tesseract-ocr/tessdata
文档:https://github.com/tesseract-ocr/tesseract/wiki/Documentation
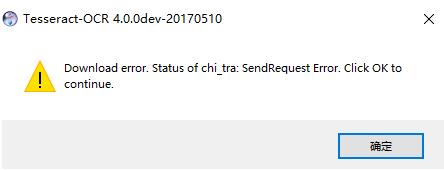
下载时可以勾选Additional language data (download)选项来安装 OCR 识别支持的语言包。但是,可能由于被墙的原因,导致下载失败,会报如下错误(并不是版本的问题)。此时,可取消勾选,进行安装。单独下载语言包。
-
tesserocr的安装
pip安装:
pip install tesserocr pillow但是,问题又来了,楼主始终安装不成功。看到错误提示:缺少Visual C++。便选择了使用wheel文件进行的安装。

Wheel文件地址:https://github.com/simonflueckiger/tesserocr-windows_build/releases
在下载Wheel文件时,要与之前tesseract的版本相一致。也是在此由于Wheel文件只有python3.7版本的,才不得不将之前Python3.9主动降级。
-
-
验证安装:`tesseract image.png result -l eng && cat result.txt`(**Note**:cat result.txt是Linux下的命令) Windows应该直接输出:`tesseract image.png stdout -l eng` -
1.4数据库的安装
数据库可以分为关系型数据库和非关系型数据库。关系型数据库如SQLite、MySQL、Oracle、SQL Server、DB2等,其数据库是以表的形式存储;非关系型数据库如MongoDB、Redis,它们的存储形式是键值对,存储形式更加灵活。
-
用到的数据库主要有关系型数据库MySQL及非关系型数据库MongoDB、Redis
-
由于楼主已经安装完毕,暂无法给出具体安装过程。
-
Mysql:
官方网站:https://www.mysql.com/cn
下载地址:https://www.mysql.com/cn/downloads
中文教程:http://www.runoob.com/mysql/mysql-tutorial.html
-
MongoDB:
其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组。
中文教程:http://www.runoob.com/mongodb/mongodb-tutorial.html
-
Redis:
官方网站:https://redis.io
官方文档:https://redis.io/documentation
中文官网:http://www.redis.cn
中文教程:http://www.runoob.com/redis/redis-tutorial.html
Redis Desktop Manager:https://redisdesktop.com
Windows下:https://github.com/MSOpenTech/redis/releases
-
1.5存储库的安装
数据库提供了存储服务,但如果想要和Python交互的话,还需要安装一些Python存储库,如MySQL需要安装 PyMySQL,MongoDB需要安装PyMongo等。
-
PyMySQL:
pip安装:
pip install pymysql验证安装:
import pymysql pymysql.VERSION # (1, 0, 2, None) # 如果成功输出其版本内容,则证明成功安装 -
PyMongo:
pip安装:
pip install pymongo验证安装:
import pymongo pymongo.version # '3.11.2' # 如果成功输出其版本内容,则证明成功安装 -
redis-py:
pip安装:
pip install redis验证安装:
import redis redis.VERSION # (3, 5, 3) # 如果成功输出其版本内容,则证明成功安装
结束语:库的安装暂时到这里,如有需要再次添加完善。
内容总结
以上是互联网集市为您收集整理的Python3网络爬虫开发实战(一)全部内容,希望文章能够帮你解决Python3网络爬虫开发实战(一)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。