Python微博用户主页小姐姐图片内容采集爬虫!
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python微博用户主页小姐姐图片内容采集爬虫!,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2757字,纯文字阅读大概需要4分钟。
内容图文

python爬虫,微博爬虫,需要知晓微博用户id号,能够通过抓取微博用户主页内容来获取用户发表的内容,时间,点赞数,转发数等数据,当然以上都是本渣渣结合网上代码抄抄改改获取的!

要抓取的微博地址:https://weibo.com/u/5118612601
BUT,我们实际应用的抓取地址:https://m.weibo.cn/u/5118612601(移动端的微博地址)





LSP的最爱,各种小姐姐,随你任意爬取,快收藏起来啊!
通过浏览器抓包,我们可以获悉几个比较重要的参数:
type:?uidvalue:?5118612601containerid:?1005055118612601其实还有一个比较重要的参数,那就是翻页:'page':page!
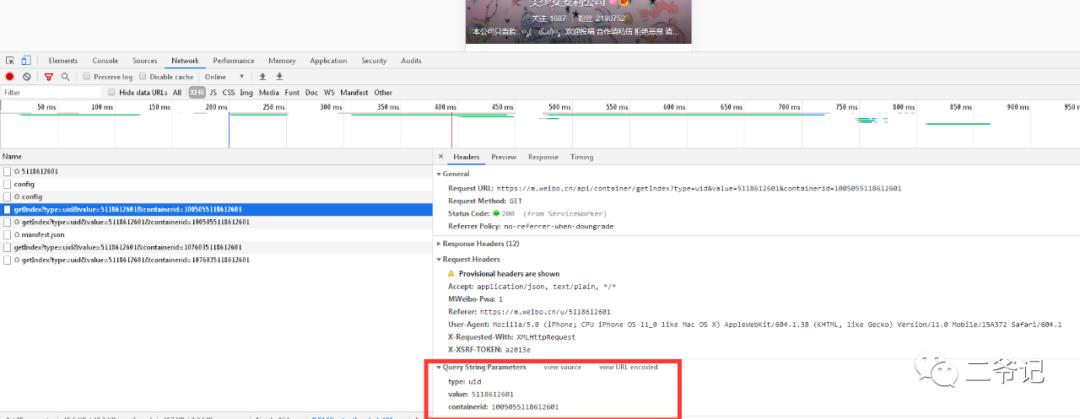
还有一个SSL错误问题,大家可以自行处理!
#多线程下载图片
def get_imgs(self,img_urls,img_path):
threadings = []
for img_url in img_urls:
t = threading.Thread(target=self.get_img, args=(img_url,img_path))
threadings.append(t)
t.start()
for x in threadings:
x.join()
print("多线程下载图片完成")
def get_img(self, img_url,img_path):
img_name = img_url.split('/')[-1]
print(f'>> 正在下载图片:{img_name} ..')
r = requests.get(img_url, timeout=8, headers=self.headers,verify=False)
with open(f'{img_path}/{img_name}', 'wb') as f:
f.write(r.content)
print(f'>> 图片:{img_name} 下载完成!')
几个关键点
- 获取 containerid 参数
????def?get_containerid(self):????????url?=?f'https://m.weibo.cn/api/container/getIndex?type=uid&value={self.uid}'????????data?=?requests.get(url,headers=self.headers,timeout=5,verify=False).content.decode('utf-8')????????content?=?json.loads(data).get('data')????????for?data?in?content.get('tabsInfo').get('tabs'):????????????if?(data.get('tab_type')?==?'weibo'):????????????????containerid?=?data.get('containerid') ????????self.containerid=containerid- 获取 微博用户发表 数据
- 多线程下载图片
????#多线程下载图片
????def?get_imgs(self,img_urls,img_path):
????????threadings?=?[]
????????for?img_url?in?img_urls:
????????????t?=?threading.Thread(target=self.get_img,?args=(img_url,img_path))
????????????threadings.append(t)
????????????t.start()
????????for?x?in?threadings:
????????????x.join()
????????print("多线程下载图片完成")
????def?get_img(self,?img_url,img_path):
????????img_name?=?img_url.split('/')[-1]
????????print(f'>>?正在下载图片:{img_name}?..')
????????r?=?requests.get(img_url,?timeout=8,?headers=self.headers,verify=False)
????????with?open(f'{img_path}/{img_name}',?'wb')?as?f:
????????????f.write(r.content)
????????print(f'>>?图片:{img_name}?下载完成!')
本来还想搞个多进程,结果翻车了,报错各种头秃,那就不搞了!!



手里头有二份微博爬虫的源码,不同的爬取地址和思路,一起分享给大家,仅供参考学习!
一份还包含GUI界面,当然这是本渣渣参考的主要来源代码!
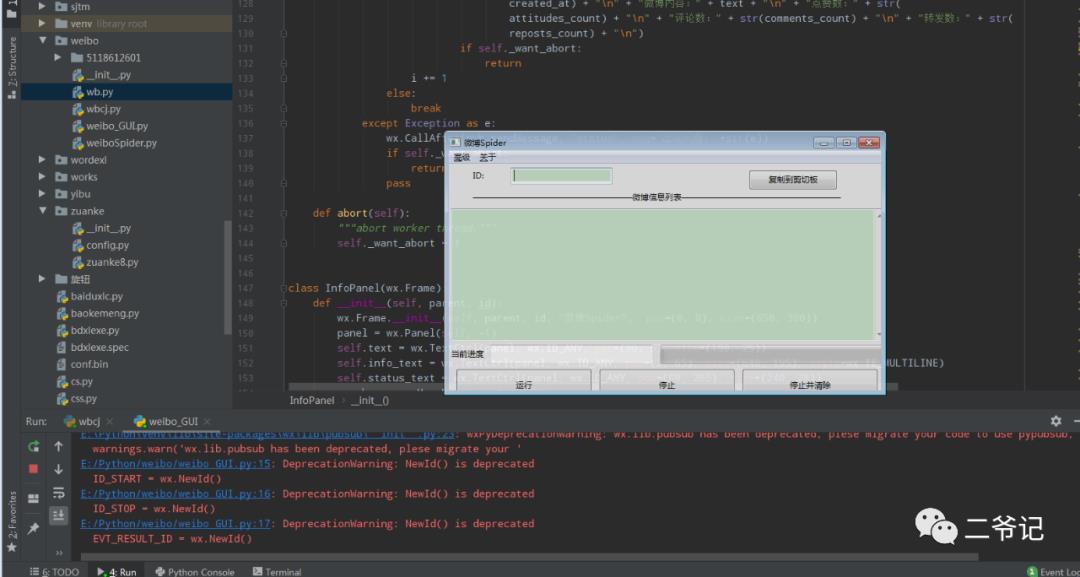
亲测可运行哈!!

PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
内容总结
以上是互联网集市为您收集整理的Python微博用户主页小姐姐图片内容采集爬虫!全部内容,希望文章能够帮你解决Python微博用户主页小姐姐图片内容采集爬虫!所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。