Python网络爬虫-模拟Ajax请求抓取微博
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python网络爬虫-模拟Ajax请求抓取微博,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4041字,纯文字阅读大概需要6分钟。
内容图文

Python模拟Ajax请求
有时候我们在用requests抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果并没有。这是因为requests获取到的都是原始的HTML静态文档,而浏览器中的页面则是经过javaScript处理数据后生成的结果,这些数据的来源有很多种,可能是通过Ajax加载的,经过JS生成等。
Ajax:全称是Asynchronous JavaScript and XML,即异步的JavaScript和XML。它能够保证在页面不被刷新、页面链接不改变的情况下刷新并展示数据。比如我们在刷微博的时候,微博有下滑查看更多内容,一直下滑会出现一个加载的动画,不一会儿就继续出现新的微博内容,这就是Ajax加载的过程。在这个过程中,页面实际上利用Ajax请求在后台与服务器进行了数据交互,在获取数据之后再利用JavaScript改变网页,这样网页内容就会更新了。
下面利用Ajax请求抓取微博的内容。
1.目标
抓取新浪微博个人首页发表的个人微博数据,如微博内容、点赞、评论和转发数量等。
2.分析
打开Chrome,输入https://m.weibo.cn/u/2695482785,并下滑拉倒底部,查看请求的发送过程:
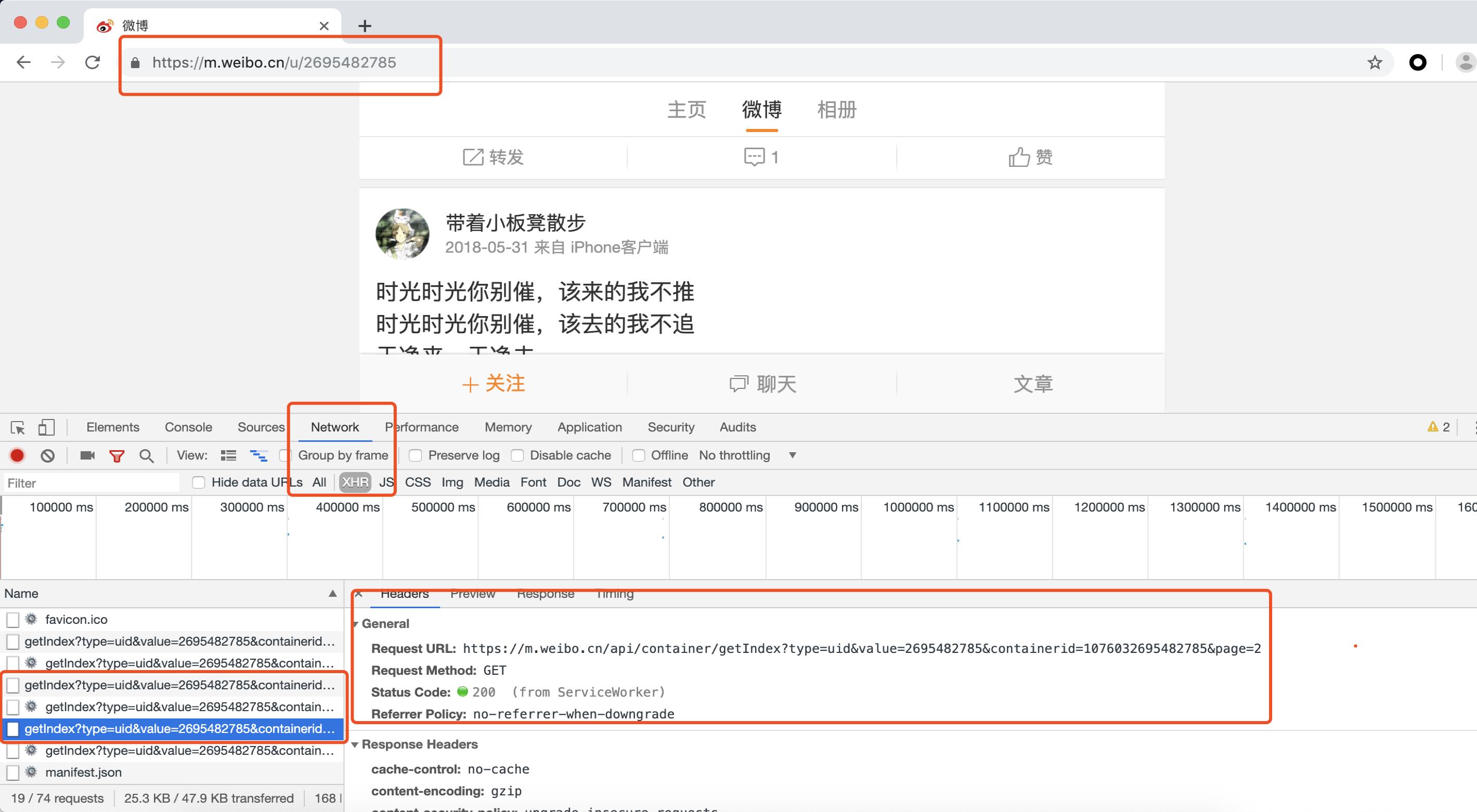
如上图所示,初次进去,然后点开查看请求Network,分别查看XHR(是Ajax请求的方式),分别查看Headers和preview以及Response。
分析结果:
- 请求URL:https://m.weibo.cn/api/container/getIndex?type=uid&value=2695482785&containerid=1076032695482785&page=2
- 请求方式:GET
- 请求头:详见Request Headers
- 请求参数:type、value、containerid和page
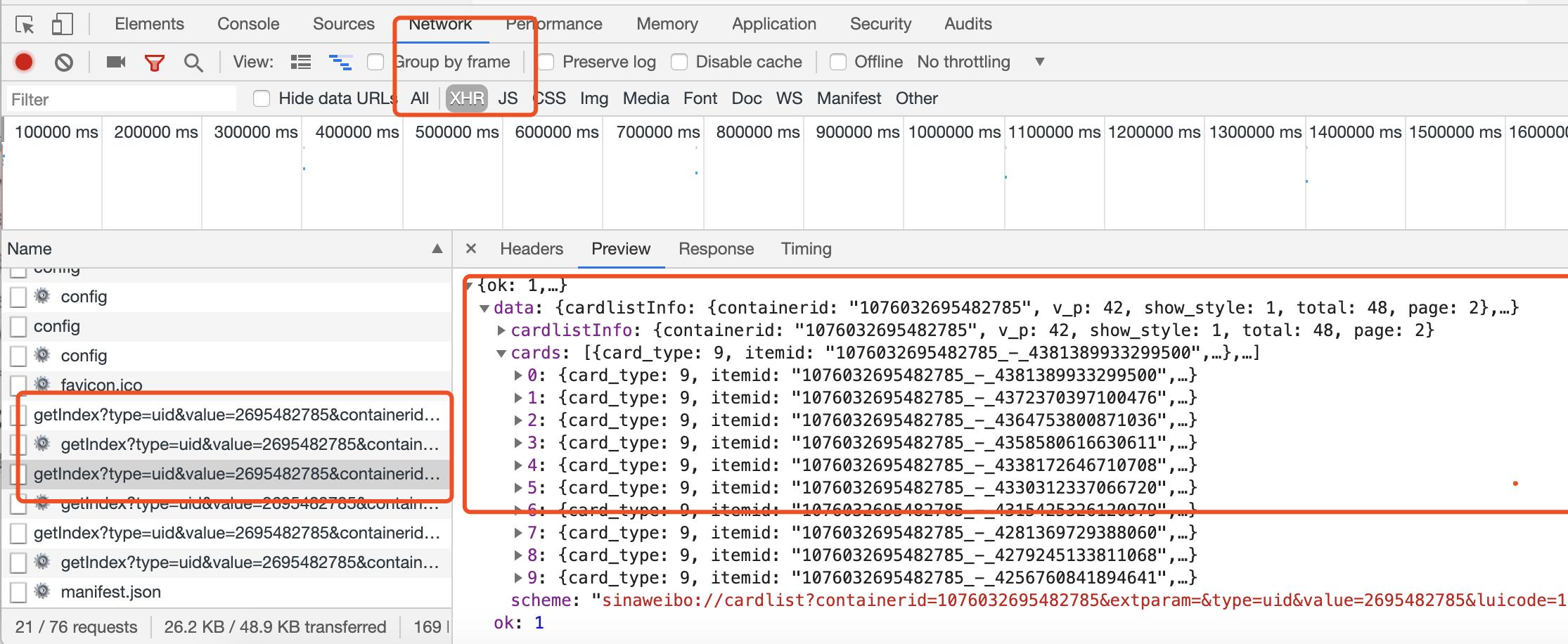
请求的响应分析:
如上图所示,请求的响应内容是一个json格式的数据,点开data关键字下并点开cards目录,然后点开具体内容,里面有个mlog字段,然后展开,可以发现正是微博的一些信息,比如attitudes_count(点赞数量),comments_count(评论数量),reposts_count(转发数量),text(微博正文)等。
因此,我们请求一次接口,就可以得到10条微博,而请求的参数只需要改变page参数即可。
3.解析响应内容
获取json数据后,我们可以查找data关键字来获取其下的具体内容,然后获取cards关键字下的具体内容,通过解析cards下每个item具体的内容来提取我们想要的数据,因此解析json的代码如下:
def parse_page(json):
if json:
items = json.get('data').get('cards') # 获取到cards内容是一个item列表
for item in items: # 循环列表提取数据
item = item.get('mblog')
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = item.get('text')
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo # 返回一个weibo的map
4.整体代码
# -*- coding: utf-8 -*-
# @Time : 2019-07-12 21:47
# @Author : xudong
# @email : dongxu222mk@163.com
# @Site :
# @File : ajaxTest.py
# @Software: PyCharm
from urllib.parse import urlencode
import requests
import json
# 请求的url
base_url = "https://m.weibo.cn/api/container/getIndex?";
# 构造请求头
headers = {
'Host' : 'm.weibo.cn',
'Referer' : 'https://m.weibo.cn/u/2695482785',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36',
'X-Requested-With' : 'XMLHttpRequest'
}
# 获取每一页的请求数据返回的是json格式
def get_page(page):
params = {
'type' : 'uid',
'value' : '2695482785',
'containerid' : '1076032695482785',
'page' : page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
print(type(response))
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
# 解析每一页的json数据,并返回一个weibo的map类型数据
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = item.get('text')
print(type(item.get('text')))
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
# 将解析完的数据写入文件
def write_file(content):
with open('weibo1.txt', 'a' ,encoding='utf-8') as file:
file.write(content)
if __name__ == '__main__':
for page in range(3): # 只爬取了三页
json1 = get_page(page)
results = parse_page(json1)
for result in results:
print(result)
write_file(json.dumps(result, ensure_ascii=False) + '\n')
当运行后,能够在当前的目录中看到weibo1.txt的结果并有如下的数据则表面模拟Ajax请求抓取微博成功,目标达成。
当然可以用自己的微博uid去试试啊~~~

内容总结
以上是互联网集市为您收集整理的Python网络爬虫-模拟Ajax请求抓取微博全部内容,希望文章能够帮你解决Python网络爬虫-模拟Ajax请求抓取微博所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。