首页 / 算法 / 数据结构与算法——希尔排序
数据结构与算法——希尔排序
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了数据结构与算法——希尔排序,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3734字,纯文字阅读大概需要6分钟。
内容图文

目录原文链接:https://jiang-hao.com/articles/2020/algorithms-algorithms-shell-sort.html
算法原理
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
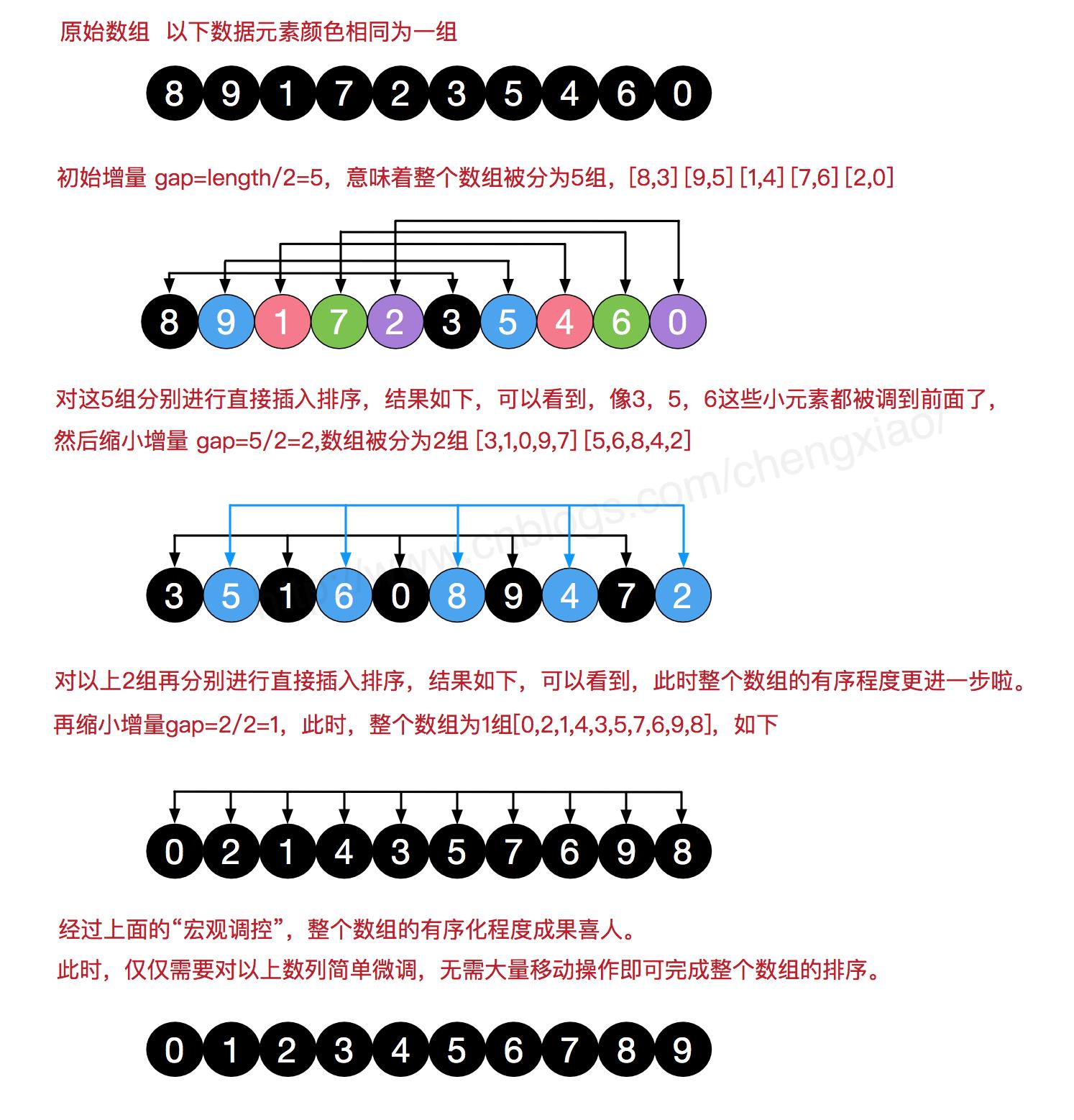
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。该方法实质上是一种分组插入方法。
希尔排序把元素按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
简单插入排序很循规蹈矩,不管数组分布是怎么样的,依然一步一步的对元素进行比较,移动,插入,比如[5,4,3,2,1,0]这种倒序序列,数组末端的0要回到首位置很是费劲,比较和移动元素均需n-1次。而希尔排序在数组中采用跳跃式分组的策略,通过某个增量将数组元素划分为若干组,然后分组进行插入排序,随后逐步缩小增量,继续按组进行插入排序操作,直至增量为1。希尔排序通过这种策略使得整个数组在初始阶段达到从宏观上看基本有序,小的基本在前,大的基本在后。然后缩小增量,到增量为1时,其实多数情况下只需微调即可,不会涉及过多的数据移动。
我们来看下希尔排序的基本步骤,在此我们选择增量gap=length/2,缩小增量继续以gap = gap/2的方式,这种增量选择我们可以用一个序列来表示,{n/2,(n/2)/2...1},称为增量序列。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。
代码实现
在希尔排序的理解时,我们倾向于对于每一个分组,逐组进行处理,但在代码实现中,我们可以不用这么按部就班地处理完一组再调转回来处理下一组(这样还得加个for循环去处理分组)比如[5,4,3,2,1,0] ,首次增量设step=length/2=3,则为3组[5,2] [4,1] [3,0],实现时不用循环按组处理,我们可以从下标为step的元素开始,逐个跨组处理。同时,在插入数据时,可以采用元素交换法寻找最终位置,也可以采用数组元素移动法寻觅。希尔排序的代码比较简单,共包含三层for循环,如下:
public static int[] shell_sort(int[] nums) {
int[] arr = Arrays.copyOf(nums, nums.length);
// 迭代逐步缩小增量step
for (int step=nums.length/2; step>0; step/=2) {
// 从下标为step的元素开始,逐个对其所在组进行直接插入排序操作
for (int i=step; i<nums.length; i++) {
int target = arr[i];
int j;
// 移动插入法
for (j=i; j-step>=0 && target<arr[j-step]; j-=step) {
arr[j] = arr[j-step];
}
arr[j] = target;
}
}
return arr;
}
增量序列及时间复杂度
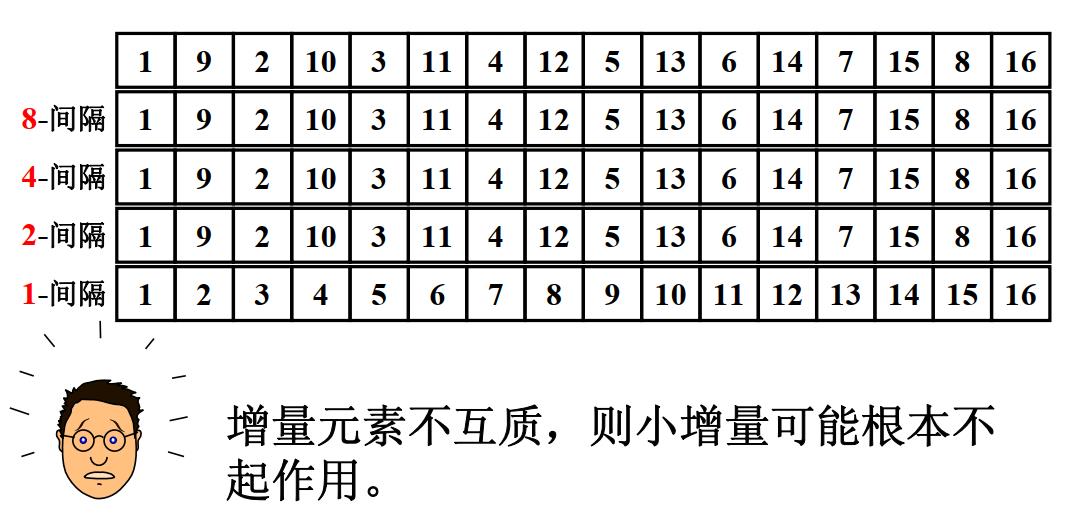
好的增量序列的共同特征:
① 最后一个增量必须为1;
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。

Shell 增量序列
Shell 增量序列的递推公式为:
$$
h_t=N/2,h_k=h_{k+1}/2
$$
对于每次除以 2 的增量选择,希尔排序的最好情况当然是本身有序,每次分区都不用排序,时间复杂度是 O(n);但是在最坏的情况下仍然每次都需要移动,时间复杂度与直接插入排序在最坏情况下的时间复杂度没什么区别,也是 O(n^2)。
Shell 增量序列构造代码如下:
int IncrementSequence_Shell[35];
void IncrementSequenceBuild_Shell()
{
IncrementSequence_Shell[0]=1;
IncrementSequence_Shell[1]=n;
while(IncrementSequence_Shell[IncrementSequence_Shell[0]]>1)
IncrementSequence_Shell[++IncrementSequence_Shell[0]]=IncrementSequence_Shell[IncrementSequence_Shell[0]-1]/2;
}
Shell增量序列不满足互质的要求,因此在上方图1所示的例子里,前几个增量没有起到任何作用(只起到了拖延时间的作用哈哈)。
于是有些大佬们就整出了下面这些增量序列:Hibbard增量序列、Knuth增量序列、Sedgewick增量序列等等。
Hibbard增量序列
Hibbard增量序列的通项公式为:
$$
h_i=2^i?1
$$
Hibbard增量序列的递推公式为:
$$
h_1=1,h_i=2?h_{i-1}+1
$$
即:
$$
{1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, 2047, 4095, 8191...}
$$
最坏时间复杂度为
内容总结
以上是互联网集市为您收集整理的数据结构与算法——希尔排序全部内容,希望文章能够帮你解决数据结构与算法——希尔排序所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。