Python多线程爬虫实战案例:各大主播信息资料的爬取采集
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python多线程爬虫实战案例:各大主播信息资料的爬取采集,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4219字,纯文字阅读大概需要7分钟。
内容图文


前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
头榜,一个集合主播信息及资讯的网站,内容比较齐全,现今直播火热,想要找寻各种播主信息,这类网站可以搜集到相关热门主播信息。
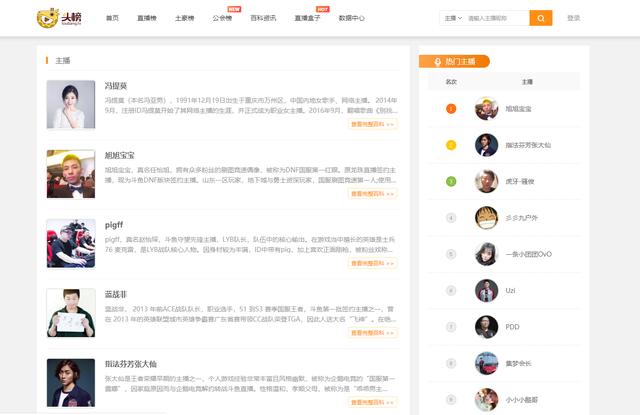
目标网址:
http://www.toubang.tv/baike/list/20.html
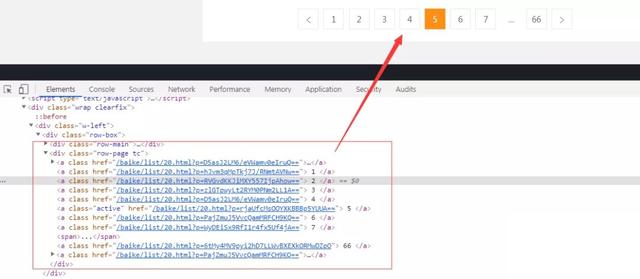
列表页,而且暂时没有发现列表页规律,加密了?
http://www.toubang.tv/baike/list/20.html?p=hJvm3qMpTkj7J/RNmtAVNw== http://www.toubang.tv/baike/list/20.html?p=rjaUfcMsOOYXKBBBp5YUUA==
很明显,p后面所带的参数就是页码,但是搞不明白是如何实现的一串字符串,目测没有明显的页码规律。
没有过多的研究,霸王硬上弓,硬搞吧!
直接把所有列表页上遍历一遍,获取到页码链接,这里我简单的使用了递归函数
获得所有列表页的集合,至于去重,这里直接使用了set(),直接将集合转化为set
递归代码
def get_apgeurls(apgeurls):
page_urls=[]
for apgeurl in apgeurls:
page_url=get_pageurl(apgeurl)
page_urls.extend(page_url)
page_urls=set(page_urls)
#print(len(page_urls))
if len(page_urls) < 66:
return get_apgeurls(page_urls) #链轮
else:
return page_url
好在分页数不多,算是一个比较笨的实现方法,注意return的使用,递归函数调用函数本身,return会返回None,这里通过百度查询相关资料获取到解决方案。
其他的一些获取内容,都是正常操作,这里就不再阐述了!
提一下多线程吧!
def get_urllists(urls):
threads = []
for url in urls:
t=threading.Thread(target=get_urllist,args=(url,))
threads.append(t)
for i in threads:
i.start()
for i in threads:
i.join()
print('>>> 获取采集链接完毕!')
这里需要注意一个参数的调用的时候,args=(url,),同时多线程的使用,采集报错是一个很头疼的问题,基本都是服务器反应不过来,难道还是得采用Scrapy框架,大范围抓取。
运行效果:

附源码参考:
from fake_useragent import UserAgent
import requests,time,os
from lxml import etree
import threading #多线程
def ua():
ua=UserAgent()
headers={'User-Agent':ua.random}
return headers
def get_pageurl(url):
pageurl=[]
html=requests.get(url,headers=ua()).content.decode('utf-8')
time.sleep(1)
req=etree.HTML(html)
pagelists=req.xpath('//div[@class="row-page tc"]/a/@href')
for pagelist in pagelists:
if "baike" in pagelist:
pagelist=f"http://www.toubang.tv{pagelist}"
pageurl.append(pagelist)
#print(len(pageurl))
return pageurl
def get_apgeurls(apgeurls):
page_urls=[]
for apgeurl in apgeurls:
page_url=get_pageurl(apgeurl)
page_urls.extend(page_url)
page_urls=set(page_urls)
#print(len(page_urls))
if len(page_urls) < 5:
#if len(page_urls) < 65:
return get_apgeurls(page_urls) #链轮
else:
return page_urls
def get_urllist(url):
html = requests.get(url, headers=ua()).content.decode('utf-8')
time.sleep(1)
req = etree.HTML(html)
hrefs=req.xpath('//div[@class="h5 ellipsis"]/a/@href')
print(hrefs)
for href in hrefs:
href=f'http://www.toubang.tv{href}'
get_info(href)
def get_urllists(urls):
threads = []
for url in urls:
t=threading.Thread(target=get_urllist,args=(url,))
threads.append(t)
for i in threads:
i.start()
for i in threads:
i.join()
print('>>> 获取采集链接完毕!')
def get_info(url):
html = requests.get(url, headers=ua()).content.decode('utf-8')
time.sleep(1)
req = etree.HTML(html)
name=req.xpath('//div[@class="h3 ellipsis"]/span[@class="title"]/text()')[0]
os.makedirs(f'{name}/', exist_ok=True) # 创建目录
briefs=req.xpath('//dl[@class="game-tag clearfix"]/dd/span//text()')
brief_img=req.xpath('//div[@class="i-img fl mr20"]/img/@src')[0].split('=')[1]
print(name)
print(briefs)
print(brief_img)
down_img(brief_img, name)
informations=req.xpath('//table[@class="table-fixed table-hover hot-search-play"]/tbody/tr[@class="baike-bar"]/td//text()')
for information in informations:
if '\r' and '\n' and '\t' not in information:
print(information)
text=req.xpath('//div[@class="text-d"]/p//text()')
print(text)
text_imgs=req.xpath('//div[@id="wrapBox1"]/ul[@id="count1"]/li/a[@class="img_wrap"]/@href')
print(text_imgs)
threads=[]
for text_img in text_imgs:
t=threading.Thread(target=down_img,args=(text_img,name))
threads.append(t)
for i in threads:
i.start()
for i in threads:
i.join()
print("图片下载完成!")
def down_img(img_url,name):
img_name=img_url.split('/')[-1]
r=requests.get(img_url,headers=ua(),timeout=8)
time.sleep(2)
with open(f'{name}/{img_name}','wb') as f:
f.write(r.content)
print(f'>>>保存{img_name}图片成功!')
def main():
url = "http://www.toubang.tv/baike/list/20.html?p=hJvm3qMpTkjm8Rev+NDBTw=="
apgeurls = [url]
page_urls = get_apgeurls(apgeurls)
print(page_urls)
get_urllists(page_urls)
if __name__=='__main__':
main()
内容总结
以上是互联网集市为您收集整理的Python多线程爬虫实战案例:各大主播信息资料的爬取采集全部内容,希望文章能够帮你解决Python多线程爬虫实战案例:各大主播信息资料的爬取采集所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。