Python爬虫笔记【一】模拟用户访问之Tesseract-ocr验证码训练(5)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python爬虫笔记【一】模拟用户访问之Tesseract-ocr验证码训练(5),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2016字,纯文字阅读大概需要3分钟。
内容图文
")
验证码处理之后就需要对处理的验证码进行识别训练,这里用Tesseract-ocr工具进行识别,用jTessBoxeditor进行训练生成模板。
一,对图片进行处理

利用上一篇代码对图片进行降噪处理,得到较为清晰地图片。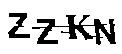
这里需要你在需要登入的网站中提取大量的验证码图片,在获取图片时,查看网站的登入框是否在iframe标签中,已经图片是否有需要点击输入框才会出现,若是如此,可以用selenium中driver来跳转iframe标签,用点击事件来显示验证码,然后再获取src属性进行下载。
二,生成tif文件
在获取一定数量验证码后(储存在images中),打开jTessBoxeditor,Tools>Merge TIFF
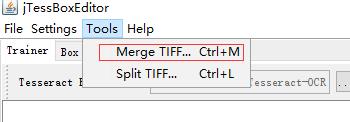
选择之前保存图片的文件,shift将文件全选,注意文件显示的格式
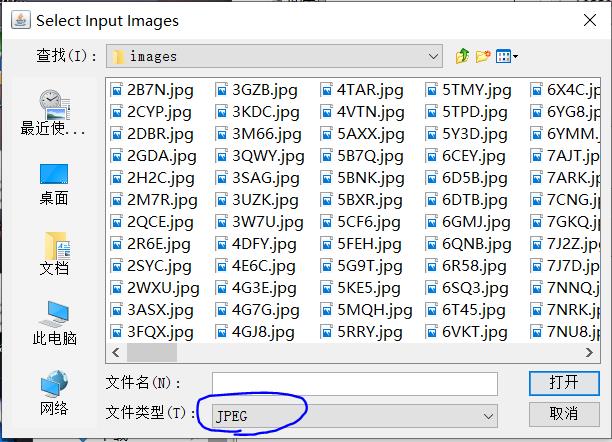
之后选择生成fift路径以及设置名称此处名称要设置为这样的格式[lang].[fontname].exp[num].tif
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
三,生成box文件
这样遍将多个jpg文件合成一个tif文件(可能显示的是一个验证码),然后我们需要利用tif文件来生成box文件。
再打开jTessBoxEditor(如果之前有其他好点的模板就选择其他的,这样自动识别的会多一点,省之后的人力)。
这一步之后就会在 tif 文件目录下生成一个box文件,在jTessBoxEditor中打开(如图 ↓ )
四,调整位置
如果模板较好的话会出现这样的文件(也许位置可能没有识别的这么准,那个就需要人工调节,记得保存,下面可以翻页)
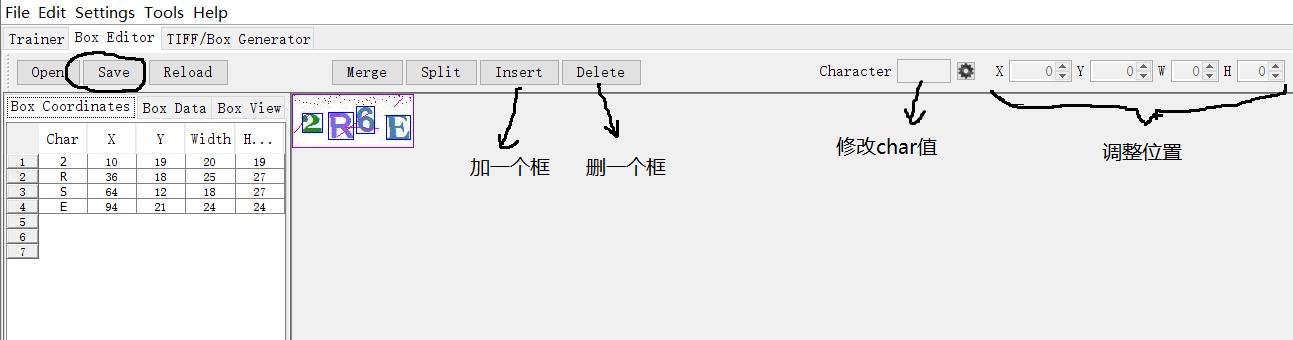
也有可能是这样
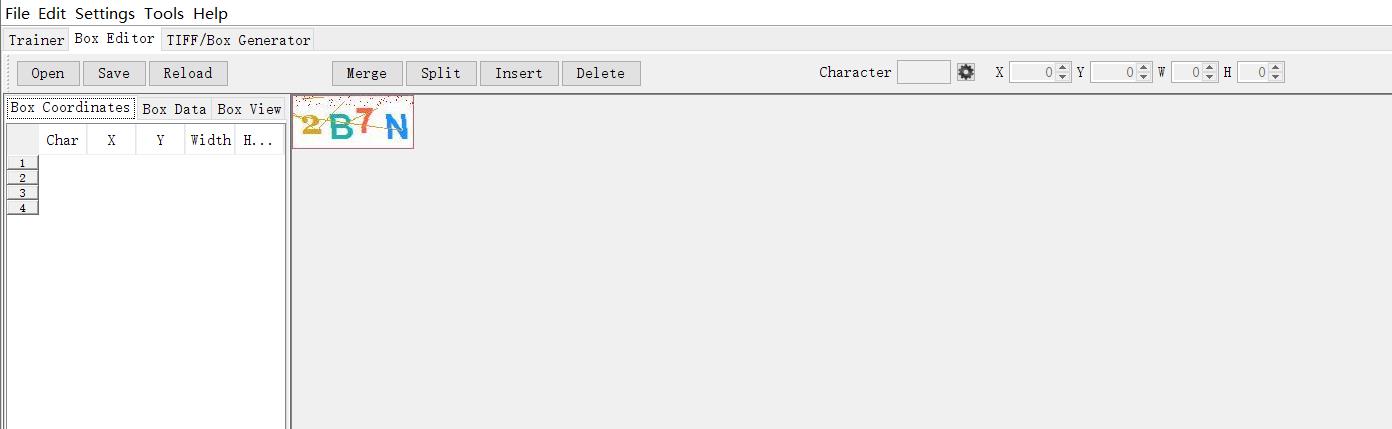
如果是这样的话,你需要用文本方式打开box文件(六列分别对应,值,位置*4,页码值-1),我们需要创建的1~7页的那四行,随便找四行复制一下,然后改一下页码,没有框的几个验证码有了,然后再调整位置。(注意最后的一列为 页码数-1 )

在调整完所有验证码后,在tif文件目录下建立一个新建名为下xxx.font_properties的文本文件(xxx与自定义语言名称相同)内容为 font 0 0 0 0 0之后再去txt后缀
五,训练
这样 tif,box,font_properties文件都有了,就可以生成模板了

训练完之后就在tif文件下生成了tessdata文件夹,里面便是训练完成模板mob.traineddata,将模板移动到Tesseract—ocr>tessdata目录下,这样便可以用Tesseract-ocr识别验证码了
查阅过的博客:
《Python Tesseract识别验证码》:https://blog.csdn.net/u011457798/article/details/84063963
《使用Tesseract破解验证码并训练字库的方法》:https://blog.csdn.net/makesibushuohua/article/details/52058310
内容总结
以上是互联网集市为您收集整理的Python爬虫笔记【一】模拟用户访问之Tesseract-ocr验证码训练(5)全部内容,希望文章能够帮你解决Python爬虫笔记【一】模拟用户访问之Tesseract-ocr验证码训练(5)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。