Python3---AJAX---爬虫
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python3---AJAX---爬虫,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含657字,纯文字阅读大概需要1分钟。
内容图文

前言
该文章主要介绍面对AJAX的网页如何爬去信息,主要作用是适合刚入门爬虫查看学习
修改时间:20191219
天象独行
首先,我们先介绍一下什么是AJAX,AJAX是与服务器交换数据并跟新部分网页的艺术,整个过程并没有加载整个页面。下面我们直接举例:
1;确定爬虫目标,这里选择豆瓣电影来举例,这里我们点击“加载更多”发现在网页局部发生变化。
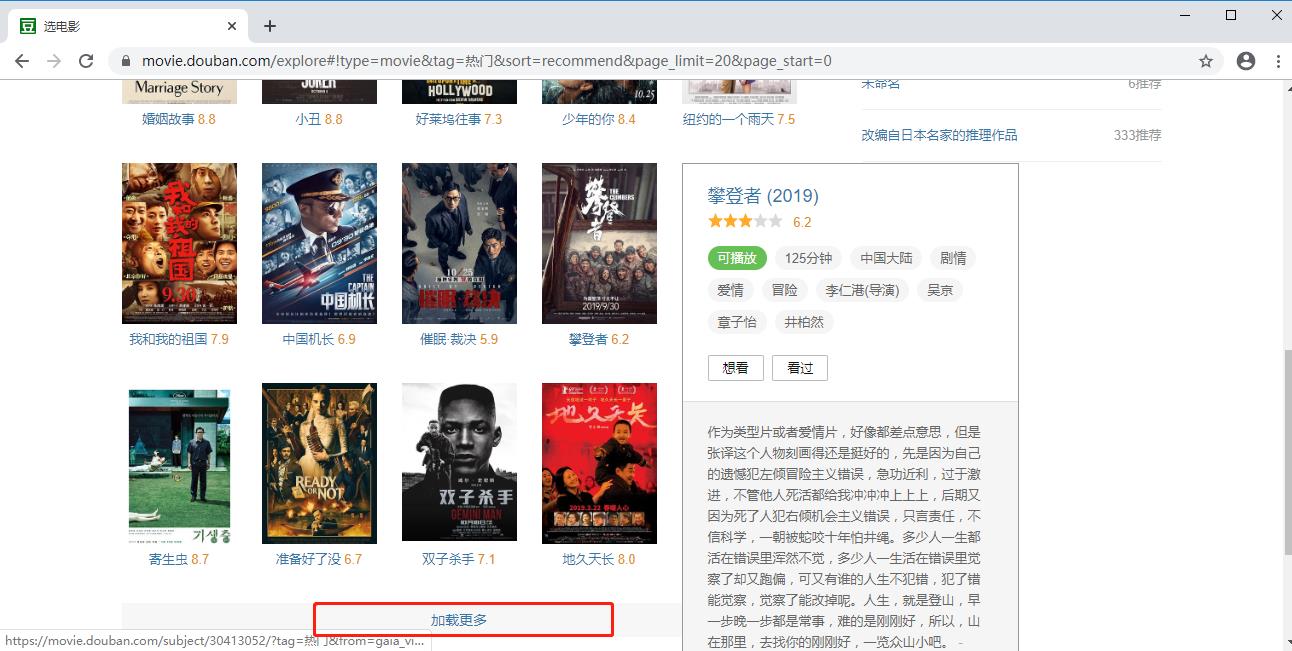
2;使用抓包工具抓取数据:

3;这里主要分析参数page_limit,以及page_start,经过分析,我们发现,page_limit参数表示需要获取电影的数目。page_start参数控制页面显示的页数。下面我们来构建爬虫。
我们先设定算法,计算page_limit以及page_start关系。

4;设定请求地址,设定GET字典传参,请求头字典
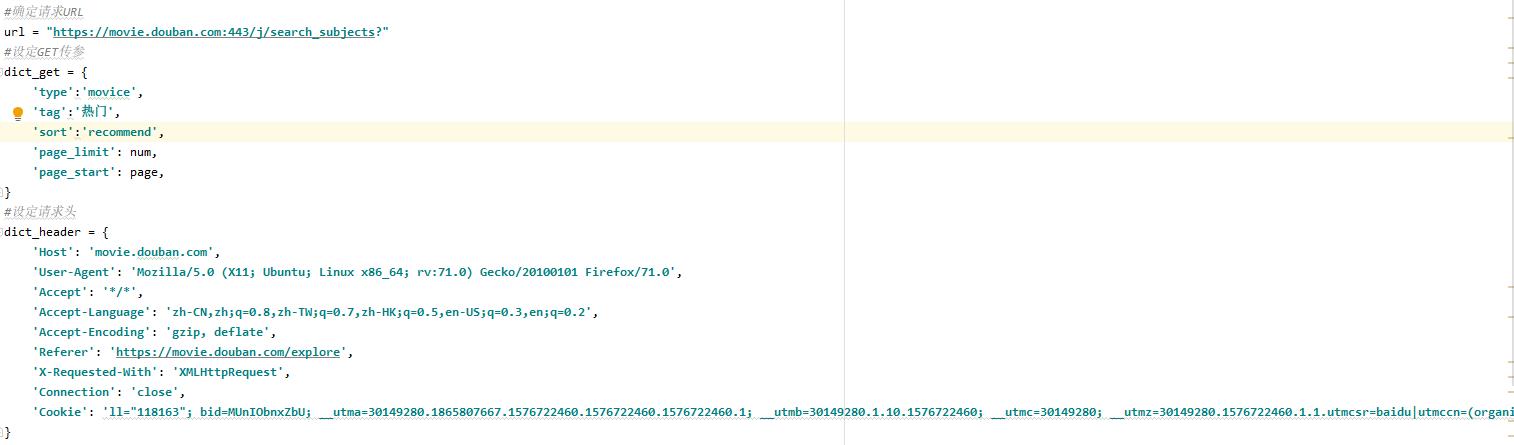
5;拼接URL,构建请求对象,发送请求,输出请求数据
内容总结
以上是互联网集市为您收集整理的Python3---AJAX---爬虫全部内容,希望文章能够帮你解决Python3---AJAX---爬虫所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。