首页 / JAVA / MapReduce Java练习
MapReduce Java练习
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了MapReduce Java练习,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含8931字,纯文字阅读大概需要13分钟。
内容图文

MapReduce Java练习
练习用到的文件
链接:https://pan.baidu.com/s/1dgVA5y_cSXaNjj0BhfJvtA
提取码:48l1
log4j.properties文件:(这个之前貌似没有给吧)
链接:https://pan.baidu.com/s/1H3Rw1PqhptJC8cNPPixmUg
提取码:28fl
理解了一些基本概念,这里像之前安装eclipse时玩一个hello world,当然不是用MapReduce输出一个hello word,而是做一个简单的单词统计。
1. 首先添加pom依赖
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<!--练习MapReduce的时加入的pom依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<!-- 用于对maven工程打jar包的插件 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<!--这里是主类的路径,可以选中主类的类名然后右键选择copy reference 复制路径-->
<mainClass>com.chinasofti.mapreducepractice.WordCountDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!-- 指定java编译器的版本是1.8 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
2. 编写Mapper类
package com.chinasofti.mapreducepractice;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 这里就是mapreduce程序 mapper阶段业务逻辑实现的类
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:表示mapper数据输入的时候key的数据类型,在默认的读取数据组件下,叫InputFormat,它的行为是一行一行的读取待处理的数据
* 读取一行,返回一行给我们的mr程序,这种情况下 keyin就表示每一行的起始偏移量 因此数据类型是Long
* VALUEIN:表述mapper数据输入的时候value的数据类型,在默认的读取数据组件下 valuein就表示读取的这一行内容 因此数据类型是String
* KEYOUT 表示mapper数据输出的时候key的数据类型 在本案例当中 输出的key是单词 因此数据类型是 String
* VALUEOUT表示mapper数据输出的时候value的数据类型 在本案例当中 输出的key是单词的次数 因此数据类型是 Integer
* 这里所说的数据类型String Long都是jdk自带的类型 在序列化的时候 效率低下 因此hadoop自己封装一套数据类型
* long---->LongWritable
* String-->Text
* Integer--->Intwritable
* null-->NullWritable
*
* mapz这个类中包含了类似静态代码块的方法,
* 即setup() 方法在整个mapper阶段开始前执行一次,
* cleanup() 方法在mapper阶段执行完后执行一次
* 这里没有用到,为了避免后面用的时候忘记,标注一下。
*
* 常用的map方法:每传入一个键值对就调用一次。
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* 这里就是mapper阶段具体的业务逻辑实现方法 该方法的调用取决于读取数据的组件有没有给mr传入数据
* 如果有的话,每传入一个《k,v》对,该方法就会被调用一次
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到传入进来的一行内容,把数据类型转化为String
String line = value.toString();
//将这一行内容按照分隔符进行一行内容的切割,切割成一个单词数组
String[] words = line.split(" ");
//遍历数组,每出现一个单词就标记一个数字1:<单词,1>,
// 其实这里是可以将每行的相同的单词进行一个统计后再输出的,后续这里用combiner进行优化,所以就先这样吧
for (String word:words){
//使用mr程序的上下文context 把mapper阶段处理的数据发送出去
context.write(new Text(word),new IntWritable(1));
}
}
}
3. 编写Reducer类
package com.chinasofti.mapreducepractice;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 这里是MR程序 reducer阶段处理的类
* KEYIN:就是reducer阶段输入的数据key类型,对应mapper的输出key类型 在本案例中 就是单词 Text
* VALUEIN就是reducer阶段输入的数据value类型,对应mapper的输出value类型 在本案例中 就是单词次数 IntWritable
* KEYOUT就是reducer阶段输出的数据key类型 在本案例中 就是单词 Text
* VALUEOUTreducer阶段输出的数据value类型 在本案例中 就是单词的总次数 IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* 这里是reduce阶段具体业务类的实现方法
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
* reduce接收所有来自map阶段处理的数据之后,按照key的字典序进行排序
* <hello,1><hadoop,1><spark,1><hadoop,1>
* 排序后:
* <hadoop,1><hadoop,1><hello,1><spark,1>
*
*按照key是否相同作为一组去调用reduce方法
* 本方法的key就是这一组相同kv对的共同key
* 把这一组所有的v作为一个迭代器传入我们的reduce方法
*
* <hadoop,[1,1]>
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历一组迭代器,把每一个数量1累加起来就构成了单词的总次数
for(IntWritable value:values){
count +=value.get();
}
//把最终的结果输出
context.write(key,new IntWritable(count));
}
}
4.1 编写Driver类(这个是运行在HDFS集群)
5. 将编写好的程序打好jar包上传值Hadoop
运行在集群上,需要将编写好的代码打包上传到集群上。
我们之前在pom文件中有添加打jar包的插件,在IDEA上,有辅助我们打Jar包的插件,选择右边栏的maven,然后选择lifecycle中的package(双击)。

6. 上传jar包到集群
在上传到集群之前我们需要将jar包上传到Linux系统上,使用之前安装好的插件lrzsz进行上传,
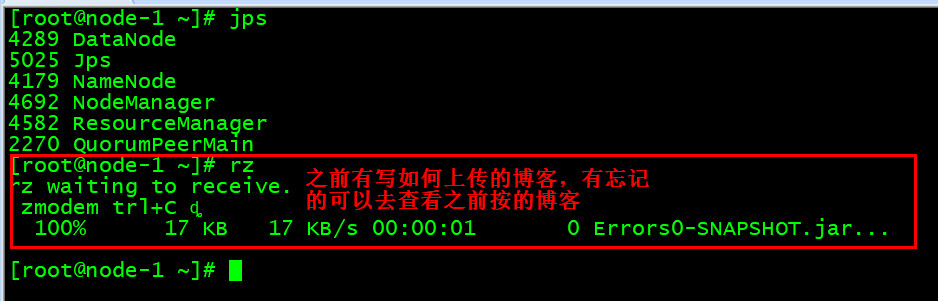
在把jar包上传到Hadoop上运行之前,我们先把测试文件搞定。
先将测试文件上传到Linux系统上。这个测试文件我是复制Hadoop和Hive官网上的一段好去除符号。
现在文件到了Linux系统上,在我们将文件上传到Hadoop集群上之前,需要先建立输入文件夹。
使用命令:hadoop fs -mkdir -p /wordcount/input 命令在Hadoop上建立一个文件夹。通过在web窗口我们可以查看到建立好的文件夹(这里截图的时候我已经将文件上传上去了)。

然后使用命令hadoop fs -put /root/Hadoop-introduction.txt /wordcount/input ,
hadoop fs -put /root/Hive-introduction.txt /wordcount/input 上传测试文件到Hadoop集群上的input文件夹。
还可以使用一条命令搞定:
hadoop fs -put Hadoop-introduction.txt Hive-introduction.txt /wordcount/input
注意这里上传了两个文件。结果见上图。
7. 在Hadoop上运行jar包
要在Hadoop集群上运行这个jar包,只需要在集群的任意一个节点上用Hadoop命令进行启动:
hadoop jar my-bigdata-practice-1.0-SNAPSHOT.jar

当命令行再次出现时,表示运行结束

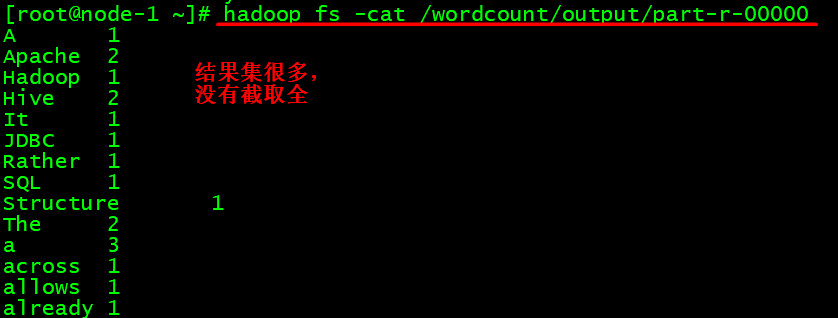
8. 查看运行结果
结果我们可以在HDFS的web界面查看到,也可以直接在去cat查看。

将结果集下载下来即可查看。(至于对错,额没这欲望去数单词,不过可以自己建一个小的数据集来测试)
4.2 Driver类(这个是运行在本地,主要用于Debug)
运行在本地上的程序不需要打jar包,但是输出文件夹还是不能存在,否则会报错。
为了看到运行,我们引入log4j.properties 来打印日志。
package com.chinasofti.mapreducepractice;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 这个类就是mr程序运行时候的主类,本类中组装了一些程序运行时候所需要的信息
* 比如:使用的是那个Mapper类 那个Reducer类 输入数据在那 输出数据在什么地方
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
//通过Job来封装本次mr的相关信息
Configuration conf = new Configuration();
// conf.set("mapreduce.framework.name","local");
Job job = Job.getInstance(conf);
//指定本次mr job jar包运行主类
job.setJarByClass(WordCountDriver.class);
//指定本次mr 所用的mapper reducer类分别是什么
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定本次mr mapper阶段的输出 k v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定本次mr 最终输出的 k v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(3);
//如果业务有需求,就可以设置combiner组件
job.setCombinerClass(WordCountReducer.class);
//指定本次mr 输入的数据路径 和最终输出结果存放在什么位置
FileInputFormat.setInputPaths(job,"D:\\Practice_File\\hadoop_practice\\MapReduce\\input");
FileOutputFormat.setOutputPath(job,new Path("D:\\Practice_File\\hadoop_practice\\MapReduce\\output"));
// job.submit();
//提交程序 并且监控打印程序执行情况
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
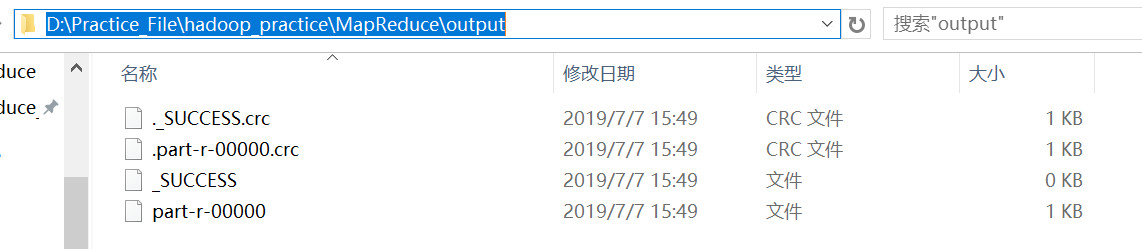
默认的MapReduce配置文件在引入的jar包中。
内容总结
以上是互联网集市为您收集整理的MapReduce Java练习全部内容,希望文章能够帮你解决MapReduce Java练习所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。