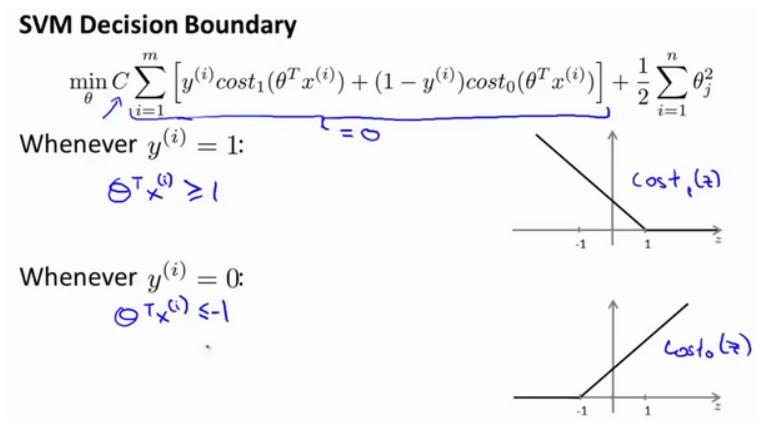
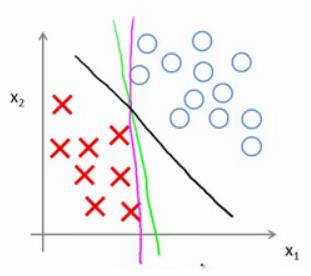
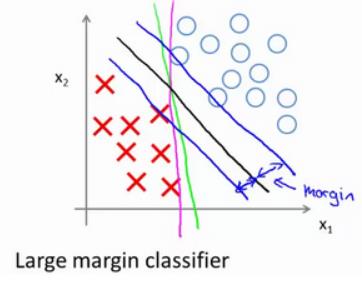
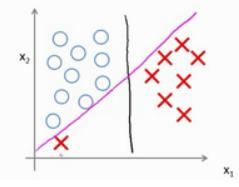
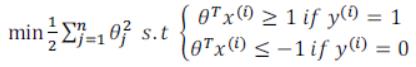(期末考试快到了,所以比较粗糙,请各位读者理解。。)一、 概念DBSCAN是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动地确定。低密度区域中的点被视为噪声而忽略,因此DBSCAN不产生完全聚类。二、 伪代码1 将所有点标记为核心点、边界点和噪声点。2 删除噪声点。3 为距离在Eps之内的所有核心点之间赋予一条边。4 每组连通的核心点形成一个簇。5 将每个边界点指派到一个与之关联的核心点的簇中。...
本文根据《大话数据结构》一书,实现了Java版的二叉排序树/二叉搜索树。二叉排序树介绍在上篇博客中,顺序表的插入和删除效率还可以,但查找效率很低;而有序线性表中,可以使用折半、插值、斐波那契等查找方法来实现,但因为要保持有序,其插入和删除操作很耗费时间。二叉排序树(Binary Sort Tree),又称为二叉搜索树,则可以在高效率的查找下,同时保持插入和删除操作也又较高的效率。下图为典型的二叉排序树。二叉查找树具有以下...
业务解决方案:0. 数据源加载1. 特征工程: 字符转数值/二值型/多值型 把字符型特征转化成算法可以处理的数值表示,实现特征抽象.特征是二值型的, 如sex 这个字段有male 和fem 两种,就把sex 抽象成0 和1。如果特征的数值是多值型, 如status,就按照严重程度从0 到1 再到2 来抽象.2.数据预处理:数值转double/归一化到0 和1 之间 通过“类型转换组件”先把数据类型全部转化成 double 型(机器学习算法普遍对double 型数据的支持比...
数据结构与算法笔记 - 绪论 1. 什么是计算2. 评判DSA优劣的参照(直尺)3. 度量DSA性能的尺度(刻度)4. DSA的性能度量的方法5. DSA性能的设计及其优化x1. 理论模型与实际性能的差异x2. DSA优化的极限(下界) 计算机与算法计算机科学(computer science)的核心在于研究计算方法与过程的规律,而不仅仅是作为计算工具的计算机本身,因此E. Dijkstra及其追随者更倾向于将这门科学称作计算科学(computing science)。计算 = 信息处理计算...
线性表数据元素的排列方式是线性的顺序表 :顺序表是在计算机中以数组的形式保存的线性表结构
除了头尾,其他的元素依次首尾相连在内存中是一块连续的存储空间,每个元素占用相同的空间,所以顺序表支持随机访问e[i]=e[1]+e[i-1]*length, 1<=i<=n,length是单个元素所占的空间Java数组
Java在定义数组的时候,在堆里面分配一个连续的固定大小的空间,用于存放基本数据类型或者对象的引用。顺序表支持随机存取,所以Java数组用任意下...
1 #include <stdio.h>2 3#define NotFound -1;4 typedef int ElementType;5 6int BinarySearch( const ElementType A[], ElementType X, int N )7{8int Low, Mid, High;910 Low = 0; High = N-1;
11while( Low <= High ) // 注意终止条件12 {
13 Mid = (Low + High) / 2;
14if( A[Mid] < X )
15 Low = Mid + 1;
16elseif( A[Mid] > X )
17 High = Mid - 1;
18else19return Mid;
20 }
21...
数组,都懂的,直接看代码吧,实现以下功能:创建数组查找在索引上的值查找数组中是否含有值删除在索引上的值添加一个值查找一个值在数组的位置public class ArrayStructures {private int[] theArray = new int[50];private int arraySize = 10;public void generateRandomArray(){for (int i =0; i< arraySize;i++){theArray[i] = (int)(Math.random()*10 + 10);}}public void printArray(){StringBuffer sb = new StringBuffer(...
头文件 1 typedef int ElementType;2 3#ifndef _STACK_AR_4#define _STACK_AR_5 6struct StackRecord;7 typedef struct StackRecord *Stack;8 9int IsEmpty(Stack S);
10int IsFull(Stack S);
11 Stack CreateStack(int MaxElements);
12void DisposeStack(Stack S);
13void MakeEmpty(Stack S);
14void Push(ElementType X, Stack S);
15ElementType Top(Stack S);
16void Pop(Stack S);
17ElementType TopAndPop(Stack S);
1819#...
好消息
博客笔记大汇总【15年10月到至今】,包括Java基础及深入知识点,Android技术博客,Python学习笔记等等,还包括平时开发中遇到的bug汇总,当然也在工作之余收集了大量的面试题,长期更新维护并且修正,持续完善……开源的文件是markdown格式的!同时也开源了生活博客,从12年起,积累共计500篇[近100万字],将会陆续发表到网上,转载请注明出处,谢谢!链接地址:https://github.com/yangchong211/YCBlogs如果觉得好,可以st...
总结:量纲化(归一化,标准化)缺失值处理(补0、均值、中值、众数、自定义)编码/哑变量:忽略数字中自带数学性质(文字->数值类型)连续特征离散化(二值化/分箱处理)原文:https://www.cnblogs.com/afanti/p/10881435.html
字典我们翻阅书籍时,很多时候都要查找目录,然后定位到我们要的页数,比如我们查找某个英文单词时,会从英语字典里查看单词表目录,然后定位到词的那一页。计算机中,也有这种需求。一、字典字典是存储键值对的数据结构,把一个键和一个值映射起来,一一映射,键不能重复。在某些教程中,这种结构可能称为符号表,关联数组或映射。我们暂且称它为字典,较好理解。如:键=>值"cat"=>2
"dog"=>1
"hen"=>3我们拿出键cat的值,就是2了...
一 存储结构 static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next;}transient Node<K,V>[] table;内部存储的单元如上所示,整体上就是数组加链表的桶状结构。二 put操作put(key,value)内部调用的是putVal() 下面是源码 jdk1.8采用的是尾插法 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V...
2014.06.17 01:17简介: 选择排序是一种O(n^2)级别的交换排序算法,属于新手必学算法。描述: 个人觉得选择排序的代码是所有排序中最直观,最符合人类大脑思维的了。当我第一次有排序的需求时(初中时自学了一点C语言,算是人生第一次写代码),我自己试着写下的代码就是选择排序,当然我上了大学才知道“选择排序”是什么。很显然,直观且容易实现的算法基本都是最鹾的,而不直观且容易实现的算法基本都是最神的。很显然,选...
摘要:本文主要介绍的是python实现归并排序算法,本文首先会介绍归并排序的原理,并以一张思维导图来加深读者对该算法过程的理解,紧接着进行代码的实现。最后介绍该算法的时间复杂度。一.原理:1.将一个序列从中间位置分成两个序列;2.在将这两个子序列按照第一步继续二分下去;3.直到所有子序列的长度都为1,也就是不可以再二分截止。这时候再两两合并成一个有序序列即可。 下面的这张图片可以很清晰的解释该原理: 二.代码如下...
大学刚学编程的时候,有一句很经典的话程序=数据结构+算法今天有了进一步认识。场景:1、当前局面(1)有现成的封装好的分页组件 返回结果是page。类型为:Page。包括 page 分页信息,data 数据列表 List型。(2)查询了一个数据列表 midResult。类型为 List<Map<String,Object>> 。2、想要的结果 现在想把page midResult 两个结果集进行处理。返回页面。3、解决问题 首先纠结的是,用哪种类型来存储数据。用List 还是Map<St...